
\color{green}{<–画图不易,点下这里赞一下吧}
第 k 个插入的元素在哪里?
在本道题目中,有两个问题:
删除第 k 个插入的数后面的数
在第 k 个插入的数后插入一个数
先解释一下什么叫第k个插入的元素:
- 把插入操作按先后排序,第 k 次执行插入操作的那个元素。
- 并不是链表中从前往后数第 k 个元素。
在链表中删除指针指向的元素的后一个元素,或者在指针指向的某个元素后面插入一个新元素是很容易实现的。
所以,只要弄明白第 k 个插入的数的指针在哪里,这两个问题就很容易解决。
来分析一下插入操作:
- 链表为空的时候:idx 的值为 0,
- 插入第一个元素 a 后:e[0] = a, idx 的值变为 1,
- 插入第二个元素 b 后:e[1] = b, idx 的值变为 2,
- 插入第三个元素 c 后:e[2] = c, idx 的值变为 3,
所以: 第 k 个出入元素的索引值 k - 1。
有人会说,如果中间删除了某些元素呢?
在看一下伴随着删除操作的插入:
- 链表为空的时候:idx 的值为 0,
- 插入第一个元素 a 后:e[0] = a, idx 的值变为 1,
- 插入第二个元素 b 后:e[1] = b, idx 的值变为 2,
- 删除第一个插入的元素 a:head 变为 1, idx 不变,依旧为 2。
- 删除第二个插入的元素 b:head 变为 2, idx 不变,依旧为 2。
- 插入第三个元素 c 后:e[2] = c, idx 的值变为 3。
所以删除操作并不改变第 k 个插入元素的索引。
故第 k 个元素的索引一定是 k - 1。
题解:
head 表示头结点,e数组存储元素,ne数组存储下一个节点索引,indx表示下一个可以存储元素的位置索引。
头结点后面添加元素:
-
在e的idx处存储元素e[ide] = x;
-
该元素插入到头结点后面 ne[idx] = head;
-
头结点指向该元素 head = idx;
-
idx 指向下一个可存储元素的位置 idx++。
在索引 k 后插入一个数
-
在e的idx处存储元素e[index] = x
-
该元素插入到第k个插入的数后面 ne[idx] = ne[k];
