
最近在补全提高课所有题目的题解,宣传一下汇总的地方提高课题解补全计划
题目描述
给定一个 8×8 的棋盘,棋盘的每个小方格都有一个权值 wx,y
每次我们可以对棋盘进行一次 横 或 竖 切,将 棋盘 分成两块矩形的 子棋盘
分割完一次后,我们可以选择两个 子棋盘 中的一个再继续 递归 操作
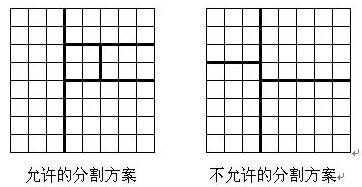
可以发现题目中给的这个图片,右边这个并不是递归下去做的:他对第一次分割的两个矩形又分别进行了分割(题目要求我们只能保留一个继续分割)
现需要把棋盘按照上述分割方案,分成 n 块(n−1 次划分操作)
求一个划分方案,使得各子棋盘的 总分的均方差最小
分析
本题如果用 动态规划 来分析,状态表示要至少开5维,记录分割操作的阶段,以及当前的棋盘状态
我这里直接贴出 闫氏DP分析法
闫氏DP分析法
状态表示 fk,x1,y1,x2,y2—集合:
当前已经对棋盘进行了 k 次划分,且 k 次划分后选择的棋盘是 左上角为 (x1,y1),右下角为 (x2,y2)
状态表示 fk,x1,y1,x2,y2—属性:
划分出来的 k+1 个子矩阵的 nσ2最小(下面给出了这样定义的原因)
状态计算 fk,x1,y1,x2,y2:

这里关于 集合的属性 需要一点变化,直接使用 标准差 作为属性,在进行状态转移的时候不好计算
我们把标准差做出如下变化:
nσ2=n∑i=1(xi−¯X)2=(x1−¯X)2+(x2−¯X)2+⋯+(xn−¯X)2
由于 σ 与 nσ2 的单调性相同,要求 σ 最小,就相当于 nσ2 最小
而转化为 nσ2 后,对于子状态,我们就可以直接进行 加法运算 来转移了(原来套着根号很难处理)
记忆化搜索
本题有这明显的 分治 引导,即给定一个初始的棋盘,然后我们选择进行分割
分割完后,选择保留一个棋盘,然后对另一个棋盘继续进行分割
直到分割次数达到上限 n−1
考虑一下直接递归操作的时间复杂度:O((16 n)×n!)
