
题目描述
某人读论文,一篇论文是由许多单词组成的。
但他发现一个单词会在论文中出现很多次,现在他想知道每个单词分别在论文中出现多少次。
输入格式
第一行一个整数 N,表示有多少个单词。
接下来 N 行每行一个单词,单词中只包含小写字母。
输出格式
输出 N 个整数,每个整数占一行,第 i 行的数字表示第 i 个单词在文章中出现了多少次。
数据范围
1≤N≤200,
所有单词长度的总和不超过 106。
样例
输入样例:
3
a
aa
aaa
输出样例:
6
3
1
算法
(AC自动机)
对于Trie图,其实最难理解的是它的Fail指针,也就是当前单词的后缀可以匹配的最长前缀,当然这里写的是ne数组,意思是一样的。
类似于下面的这张图示:
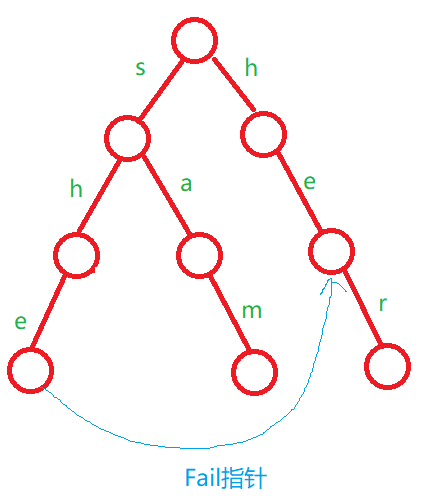
考虑完这个问题之后,我们用题目中的例子画一张图理解一下:

为什么可以这样呢,其实就是做了一个巧妙的转化,我们发现,要找所有单词中某个单词出现的次数,其实就是看在所有的前缀的后缀中某个单词出现的次数,这不就是ne数组的定义吗,问题也就解决了!
时间复杂度
时间复杂度是线性的,和所有单词的总长度有关,也就是O(n)。
参考文献
算法提高课
java 代码
import java.io.*;
class Main{
static int N = 210, M = 1000010;
static int[][] tr = new int[M][26];
static int[] f = new int[M];
static int[] ne = new int[M];
static int[] q = new int[M];
static int[] id = new int[N];
static int idx;
static void insert(String str, int j){
char[] arr = str.toCharArray();
int p = 0;
for(int i=0; i<arr.length; i++) {
int u = arr[i] - 'a';
if(tr[p][u] == 0) tr[p][u] = ++ idx;
p = tr[p][u];
f[p] ++;
}
id[j] = p;
}
static void build() {
int hh = 0; int tt = -1;
for(int i=0; i<26; i++) {
if(tr[0][i] != 0) {
q[++ tt] = tr[0][i];
}
}
while(hh <= tt) {
int t = q[hh ++]; // 这里的t相当于i-1
for(int i=0; i<26; i++){
int c = tr[t][i];
if(c == 0) tr[t][i] = tr[ne[t]][i];
else{
ne[c] = tr[ne[t]][i];
q[++ tt] = c;
}
}
}
}
public static void main(String[] args) throws IOException{
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(in.readLine());
for(int i=0; i<n; i++) {
String cur = in.readLine();
insert(cur, i);
}
build();
for(int i=idx-1; i>=0; i--) f[ne[q[i]]] += f[q[i]];
for(int i=0; i<n; i++) System.out.println(f[id[i]]);
}
}
请问倒数第二个循环为什么是从idx-1开始,我提交从idx开始也是能够ac的,不太明白
队列下标从0开始
从idx + 10 开始也是对的,因为队列是空的,f[0] = f[ne[0]]随便怎么操作都无所谓,反正0表示的是empty string,input里没有,如果输入有empty string,应该会卡。
“因为队列是空的”说的不是很清楚,我是说idx + 10这里的队列没有用过,存的数是0.
这里我就写了个tot + 5: https://www.acwing.com/problem/content/submission/code_detail/8555615/
(我的tot就是idx)