-
第k个插入的数指向该元素 ne[k] = idx;
-
idx 指向下一个可存储元素的位置 idx++。
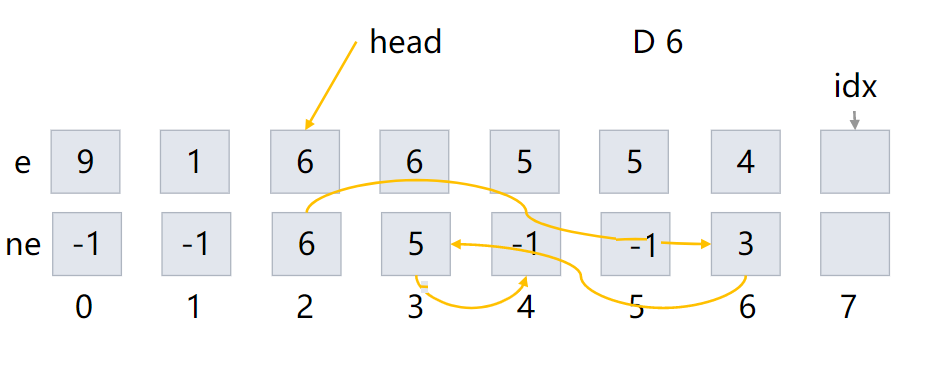
删索引为 k 的元素的后一个元素:
- ne[k] 的值更新为 ne[ne[k]]
画个图
以题目为例:
10
H 9
I 1 1
D 1
D 0
H 6
I 3 6
I 4 5
I 4 5
I 3 4
D 6
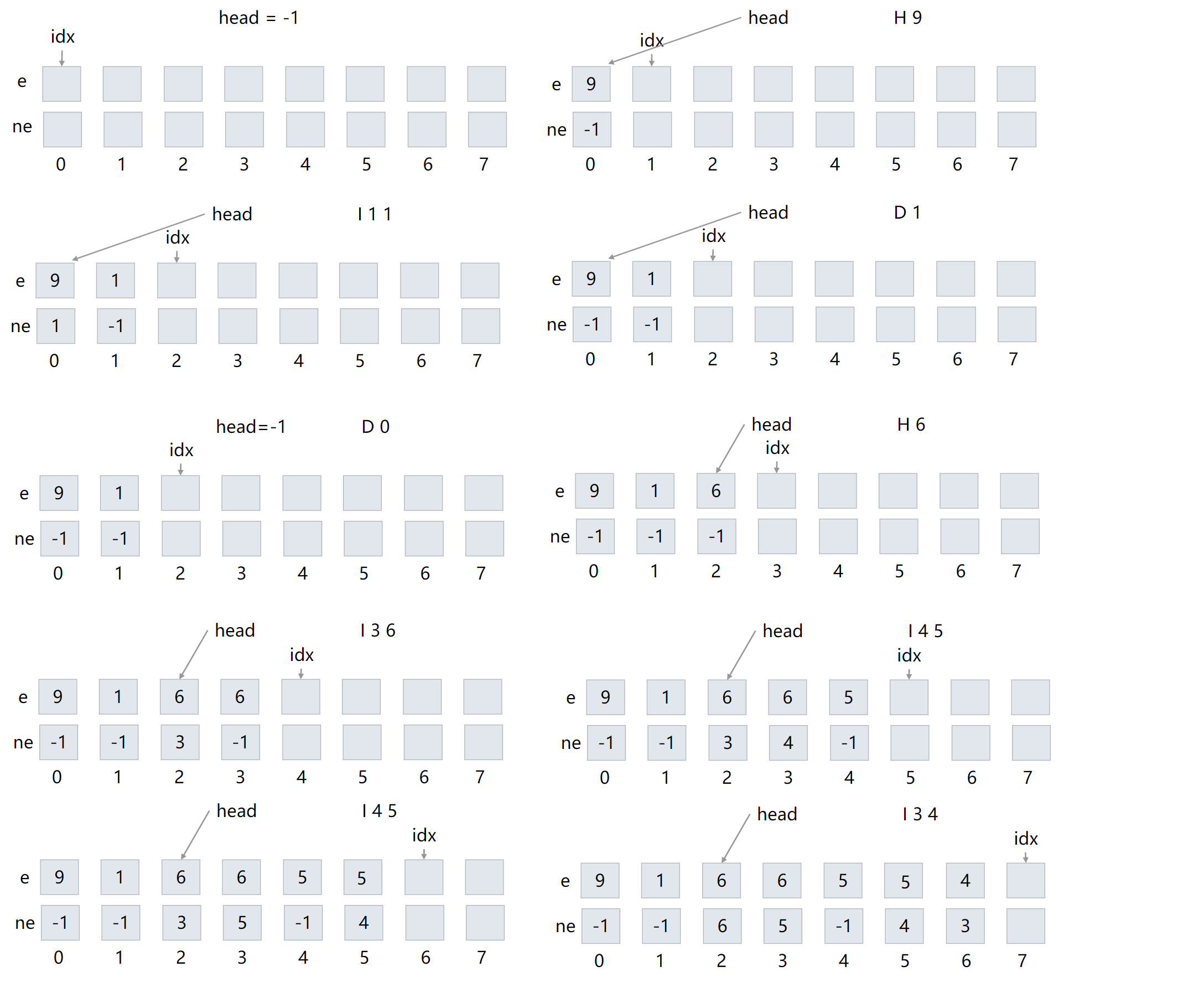
最终结果如下:
#include <iostream>
using namespace std;
const int N = 100010;
int head, e[N], ne[N], idx;
void init()
{
head = -1;
idx = 0;
}
void add_to_head(int x)
{
e[idx] = x, ne[idx] = head, head = idx++;
}
void add(int k, int x)
{
e[idx] = x, ne[idx] = ne[k], ne[k] = idx++;
}
void remove(int k)
{
ne[k] = ne[ne[k]];
}
int main()
{
int m;
cin >> m;
init();
while(m--)
{
char op;
int k, x;
cin >> op;
if(op == 'H')
{
cin >> x;
add_to_head(x);
}
else if(op == 'D')
{
cin >> k;
if(!k) head = ne[head];
else remove(k - 1);//第k个元素对应的索引为k - 1
}
else
{
cin >> k >> x;
add(k - 1, x);//第k个元素对应的索引为k - 1
}
}
for(int i = head; i != -1; i = ne[i]) cout << e[i] << " ";
cout<< endl;
}
为什么不用课本上学的结构体来构造链表??
