
扩展域并查集就是枚举不同条件的集合
比如当给定说法是a b之间有偶数个1, 而由于1到a这一段是一样的, 我们设这一段1的个数为A,
那么从1到b的1的个数就是 (A+偶数), 设1到a之前1的个数的奇偶性为p(a-1), 1到b之间的1个数的奇偶性
p(b)由于相隔了偶数个1, 所以p(a-1) = p(b); 反过来, 如果是奇数的话, 那p(a-1)和p(b)就只能是
一个为奇一个为偶, 这样, a-1 和 b 点的状态需要用4种情况来表示:
1. 都是奇
2. 都是偶
3. a-1奇, b偶
4. a-1偶, b奇
为了方便, 我们考虑使用+base的统一映射方式来表达同个点不同奇偶性的情况,
我们用p(a-1)来表示a是偶数, p(a-1+base)来表示a是奇数, b点类似
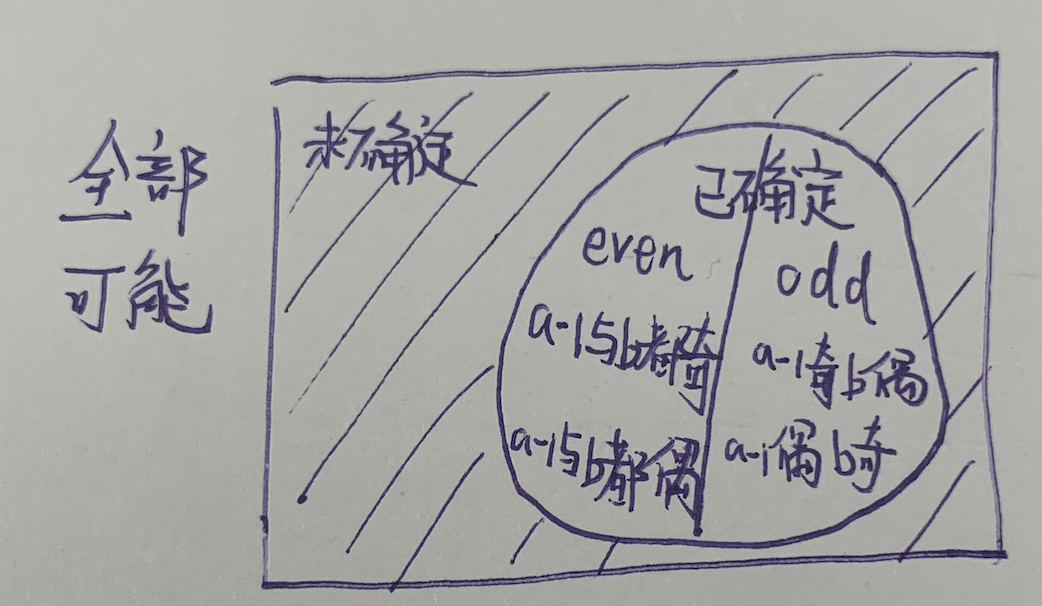
如上图, 每当我们接收到一句话, 我们先要去检查这句话包含的条件(所属的并查集根节点)是否在已知的集合之中, 假如不在, 那就添加进去, 假如在, 但本应该是even的条件在该句话却给了odd的标签, 那就是错误的, 反之亦然
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_map>
using namespace std;
// M的的上限是1w, 每次最多2个新点, 上限就是2w, 算上Base, 需要映射条件, 那就再*2开到4w
const int N = 40010, Base = N / 2;
int n, m;
int p[N];
unordered_map<int, int> S;
int get(int x)
{
if (!S.count(x)) S[x] = ++n;
return S[x];
}
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
cin >> n >> m;
n = 0;
for (int i = 1; i <= N; i ++ ) p[i] = i;
int res = m;
for (int i = 1; i <= m; i++)
{
int a, b;
char type[10];
scanf("%d%d%s", &a, &b, type);
// 离散化
a = get(a - 1), b = get(b);
if (type[0] == 'e')
{
// 如果条件是相等, 根据并查集得到a和b是一奇一偶, 那就是矛盾
// 而由于我们在合并条件的时候会同时把(a+Base, b) 与(a, b+Base)都塞进去,
// 所以我们选其中一个即可
if (find(a + Base) == find(b))
{
res = i - 1;
break;
}
// 下面的else和else其实可以都去掉, 因为如果本来就相等,
// 那么覆盖赋值也不会改变, 反正都在一个集合
// 而如果本来还没有把条件加进来, 那就刚好加一下
else if (find(a) != find(b)) // 条件还没合并就加一下
{
p[find(a)] = find(b);
p[find(a+Base)] = find(b+Base);
}
else
{
// 本来就相等了其实就是已经存在已知集合, 并且合乎当前条件, 那就不用管, 直接空了
}
}
else
{
// 跟上面类似
// 直接省去了else, 对比上面发现道理一样
if (find(a) == find(b))
{
res = i - 1;
break;
}
p[find(a + Base)] = find(b);
p[find(a)] = find(b + Base);
}
}
printf("%d", res);
return 0;
}
