
题目描述
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2,请你判断[l1,r1]和[l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。
第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1≤n,m≤105
样例
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
算法1
字符串哈希
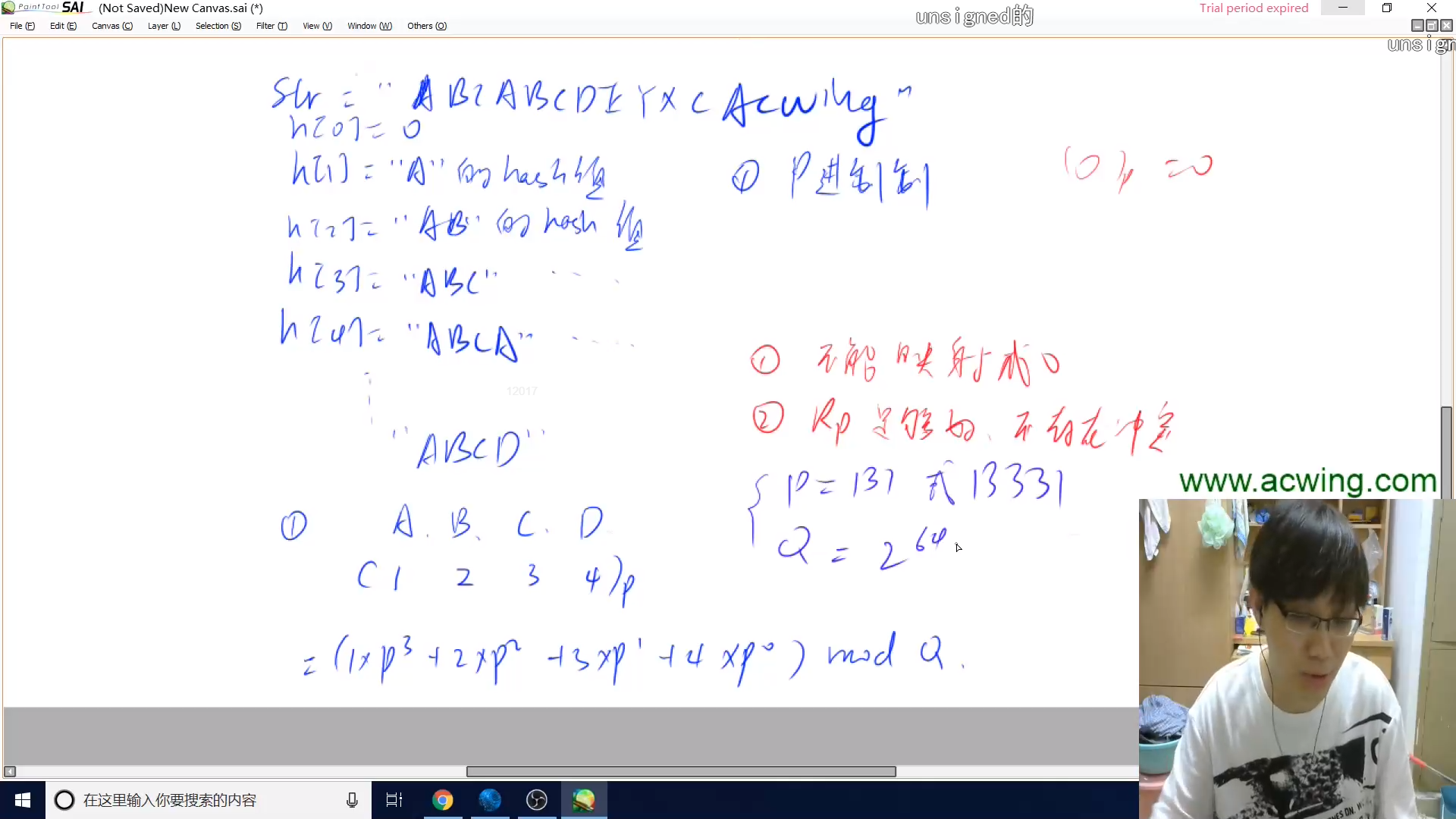
预处理字符串所有前缀的哈希
一般不能映射成0,因为会把不同的字符串映射成同一个值。比如把A映射为0,AA,AAA也都会映射成0
字符串哈希假定不存在哈希冲突
作用:可以解决很多字符串题目
利用前缀哈希算出任意子串的哈希
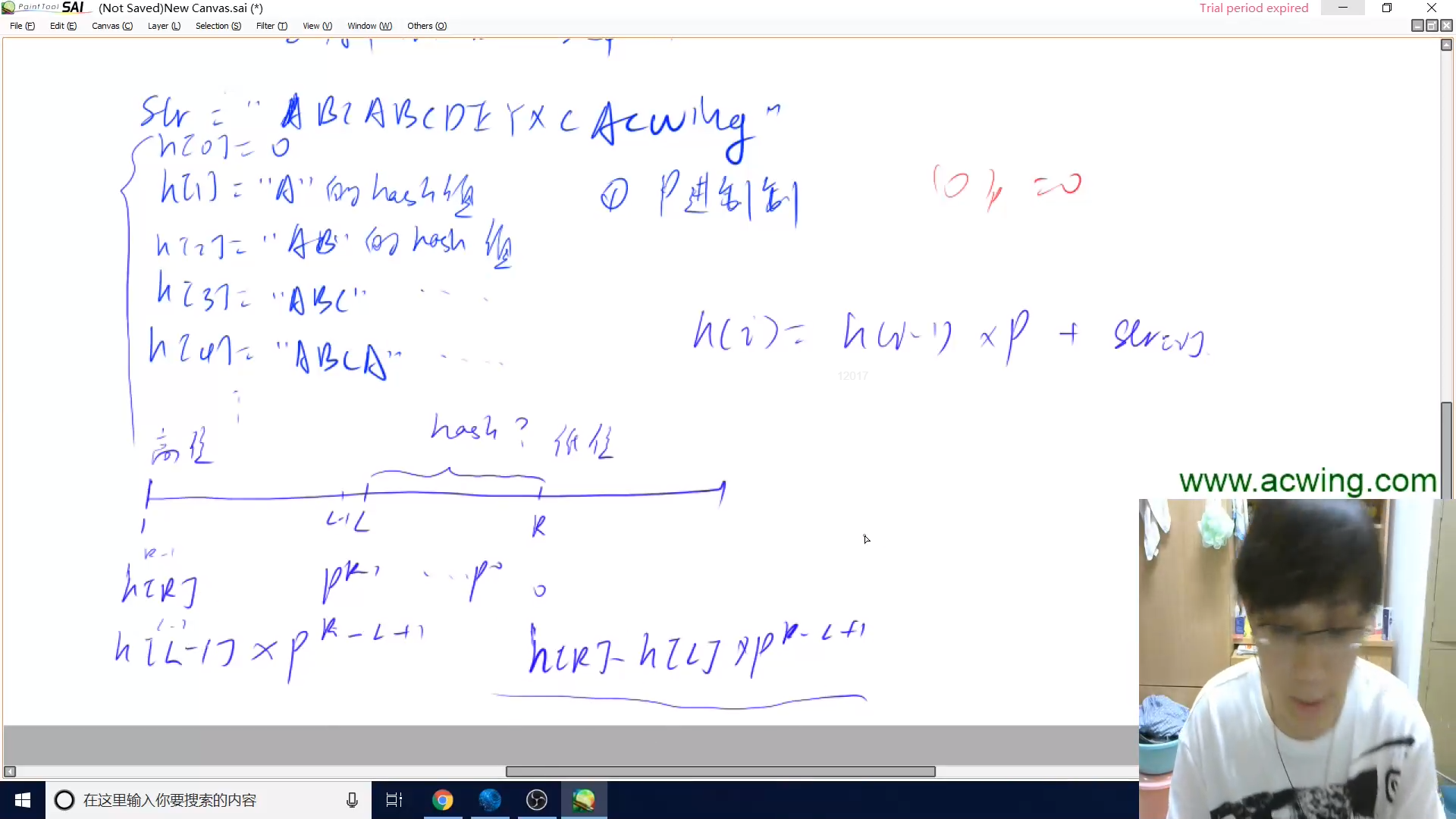
这里公式应该是h[r]-h[l-1]*p^r-l+1
python 代码
def get(l,r):
return (h[r]-h[l-1]*p[r-l+1])%Q
if __name__ == "__main__":
N = 100010
P = 131 #经验值,131或13331
Q = 2**64 #经验值,Q,P这么取,就可以假定不会产生冲突
str=[0 for _ in range(N)]
h = [0 for _ in range(N)]
p = [0 for _ in range(N)]
n,m=map(int,input().split())
s = input()
p[0]=1
for i in range(n):
p[i+1] = (p[i]*P)%Q
h[i+1] = (h[i]*P+ord(s[i]))%Q
for i in range(m):
l1,r1,l2,r2 = map(int,input().split())
if get(l1,r1)==get(l2,r2):
print("Yes")
else:
print("No")
算法2:直接比较子串(亲测超时,所以字符串哈希效率还是很高的)
python代码
def get(l,r):
return s[l-1:r]
if __name__ == "__main__":
N = 100010
n,m=map(int,input().split())
s = input()
for i in range(m):
l1,r1,l2,r2 = map(int,input().split())
if get(l1,r1)==get(l2,r2):
print("Yes")
else:
print("No")