学过数据结构课的人,对链表的第一反应就是:
链表由节点构成,每个节点保存了 值 和 下一个元素的位置 这两个信息。节点的表示形式如下:
class Node{
public:
int val;
Node* next;
};
这样构造出链表节点的是一个好方法,也是许多人一开始就学到的。
使用这种方法,在创建一个值为 x 新节点的时候,语法是:
Node* node = new Node();
node->val = x
看一下创建新节点的代码的第一行:
Node* node = new Node();,中间有一个 new 关键字来为新对象分配空间。
new的底层涉及内存分配,调用构造函数,指针转换等多种复杂且费时的操作。一秒大概能new1w次左右。
在平时的工程代码中,不会涉及上万次的new操作,所以这种结构是一种 见代码知意 的好结构。
但是在算法比赛中,经常碰到操作在10w级别的链表操作,如果使用结构体这种操作,是无法在算法规定时间完成的。
所以,在算法比赛这种有严格的时间要求的环境中,不能频繁使用new操作。也就不能使用结构体来实现数组。
如果有问题,直接评论,欢迎找bug
完结,撒花。求赞~~

太喜欢海绵宝宝了
感谢大佬,看了你的图解我瞬间懂了,这个ne存的就是下一个节点的下标,而这些下标不一定连续,都是通过ne来索引,idx既能作为一个新元素插入后的下标(e和ne数组可以通过这个下标来对该节点进行访问),也能在插入一个元素时作为一个媒介在数组中以下标形式来为待插节点的e和ne值提供一个坑,这个思想确实很厉害,也很便捷👍
对 我也是死活不理解这个 idx
解决了删除操作会不会影响k的的疑惑,感谢
最后一步的ne[3]不是跳到5吗,为什么是4啊
同问
应该是写错了
写的不错
我帮大家大概总结了评论区的问题,欢迎来访问:
https://blog.csdn.net/m0_74215326/article/details/128770930
y总写的是静态链表,插入元素永远放置在最后,用指针指向要插入的位置
跟着海绵宝宝学算法
海绵宝宝-古希腊掌握写题解的神
最后遍历输出的时候为啥判定是i!=-1啊
因为刚进来的数的索引是-1,所以最后一个数的索引就是-1,所以-1表示搜完了
很详细,终于想通了idx,感谢
每次有不会做的题都是先找海绵宝宝,太强了
解决了我的疑惑。
常看长新系列
海绵宝宝大王
看懂了,谢谢
这代码不全把,如果我连插两个head节点呢,那第一个插入的不应该变成idx=1的节点吗,但这代码删不掉
最后一步不是删除第k个插入后面的数吗,第6个插入不是数组下标为6,ne中的值为4的那个5,他后面那个数不是数组下标为4,ne为-1的那个5吗,为啥删除的都是后面一个5呢,是我理解错了吗
十分感谢,看懂了
求解:stl里面的链表空间是new出来的还是已经分配好的啊