
Trie字符串统计
$trie$树概述
trie树又称字典树,是高效查找和存储字符串的一种数据结构
一般情况只会存储有限少量的字符,$eg:$ 英文小写字母,英文大写字母,阿拉伯数字
存储例子,如图所示
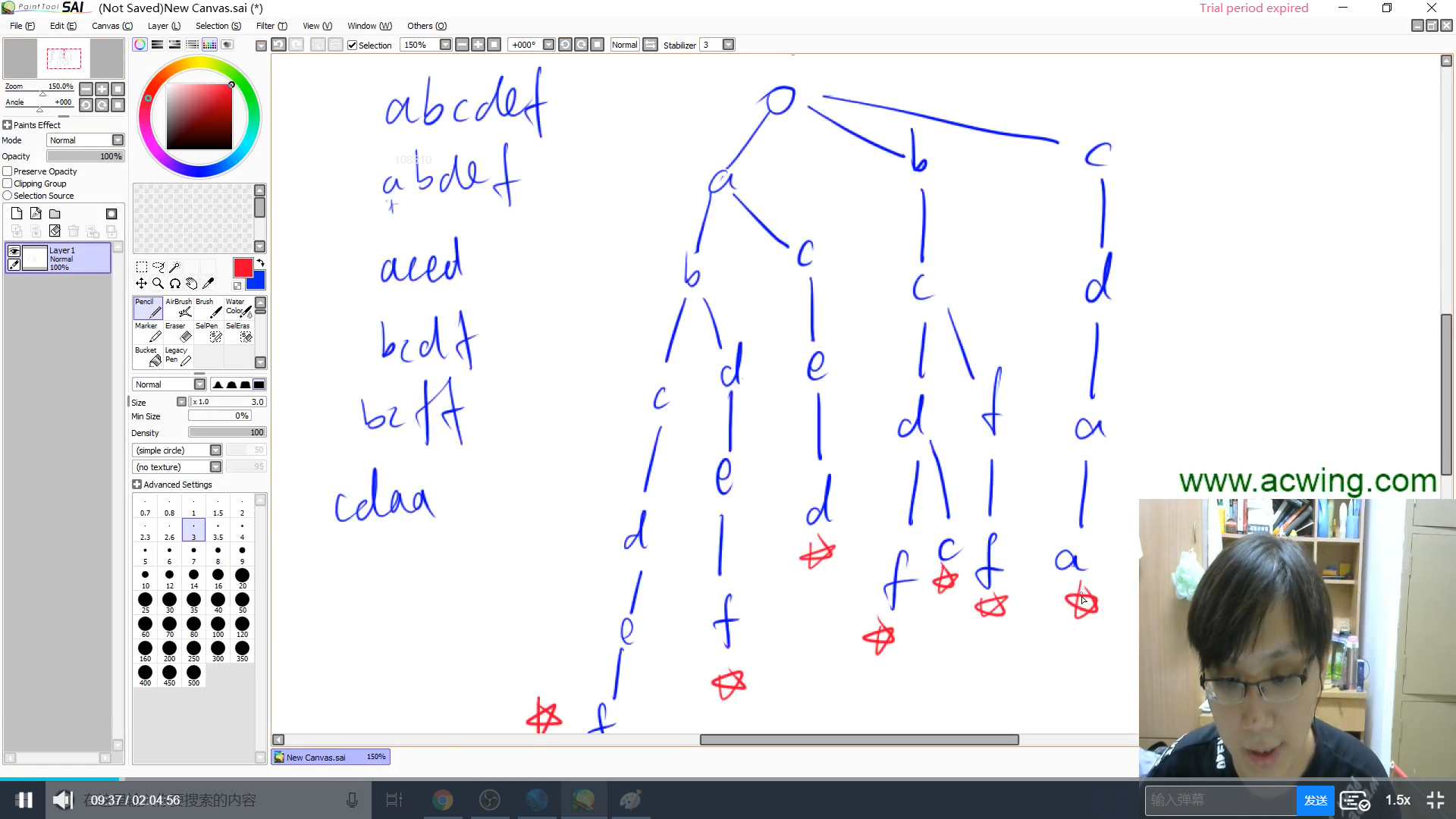
$trie$树的构成
$N$表示要开的总结点数, $M$表示每个结点指针域的数量
$0$号点既是根节点,又是空节点
$son$[ ][ ]存储树中每个节点的子节点,第一维是该节点下标,第二维存储的是指向的下一个结点的下标;这里是数组模拟指针的一个过程
$cnt$[ ]存储以每个节点结尾的单词数量
$idx$存的是已经使用的结点下标,++即可得到可用的下标
int son[N][M], cnt[N], idx;
$trie$的树的基本操作
1. 插入操作
$p$表示当前结点下标
字符串结尾是 \0,当不是结尾的时候就往下走
如果结点不存在,我们就创建一个
结点存在,我们就接着遍历这个结点
字符串走完时,在末位结点$cnt ++ $,表示以该点结尾的单词多了一个
void insert(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;
p = son[p][u];
}
cnt[p] ++ ;
}
2. 查询字符串出现的次数
与插入很相似
不同的是,如果往下挨个字符查找时候
如果这个字符不存在,表示该单词不存在,就返回$0$
遍历完每一个字符后,看看以改点结尾的单词个数,返回$cnt$[ ]
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
本题思路分析
每一个结点有26个指针域,所以$M = 26$,字符串总长度不超过十万,所以总结点数$N = 1e5 + 10$
剩下操作如上
输入的问题:
$scanf$读取字符时候,不会过滤空格和回车,但是读取字符串时候会过滤
$cin$读取字符、字符串也会过滤空格与回车
代码
#include <iostream>
using namespace std;
const int N = 100010;
int son[N][26], cnt[N], idx; //定义trie树的结构
char str[N];//读取的字符串
void insert(char *str)//插入操作
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;
p = son[p][u];
}
cnt[p] ++ ;
}
int query(char *str)//查询操作
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
int main()
{
int n;
scanf("%d", &n);
while (n -- )
{
char op[2];//过滤空格回车、读取字符串
scanf("%s%s", op, str);
if (*op == 'I') insert(str);
else printf("%d\n", query(str));
}
return 0;
}
