
算法分析

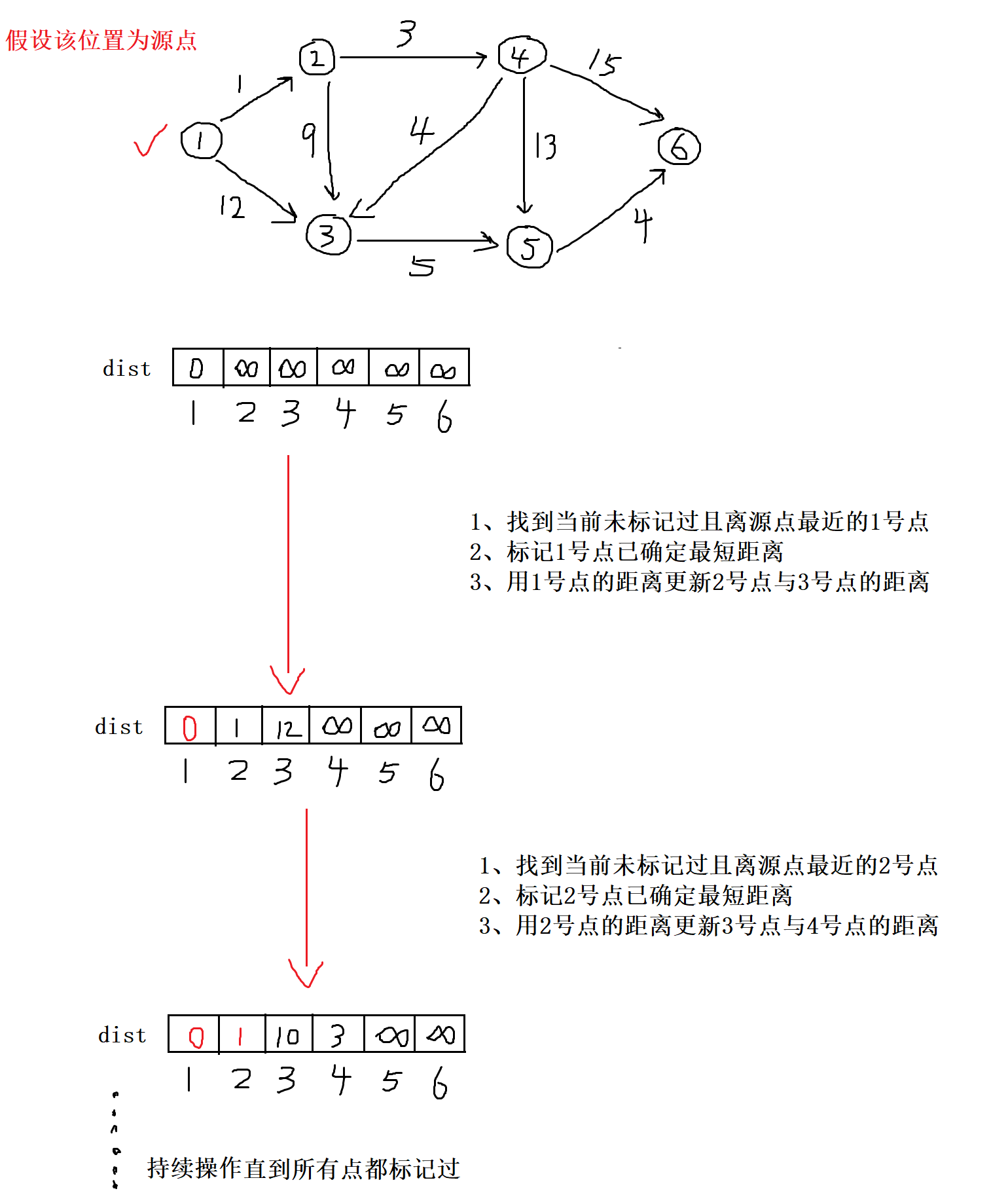
注意:若要求任意点i到任意个点j的最短距离,只需修改dijkstra方法中的起源位置dist[i] = 0,以及返回为dist[j]
时间复杂度 $O(mlogn)$
每次找到最小距离的点沿着边更新其他的点,若dist[j] > distance + w[i],表示可以更新dist[j],更新后再把j点和对应的距离放入小根堆中。由于点的个数是n,边的个数是m,在极限情况下(稠密图$m = \frac{n(n - 1)}{2}$)最多可以更新m回,每一回最多可以更新$n$个点(严格上是n - 1个点),有m回,因此最多可以把$n^2$个点放入到小根堆中,因此每一次更新小根堆排序的情况是$O(log(n^2))$,一共最多m次更新,因此总的时间复杂度上限是$O(mlog((n^2))) = O(2mlogn) = O(mlogn)$
Java 代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.PriorityQueue;
public class Main{
static int N = 100010;
static int n;
static int[] h = new int[N];
static int[] e = new int[N];
static int[] ne = new int[N];
static int[] w = new int[N];
static int idx = 0;
static int[] dist = new int[N];// 存储1号点到每个点的最短距离
static boolean[] st = new boolean[N];
static int INF = 0x3f3f3f3f;//设置无穷大
public static void add(int a,int b,int c)
{
e[idx] = b;
w[idx] = c;
ne[idx] = h[a];
h[a] = idx ++;
}
// 求1号点到n号点的最短路,如果不存在则返回-1
public static int dijkstra()
{
//维护当前未在st中标记过且离源点最近的点
PriorityQueue<PIIs> queue = new PriorityQueue<PIIs>();
Arrays.fill(dist, INF);
dist[1] = 0;
queue.add(new PIIs(0,1));
while(!queue.isEmpty())
{
//1、找到当前未在s中出现过且离源点最近的点
PIIs p = queue.poll();
int t = p.getSecond();
int distance = p.getFirst();
if(st[t]) continue;
//2、将该点进行标记
st[t] = true;
//3、用t更新其他点的距离
for(int i = h[t];i != -1;i = ne[i])
{
int j = e[i];
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
queue.add(new PIIs(dist[j],j));
}
}
}
if(dist[n] == INF) return -1;
return dist[n];
}
public static void main(String[] args) throws IOException{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String[] str1 = reader.readLine().split(" ");
n = Integer.parseInt(str1[0]);
int m = Integer.parseInt(str1[1]);