这是一个排列数,计算方法很简单,每轮会使用一条分割线,且每条分割线在一个方案里仅能使用一次
不难发现,递归操作会有很多冗余的重复计算,于是我们可以采用 记忆化搜索 进行优化
fk,x1,y1,x2,y2 表示对棋盘进行了 k 次划分,且 k 次划分后选择的棋盘是 左上角为 (x1,y1),右下角为 (x2,y2)
这一步分析就有点雷同于上面的 DP 了
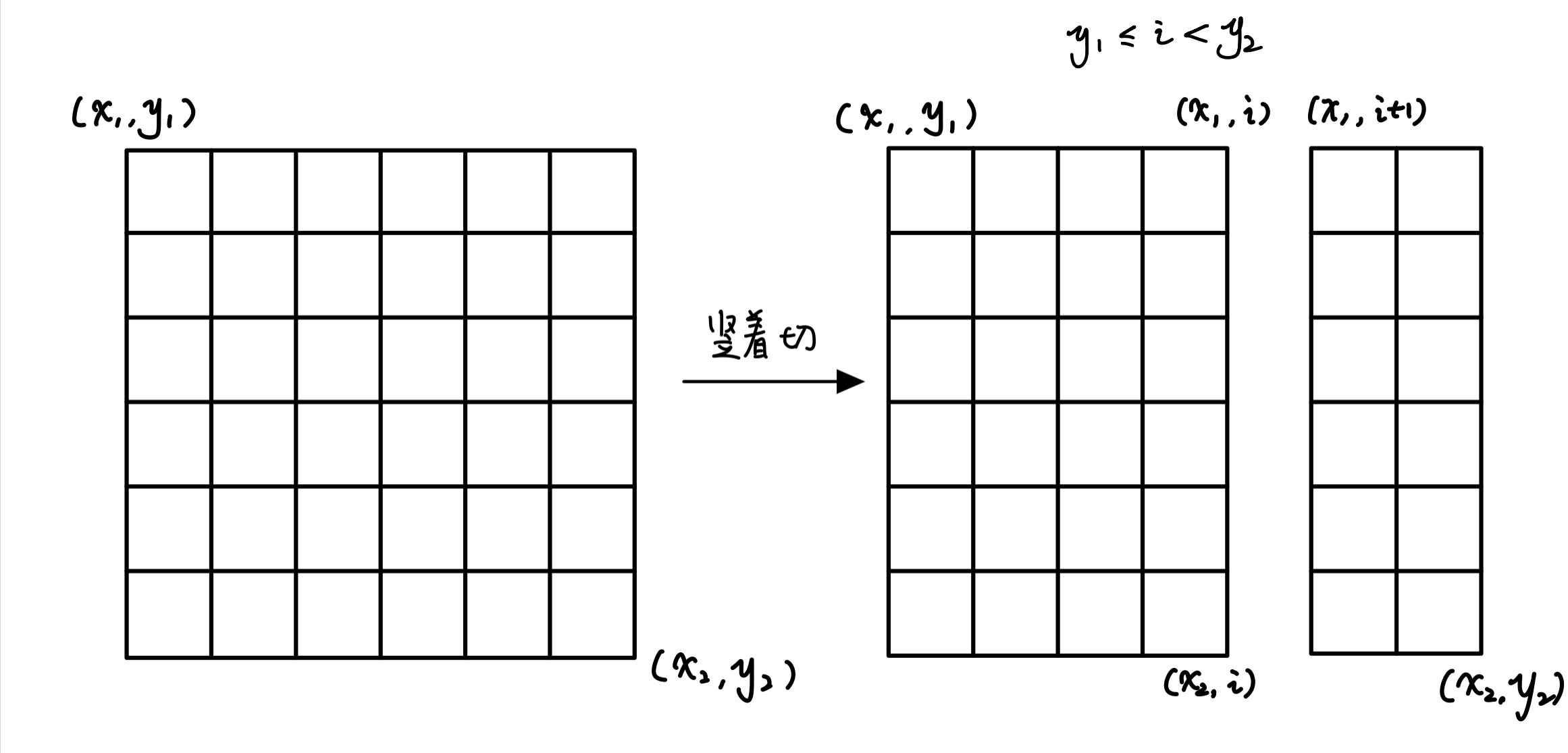
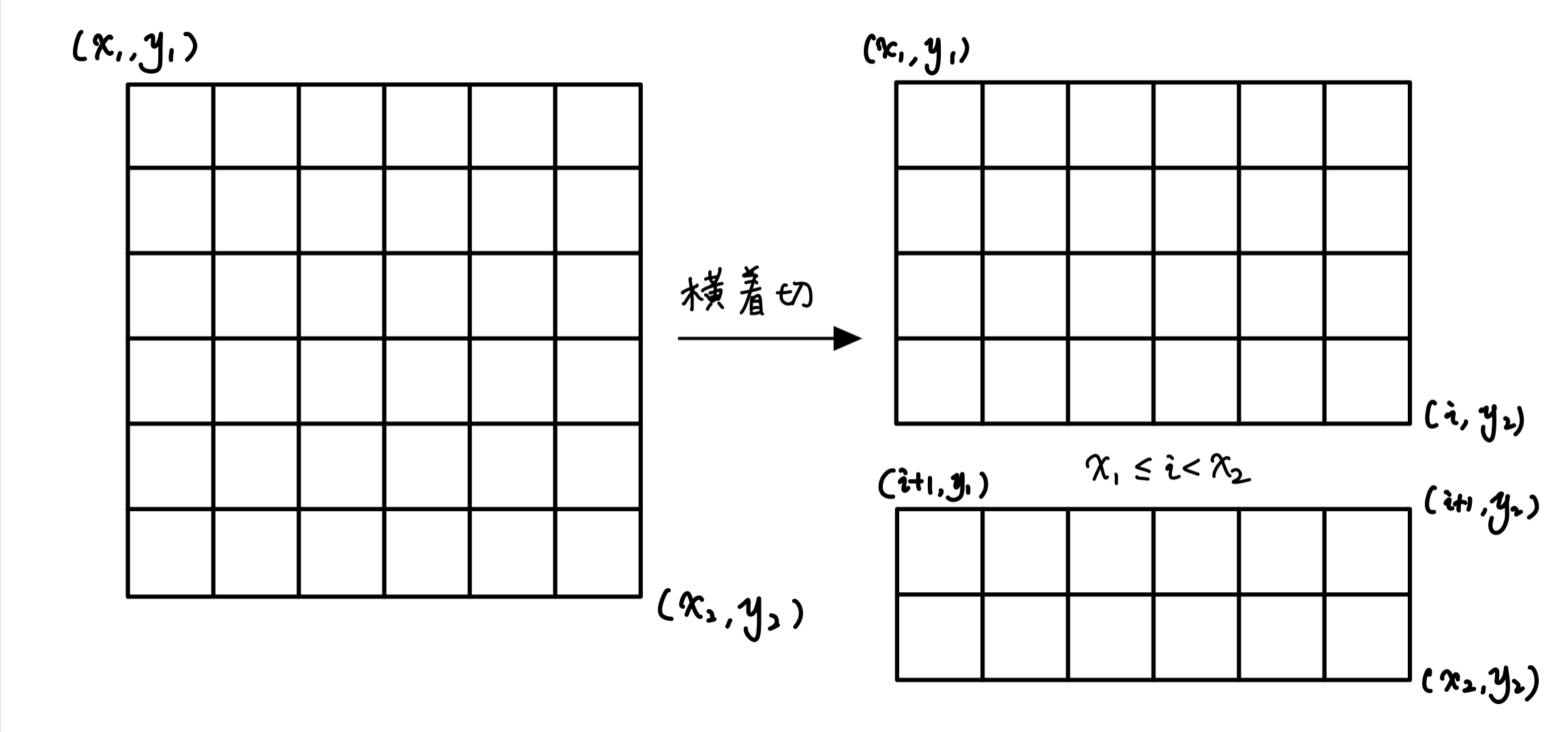
关于如何枚举矩阵的分割(会的可以直接跳过)
由于我们这里记录矩阵的状态是通过他的 对角顶点 记录的,因此分割是我们也可以通过枚举对角顶点完成分割
如下图所示:
竖着切:
横着切:
Code (记忆化搜索)
由于会频繁地计算某个矩阵的方差,因此我们需要先预处理出前缀和,保证计算方差的时间复杂度为 O(1)
时间复杂度 :O(n5)
我这里 阶段定义 的含义和 y总 是反过来的,读者注意区分两者的不同
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 16;
int n, m = 8;
int s[N][N];
double f[N][N][N][N][N];
double X;
double get(int x1, int y1, int x2, int y2) //求该矩阵的 n\sigma^2
{
double delta = s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1];
delta = delta - X;
return delta * delta;
}
double dp(int k, int x1, int y1, int x2, int y2)
{
if (f[k][x1][y1][x2][y2] >= 0) return f[k][x1][y1][x2][y2]; //记忆化搜索
