
最近在补全提高课所有题目的题解,宣传一下汇总的地方提高课题解补全计划
题目描述
给定两个长度为 n 个数组 a[n],b[n]
求两个数组的 最长公共上升子序列 长度
解析
这是两个经典DP模型的结合版:
LIS (最长上升子序列,Longest Increasing Subsequence)
LCS (最长公共子序列,Longest Common Subsequence)
LCIS (最长公共上升子序列,Longest Common Increasing Subsequence)
LCIS 也是一个相当经典的DP模型,他的 状态分析 是 LIS 与 LCS 的结合,且听我慢慢道来
闫氏DP分析法:(结合了LCS与LIS的状态表示的方法,可以很直接的发现二者的影子)
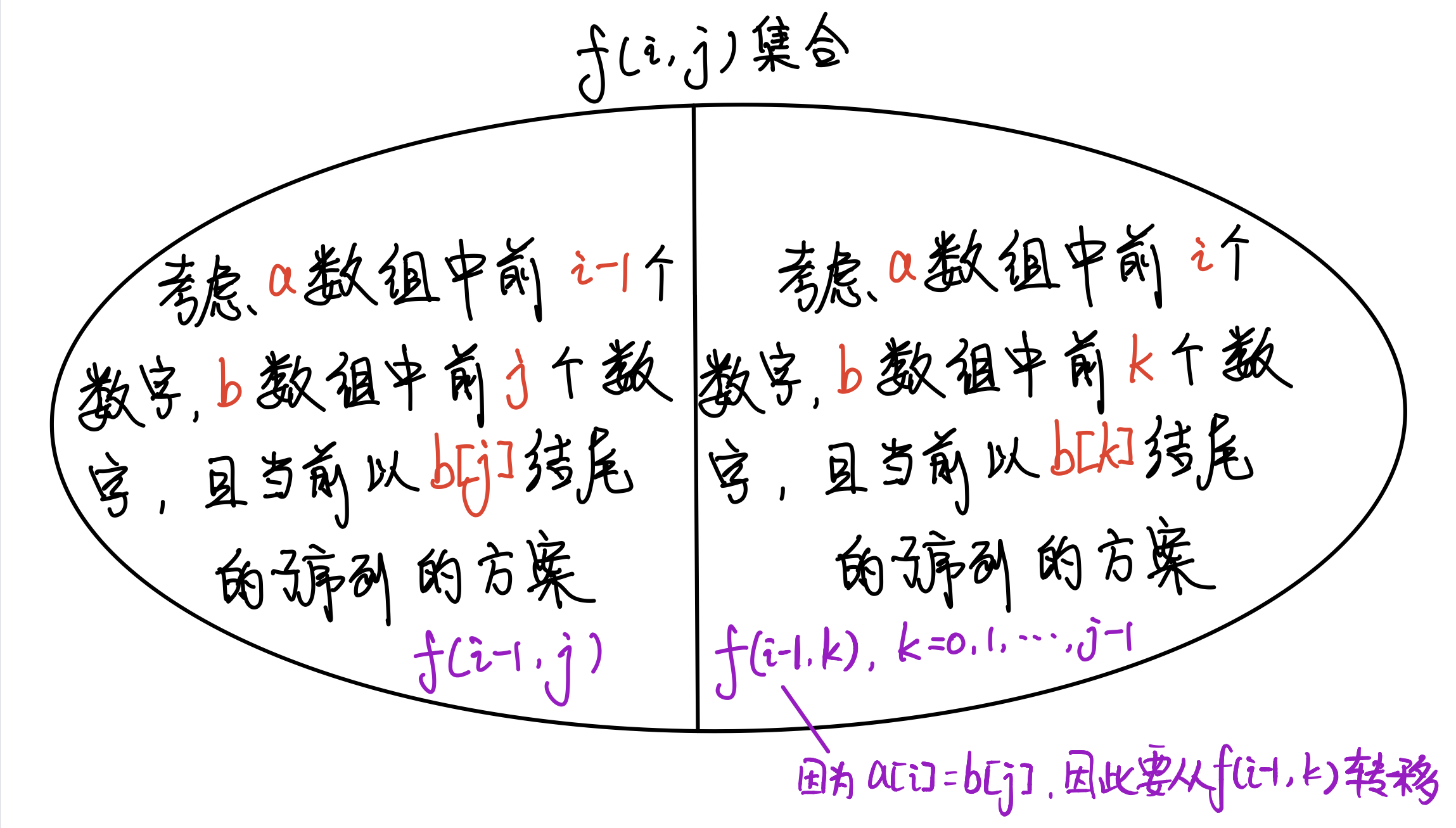
状态表示 f[i][j]—集合:考虑 a 中前 i 个数字,b 中前 j 个数字 ,且当前以 b[j] 结尾的子序列的方案
状态表示 f[i][j]—属性:该方案的子序列长度最大 max
状态转移 :
-
从考虑 a数组 中前 i-1 个数字, b数组 中前 j 个数字 ,且当前以 b[j] 结尾的子序列的方案转移过来:
f_{i,j}=\max(f_{i,j}, f_{i-1,j}) -
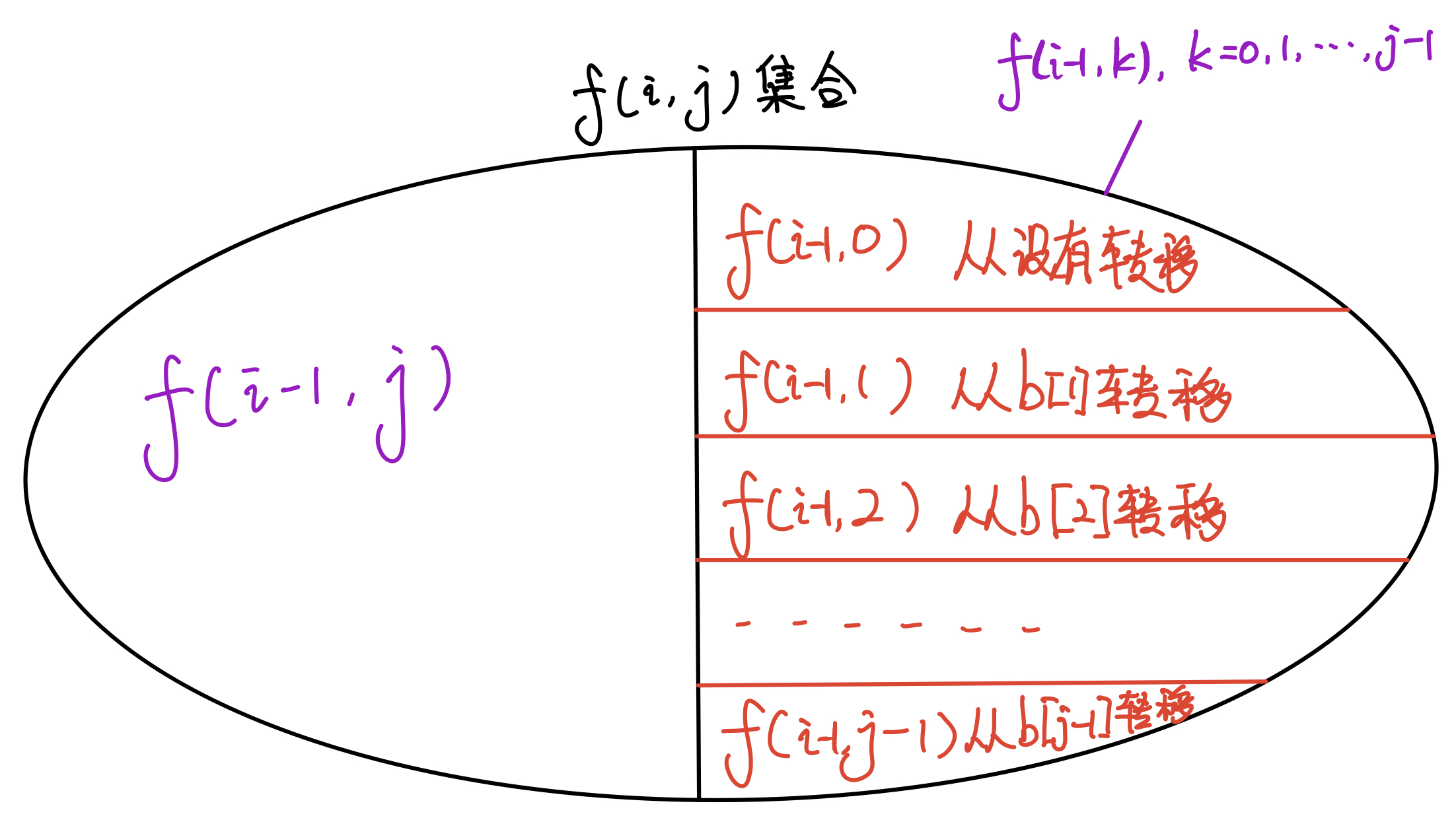
从考虑 a数组 中前 i 个数字, b数组 中前 k 个数字 ,且当前以 b[k] 结尾的子序列的方案转移过来:
f_{i,j}=\max(f_{i,j}, f_{i-1,k} + 1) \quad k\in[0,j-1],a_i = b_j,b_j>b_k
