
算法分析
树形dp + 分组背包
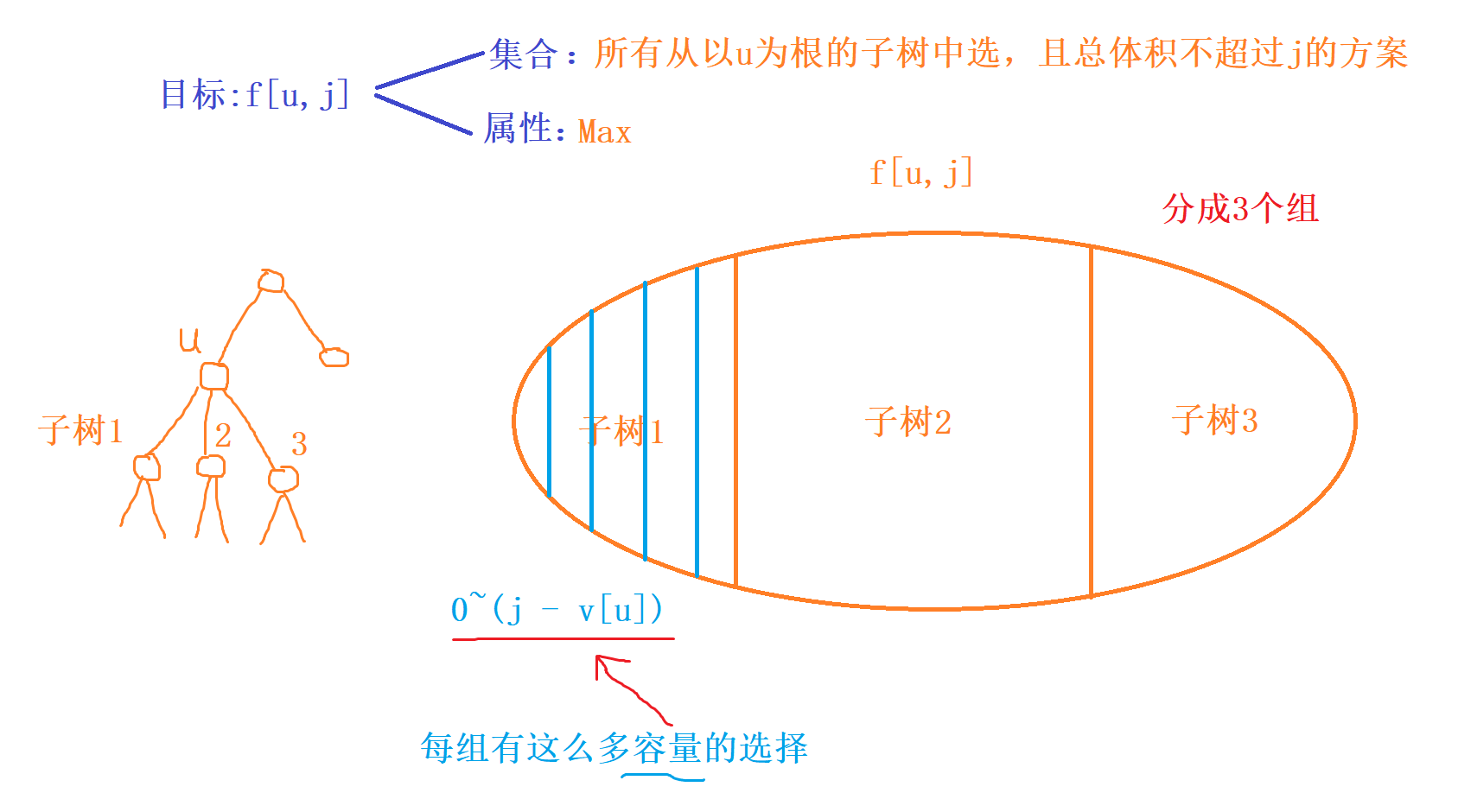
详细代码解释可以参考https://www.acwing.com/solution/acwing/content/5014/
Java 代码
import java.util.Arrays;
import java.util.Scanner;
public class Main{
static int N = 110;
static int n;
static int m;
static int[] h = new int[N];
static int[] e = new int[N];
static int[] ne = new int[N];
static int[] v = new int[N];
static int[] w = new int[N];
static int idx = 0;
static int[][] f = new int[N][N];
static void add(int a,int b)
{
e[idx] = b;
ne[idx] = h[a];
h[a] = idx ++;
}
static void dfs(int u)
{
for(int i = h[u];i != -1;i = ne[i]) // 循环物品组
{
int son = e[i];
dfs(son);
for(int j = m - v[u];j >= 0;j --) // 循环体积
{
for(int k = 0;k <= j;k ++) // 循环决策
{
f[u][j] = Math.max(f[u][j], f[u][j - k] + f[son][k]);
}
}
}
//加上刚刚默认选择的父节点价值
for(int i = m;i >= v[u];i --) f[u][i] = f[u][i - v[u]] + w[u];
for(int i = 0;i < v[u];i ++) f[u][i] = 0;
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
int root = 0;
Arrays.fill(h, -1);
for(int i = 1;i <= n;i ++)
{
v[i] = scan.nextInt();
w[i] = scan.nextInt();
int p = scan.nextInt();
if(p == -1) root = i;
else add(p,i);
}
dfs(root);
System.out.println(f[root][m]);
}
}

不太明白为啥从大到小枚举体积
这是分组背包的一个优化空间的简化过程,分组背包中每次转移只会用到上一层的状态,而且这里是一个树的结构,如果是不优化分组背包的情况下操作很麻烦也很难,需要把每一组每个物品(分配的体积)的价值求出来,再做一次分组背包才能求出 当前u节点中选不超过j的最大价值。因此可以直接顺着优化,直接递归,把要用到的f【son,k】求出来直接用
这个问题确实在这里很值得思考hh,以前我自己潜意识是分组背包问题就顺其自然从大到小,可是这题如果不进行简化分组背包问题,直接去弄很不好弄,因为对应的某一组的某个物品的价值都是需要递归求出来
最近重新看了树形dp发现其实最最原始的定义应该是$f_{(i,k,j)}$,对于以i为根的树,只考虑前k个儿子子树,体积不超过j时的方案。第k个儿子只由第k-1个儿子转移,因而可以滚动数组优化,而倒叙枚举体积就是这个原因!
嗯嗯
赞!
在main函数的for循环里如果是从I = 0 开始到 I < n这样读入数据会对后面哪里造成影响呢,发现如果这样答案就不对了
题目说到,物品的下标范围是 1…N,输入的时候第i编号的物品依赖的父节点是p
f[u][j] = Math.max(f[u][j], f[u][j - k] + f[son][k]);我想问一下这里面f[u][j - k]还能经过f[son][k]经过的点么?点能重复访问么?
每一次递归,返回当前的结果都是之前子节点迭代回来的值,并不包含当前子节点的信息,所以加入当前子节点和之前算出来的树并没有重复的部分,这样理解对吧?感谢
是的,先把子节点的最优值算出来,再返回到当前节点用
谢谢
这个问题的本质是分组背包的状态转移化简过程,所以f【u,j-k】状态中一定不会经过上一组背包的任何一个节点,即f【son,k】