if (k == n) return f[k][x1][y1][x2][y2] = get(x1, y1, x2, y2); //更新初始状态
double t = 1e9; //初始化为无穷大
for (int i = x1; i < x2; i ++ ) //横着切
{
t = min(t, dp(k + 1, x1, y1, i, y2) + get(i + 1, y1, x2, y2));
t = min(t, dp(k + 1, i + 1, y1, x2, y2) + get(x1, y1, i, y2));
}
for (int i = y1; i < y2; i ++ ) //竖着切
{
t = min(t, dp(k + 1, x1, y1, x2, i) + get(x1, i + 1, x2, y2));
t = min(t, dp(k + 1, x1, i + 1, x2, y2) + get(x1, y1, x2, i));
}
return f[k][x1][y1][x2][y2] = t;
}
int main()
{
//读入
scanf("%d", &n);
for (int i = 1; i <= m; i ++ )
for (int j = 1; j <= m; j ++ )
scanf("%d", &s[i][j]);
//预处理前缀和
for (int i = 1; i <= m; i ++ )
for (int j = 1; j <= m; j ++ )
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1];
//初始化所有状态
memset(f, -1, sizeof f);
//计算均值X拔
X = (double) s[m][m] / n;
//记忆化搜索
printf("%.3lf\n", sqrt(dp(1, 1, 1, m, m) / n));
return 0;
}
我觉的K表示的是当前有几个矩阵把?