初始状态:f[0][0]
目标状态:f[n][i]
集合划分
Code(朴素版)
时间复杂度:O(n^3)
对于本题的数据规模,毫无疑问会超时
这里贴出代码是方便大家理解这个DP模型,因为接下来的优化,就和DP无关,是一个代码的等价变形优化
#include <iostream>
using namespace std;
const int N = 3010;
int n;
int a[N], b[N];
int f[N][N];
int main()
{
//input
cin >> n;
for (int i = 1; i <= n; ++ i) cin >> a[i];
for (int i = 1; i <= n; ++ i) cin >> b[i];
//dp
for (int i = 1; i <= n; ++ i)
{
for (int j = 1; j <= n; ++ j)
{
f[i][j] = f[i - 1][j];
if (a[i] == b[j])
{
for (int k = 0; k < j; ++ k)
{
if (b[j] > b[k])
{
f[i][j] = max(f[i][j], f[i - 1][k] + 1);
}
}
}
}
}
//find result
int res = 0;
for (int i = 0; i <= n; ++ i) res = max(res, f[n][i]);
cout << res << endl;
return 0;
}
Code(优化版)
我们可以观察到,对于第二种状态转移:f_{i,j}=\max(f_{i,j}, f_{i-1,k} + 1) \quad k\in[0,j-1],a_i = b_j,b_j>b_k
