
题目描述
有 N 头牛站成一行,被编队为1、2、3…N,每头牛的身高都为整数。
当且仅当两头牛中间的牛身高都比它们矮时,两头牛方可看到对方。
现在,我们只知道其中最高的牛是第 P 头,它的身高是 H ,剩余牛的身高未知。
但是,我们还知道这群牛之中存在着 M 对关系,每对关系都指明了某两头牛 A 和 B 可以相互看见。
求每头牛的身高的最大可能值是多少。
输入格式
第一行输入整数N,P,H,M,数据用空格隔开。
接下来M行,每行输出两个整数 A 和 B ,代表牛 A 和牛 B 可以相互看见,数据用空格隔开。
输出格式
一共输出 N 行数据,每行输出一个整数。
第 i 行输出的整数代表第 i 头牛可能的最大身高。
数据范围
1≤N≤10000,1≤H≤1000000,1≤A,B≤10000,0≤M≤10000
样例
输入样例:
9 3 5 5
1 3
5 3
4 3
3 7
9 8
输出样例:
5
4
5
3
4
4
5
5
5
差分+区间处理小操作
这道题目一个核心要点,就是如何处理这些特殊的关系,也就是两头牛互相看见。
其实题目中已经告诉我们如何处理,因为我们发现,题目中要求牛的身高最高,那么既然如此,我们完全可以将每一组关系(A,B),看作[A+1,B−1]这组牛身高只比A,B这两头牛矮1.
各位可以画一个图,来更好的理解这道题目。
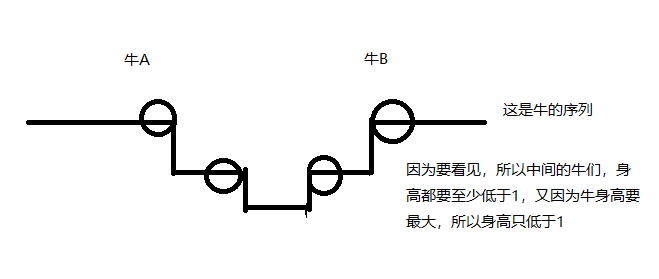
因此我们可以可以利用区间处理小操作,也就是前缀和加差分。设一个数组D,D[i]为比最高牛矮多少,则D[P]=0,那么对于一组关系,我们可以这样操作,D[A+1]–,D[B]++;然后从左到右前缀和,就可以求出矮多少。具体可以看代码实现。
本题数据内部可能重复,要判重,还有[l,r]不一定l<r
C++ 代码
#include <bits/stdc++.h>
using namespace std;
#define ll long long
pair<ll,ll> a[10100];
map<ll,ll> q;
ll n,m,i,j,k,p,h,c[10100],d[10100];
int main()
{
cin>>n>>p>>h>>m;
for (i=1;i<=m;i++)
{
ll A,B;
cin>>A>>B;
if (A>B)
swap(A,B);
if (q[A]!=B)
a[i]=make_pair(A,B),q[A]=B,d[A+1]--,d[B]++;
}
for (i=1;i<=n;i++)
c[i]=c[i-1]+d[i];
for (i=1;i<=n;i++)
cout<<c[i]+h<<endl;
}

这里我终于明白了,所谓的数据有重复是指
``` 3 4
3 4
这种,而不是 ``` 3 4 3 5 3 4所以q[A]!=B能够去重是这个道理
判断重复的地方错了
hack 数据:
应输出:
数据出现(3,7)和(3,5)的时候
q[3]=7和q[3]=5会重复
为啥开long long 兄弟们
同方法ac代码
rd();是快读#include <bits/stdc++.h> #define fi first #define se second #define prf printf #define PII pair<int, int> using namespace std; template <typename T> inline void rd(T &x){ x = 0; bool f = true; char ch = getchar(); while(ch < '0' || ch > '9'){ f = ch == '-' ? false : true; ch = getchar();} while(ch >= '0' && ch <= '9'){ x = (x << 1) + (x << 3) + (ch ^ '0'); ch = getchar();} if(!f) x = -x; } template <typename T, typename ...Args> inline void rd(T &x, Args &...args){ rd(x); rd(args...);} /*****************************/ const int N = 5010; PII ran; map<PII, bool> m; int n, p, h, T; int dif[N]; int main(){ rd(n, p, h, T); dif[1] = h; while(T--){ int l, r; rd(l, r); if(l > r) swap(l, r); auto temp = make_pair(l, r); if(!m[temp]){ m[temp] = true; dif[temp.fi + 1]--; dif[temp.se]++; } } for(int i = 1; i <= n; i++) dif[i] += dif[i - 1]; for(int i = 1; i <= n; i++) prf("%d\n", dif[i]); return 0; }#### ####
#### ####
AC不了
代码ac不了,应该是判重有问题
a[i]=make_pair(A,B),这一句有什么用
题目的测试数据好像有问题吧?@_@
have some problems
first map can
t judge chong fu shu ju second the heightest cow cant modify it valueuse set[HTML_REMOVED] >st
!count ke yi panduan shibushifangwenguo
咋了
他的意思是指 碰到相同的a,但是b不同的情况 map会炸
q[A]!=B 那里不对呀。。
附个数据
7 1 7 4
2 4
2 5
2 4
2 5
那么您这个数据,应该输出什么呢?
7
7
5
6
7
7
您稍等啊,我待会晚上有Acwing直播,现在正在备课。
您稍等啊,我待会晚上有Acwing直播,现在正在备课。
我也感觉不太对,这里到底怎么回事?
少了个7
7
7
5
6
7
7
7
这个判重的确不行,得用set存储pair(A,B)来判断。
how 鬼畜 the STL is!
emm
为什么不用pair在本地dev上可以AC,但是评测WA
用了pair在本地就WA,评测AC...........
不会吧。您是不是编译器版本有点问题呢?
还有您指的AC,是样例通过,还是所有数据都通过呢?
哦好像是编译器出了点问题,谢谢回复 @~@
您客气了,应该的。
为什么q[A]!=B就说明(A,B)没有出现过 q[A]不是会被覆盖吗
一头牛对应一头牛.所有牛的身高不一样.
啊对哦 谢谢
为啥我还是没看懂
a[i]=make_pair(A,B)是什么意思呢
就是一个pair类型,把make_pair里的数分别“移植”到这个pair类型里
我懂啦!题目有个前提,或者说隐含条件,就是对于所有AB区间,他们除了端点之外不可能有交集,所以可以这样直接区间同时减1
讲解有地方错了 是D[A+1]–- 而不是D[A-1]–-
万分感谢!打错了.
这里的a数组是用来做什么的。。。
负责记录
但是好像不要这个也没什么关系..
也是,你可以自行忽略这个多余的东西