在DP中,当K==N时,dp结束,说明我们已经找到了n个矩阵
请问切的是上半部,为啥加下半部的和啊??dp(k + 1, x1, y1, x2, i) + get(x1, i + 1, x2, y2)
参考题解里的DP递推公式
嗯嗯,相通了
记忆化搜索的部分多次提到方程是选择的左上角x1y1和右上角x2y2,但是在具体实现的时候使用的是左上角和右下角,是写错了还是我的理解有误?
sry,应该是右下角,这里写错了
方差不是平方差的和吗,你这为什么是差的平方
get 计算的是一个块的差的平方,求和是在dp里计算的
这个方差公式为什么是这样的
其实一直有一个问题没想明白,X芭是当前分块的平均值,为什么这里可以用整个大块的平均值来代替呢?谢谢
能不能解释一下直接递归操作的时间复杂度具体是怎么算的,特别是里面的n!
为啥这里dp函数和get函数返回值都要是double类型的才能AC呢?试了一下如果不是double返回值,只能过2/5的数据,但是get和dp函数里面也不涉及除法操作,按理说应该不会影响答案呀
X是double,get函数里要用到X的
您好,同学,请教一下记忆化搜索之前在哪里学过呢
基础课动态规划最后一节就是记忆化搜索。
时间复杂度应该是O(nm^5)吧
状态数是O(nm^4)的,转移是O(m)的,乘起来就是O(n*m^5)吧
是的
大佬,没想明白为什么分割过程中会出现已经分割的块也就是v>=0的时候要直接返回
初始化是-1,如果>=0表示已经计算过并且记住了,直接返回记住的答案即可。
对较大矩阵来说,不同的分割方案可能均会依赖于相同状态的子矩阵(即对该子矩阵还要切割 β 次),所以为了避免多次对相同状态的子矩阵求 v,预设 v < 0,之后只有首次dp子矩阵的操作是必要的(因为是枚举所有情况所以一定正确),额外的dp操作是冗余的,不知道有没有说清楚,不过我已经被我自己驳倒了hh
彩铅gg带带
三角形是什么意思?
铅笔,我的超人。
Pencil必上岸。
彩铅巨巨已经上岸啦
还有一点疑惑,此题每次分割是保留一个抛弃一个,为什么这样的设定才能用DP思想,如果我两块都保留,一共砍k次,我感觉并没有什么不同(也可以用DP)
题目里要求保留一个,然后对另一个继续分割
佬,我想问一下,为啥横切和竖切的取值范围是 x1<= i<x2,为何此处i可以取到x1,此时根本没有进行分割啊
状态定义有关,枚举的是左上角和右下角
巨巨用的是什么笔记软件呀好好看哎
ipad的notebility
3000元左右的运算推荐苹果的哪一种ipad呀
这个你去知乎搜一搜吧,我不是专精数码的hh
不过按照我身边朋友和我的体验来说,一定要买二代笔,一代笔写一会儿手就会很累
哈哈哈,谢谢巨巨
orzorz
彩铅巨巨好棒!🤗
Peter佬熬夜切CF,早上还能这么早起床,太 勤勉 了
太强了 太强了 不愧是我大哥
🥲我很菜的,别埋汰我了