每次用到的 状态 都是第 i - 1 个阶段的
因此我们可以用一个变量,存储上一个阶段的能够接在 a[i] 前面的最大的状态值
时间复杂度:O(n^2)
#include <iostream>
using namespace std;
const int N = 3010;
int n;
int a[N], b[N];
int f[N][N];
int main()
{
//input
cin >> n;
for (int i = 1; i <= n; ++ i) cin >> a[i];
for (int i = 1; i <= n; ++ i) cin >> b[i];
//dp
for (int i = 1; i <= n; ++ i)
{
int maxv = 1;
for (int j = 1; j <= n; ++ j)
{
f[i][j] = f[i - 1][j];
if (b[j] == a[i]) f[i][j] = max(f[i][j], maxv);
if (b[j] < a[i]) maxv = max(maxv, f[i - 1][j] + 1);
}
}
//find result
int res = 0;
for (int i = 0; i <= n; ++ i) res = max(res, f[n][i]);
cout << res << endl;
return 0;
}

k从0开始循环的写法在遇到数列中有非正整数的时候会出错,因为末尾两数相等的情况和0比较无法更新成1,建议在循环前直接将
f[i][j]置为max(f[i][j],1),然后从k1开始循环为什么要从0开始呢,或者为什么要跟1比较一下大小捏?