Arrays.fill(h, -1);
while(m -- > 0)
{
String[] str2 = reader.readLine().split(" ");
int a = Integer.parseInt(str2[0]);
int b = Integer.parseInt(str2[1]);
int c = Integer.parseInt(str2[2]);
add(a,b,c);
}
System.out.println(dijkstra());
}
}
class PIIs implements Comparable<PIIs>{
private int first;//距离值
private int second;//点编号
public int getFirst()
{
return this.first;
}
public int getSecond()
{
return this.second;
}
public PIIs(int first,int second)
{
this.first = first;
this.second = second;
}
@Override
public int compareTo(PIIs o) {
// TODO 自动生成的方法存根
return Integer.compare(first, o.first);
}
}

因此最多可以把n2个点放入到小根堆中,因此每一次更新小根堆排序的情况是O(log(n2))
我想问下这是为啥啊??有无大佬解释一下?
写得真好!!
大佬们 求最长路径怎么改呢
加个负号,spfa跑一遍,输出在带个负号
时间复杂度不应该是O(mlog(n-1))吗,m次循环,每次最多插入n-1条边
查了手册以后发现代码真的很好理解 回来感谢一下大佬
return Integer.compare(first, o.first);重写的compareTo方法有什么作用?上面的优先队列需要比较PIIs的大小,就需要重写compareTo方法
怎么输出最短路的路径呢
在更新一个点到起点距离时,记录下是哪个点更新这个点的,类似于bfs输出路径
大佬问一下,dist数组里面保存的所有数据一定是最小的吗
跑一遍更新一遍距离st已选中的 点 的最短距离
是不是Java写都会超时啊?c++用y总的能过,但是java过不了
不会呀,这里只有bellmam-ford算法会超时
大佬我有个问题堆优化dijkstra能一开始把所有点都入优先队列嘛 emmm……我个人感觉可以0.0但是只能过11个样例
这个问题你大概需要看 dijkstra 的证明过程
因为这是一种贪心的算法,我们利用堆优化,目的是更快地找到 n 个点中 ,距离最近的那个(未被访问过的)
也就是说, 我们保证, 先进队列的点 , 他的距离是更小的 , 比后面的每一个点都更小
而一开始就全部入一遍,就破坏了这种贪心的性质。
这是我的一些理解
一开始把所有点都入优先队列是没有意义的。
因为一开始只有起点的dist是0,其他点的dist都是INF。
这时插入一堆INF根本没有用。
因为当一个点被更新时,优先队列中对应的值并不会被更新。
所以在每个点的dist值变小时,将其现在的状态插入优先队列是比较好的。
并不需要保证先进入队列的距离是最小的,这个是优先队列,会自动进行排序的,始终队头元素是最小的。
所以我觉得从原理上来说可以的。
秒啊%%%
stO Orz
感觉写Java有点像裹脚布…
e[idx] ,w[idx] ,ne[idx] ,h[idx]哪个大佬能告诉我,这几个数组的意思啊,枯了
数组模拟图,看看y总之前的课
这是邻接表的实现,这道题是稀疏图,所以用邻接表。
我懂了,这是模拟邻接表
h[N]为头结点指向下一个结点的指针,e[N]为链表插入的结点,w[N]为权值,ne[N]为该结点指向下一个结点的指针,idx为每条链表现在开发的结点数量
Yes!qvq
谢谢大佬
牛逼
学习了,谢谢xd
感谢大佬
pai数组可以用int数组代替
框框怎么打的
好厉害好厉害