
题目描述
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id。
给你数组 watchedVideos 和 friends,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。
Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。
给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按名字字典序从小到大排列。
样例
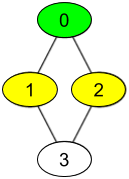
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1
输出:["B","C"]
解释:
你的 id 为 0 ,你的朋友包括:
id 为 1 -> watchedVideos = ["C"]
id 为 2 -> watchedVideos = ["B","C"]
你朋友观看过视频的频率为:
B -> 1
C -> 2
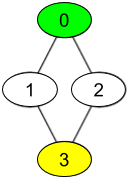
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2
输出:["D"]
解释:
你的 id 为 0,你朋友的朋友只有一个人,他的 id 为 3。
限制
n == watchedVideos.length == friends.length2 <= n <= 1001 <= watchedVideos[i].length <= 1001 <= watchedVideos[i][j].length <= 80 <= friends[i].length < n0 <= friends[i][j] < n0 <= id < n1 <= level < n- 如果
friends[i]包含j,那么friends[j]包含i
算法
(宽度优先搜索 / BFS) $O(n^2 + m \log m)$
- 朋友的关系网络相当于一个无向图,我们从结点
id出发,找距离id为level的点。 - 这可以通过宽度优先搜索来实现。
- 用哈希表,将满足要求的点的视频信息进行统计,然后根据频率为第一关键字,字符串为第二关键字排序。
时间复杂度
- 图的边数为 $O(n^2)$,故宽度优先搜索的时间复杂度为 $O(n^2)$。
- 假设最多一共有 $m$ 个不同的视频,则最终排序输出的时间复杂度为 $O(m \log m)$。
- 总时间复杂度为 $O(n^2 + m \log m)$。
空间复杂度
- 需要额外的 $O(n + m)$ 的空间存储队列和视频统计信息。
C++ 代码
class Solution {
public:
vector<string> watchedVideosByFriends(vector<vector<string>>& watchedVideos, vector<vector<int>>& friends, int id, int level) {
int n = watchedVideos.size();
unordered_map<string, int> fq;
vector<int> dis(n, INT_MAX);
dis[id] = 0;
queue<int> q;
q.push(id);
while (!q.empty()) {
int x = q.front();
q.pop();
if (dis[x] == level) {
for (const auto &v : watchedVideos[x])
fq[v]++;
continue;
}
for (int f : friends[x])
if (dis[f] > dis[x] + 1) {
dis[f] = dis[x] + 1;
q.push(f);
}
}
vector<pair<int, string>> res;
for (const auto &v : fq) {
res.emplace_back(v.second, v.first);
}
sort(res.begin(), res.end());
vector<string> ans;
for (const auto &r : res)
ans.push_back(r.second);
return ans;
}
};