从0开始是让1也走这个逻辑,其实,1可以初始值,可以直接给初值的,不是一定要从0开始。
#include <bits/stdc++.h> using namespace std; const int N = 3010; int a[N], b[N]; int f[N][N]; int res; // O(n^3) int main() { int n; cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; for (int i = 1; i <= n; i++) cin >> b[i]; for (int i = 1; i <= n; i++) for (int j = 1; j <= n; j++) { f[i][j] = f[i - 1][j]; if (a[i] == b[j]) { int maxv = 1; for (int k = 1; k < j; k++) if (a[i] > b[k]) maxv = max(maxv, f[i - 1][k] + 1); f[i][j] = max(f[i][j], maxv); } } int res = 0; for (int i = 1; i <= n; i++) res = max(res, f[n][i]); printf("%d\n", res); return 0; }这里k就是从1开始的,maxv=1就是初始化,理解为现在a[i]==b[j],是不是两个序列最少有1个LICS长度了,最少是1,其它的发现1个就增加1个长度。
理解咯,谢谢你
优化的时候请问一下为什么要加上if(b[j] < a[i])呢
为什么
f[i][j]不能由f[i][j-1]转移过来呀f[i][j-1]是以b[j-1]结尾的LCIS,f[i][j]是以b[j]结尾的LCIS,b[j]的值会对f[i][j]有影响(如果b[j-1]>b[j]则对于以b[j-1]的结尾的最优解跟以b[j]的结尾的最优解不一样,假设以b[j-1]的结尾的最优解序列为b[k1],b[k2],b[j],b[k2]也大于b[j](((我也不知道我在说什么
一开始我感觉f[i][j]当a[i]!=b[j]时这题应该是f[i][j]=max(f[i-1][j],f[i][j-1]) 但是结果就错了,仔细想一想发现最长上升子序列是针对一个数组的,而最长公共子序列在针对两个数组的,因此这题必须得将重心放在一个序列上,y总取的是以b[j]结尾的意思就是,以第二个序列作为重心,因此如果不相等的话,那么f[i][j]=f[i-1][j],如果相等的话就在b数组中找最长公共上升子序列最大值,
good
##牛逼!!
orz终于得救了
这个才是真正的朴素版
朴素版中f[i][j] = max(f[i][j], f[i - 1][k] + 1);这一步y总写的是f[i][j] = max(f[i][j], f[i][k] + 1),这为什么能过....依赖的层数都不一样,一个是i-1,一个是i,而且都是从1开始
佬
请问大佬,先把最长公共子序列的 序列求出来, 再去找里面的最长递增子序列?
请问大佬,可不可以先把最长公共子序列的 序列求出来, 再去找里面的最长递增子序列?
不可以, 比如1 2 3 9 8 7 6 5 4序列和 9 8 7 6 5 4 1 2 3 序列,筛选出的最长公共子序列应该是9 8 7 6 5 4,但是我们需要的最长公共上升子序列应该是 1 2 3
好的好的谢谢大佬!
不懂为什么循环中k从0开始阿
我也。。佬知道为什么吗
好吧刚试了一下,是初始化的问题,从0开始等效于在第三层循环之前加一句f[i][j] = max(f[i][j], 1)
这里的从0开始实际上就是给f[i][j]初始化为1,但是并不建议这样些,最好还是在循环开始就初始化一下初始值
懂了,谢谢大佬%%%
orz%%%
for (int i = 1; i <= n; ++ i) { int maxv = 1; for (int j = 1; j <= n; ++ j) { f[i][j] = f[i - 1][j]; if (b[j] == a[i]) f[i][j] = max(f[i][j], maxv); if (b[j] < a[i]) maxv = max(maxv, f[i - 1][j] + 1); } }第二重循环里的两个if条件不能交换位置吧,但原题好像也可AC。
可以交换位置的兄弟,因为这两个if条件是相互对立的呀,满足其中一个的话另一个必不可以满足
对,谢谢大佬
可以请问一下QAQ,在第二种情况中“从以 b[k] 结尾的子序列的方案转移过来”,为什么不用在代码中判断一下,a[N]数组是否有对应的元素呢
k枚举的是b[]中的下标,所有一定存在所以只需判断大小关系即可,即
b[j] > b[k]谢谢解答QAQ
orz___