
知识点
本题考察了很多的知识点组合在了一起:高精度乘法 + 线性筛法 + 新知识点(返回n!中所有质数出现的次数)
线性筛法和以前的模板一摸一样所以不用多说了
高精度乘法这里再把进位加入到数组中的时候,没有采用以前那种写法if(t > 0) list.add(t);而是采用了以下的写法
while (t != 0) //把进位加入到集合中去
{
a.push_back(t % 10);
t /= 10;
}
原因:我们在高精度乘法的时候使用的是把每一位乘以一整个b,所以会有t有多位的情况
举例:$1234 * 111$,我们先是用$4 * 111$ ==> $t = 444$ ==> $t / 10 = 44$,t就出现了多位的情况
所以要用上面的方式进行处理
返回n!中所有质数出现的次数
int get(int n, int p) // 求n!中包含p的次数
{
int res = 0;
while (n != 0)
{
res += n / p;
n /= p;
}
return res;
}
a!中质数出现的次数p = [a/p]下取整+[a/p2]下取整+[a/p3]下取整+…=p的倍数中的个数+p2的倍数中的个数+…,也就是说我们每次计算的是p出现的次数
举例:a = 6,n = 2
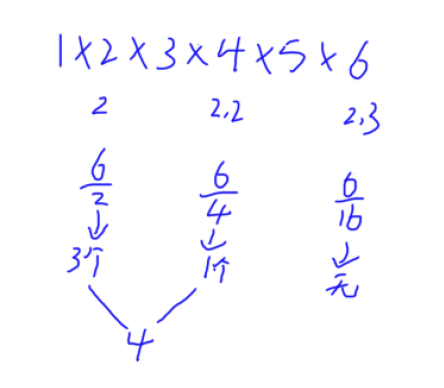
可以发现代码和y总讲的$n / p$,$ n / p^2$不同,这么写其实是等价的
$n /= p$ 等价于$ n / p^2$,$n / p^3$ ......
正确性
为什么这么求答案是对的
问题问的是求$C^b_a$,我们知道$C^b_a = \dfrac{a!}{b!(a-b)!}$,所以问题转化为了求这个公式就可以了
我们求公式的方法是把a!转化为分解质因数的形式$a! = p1^{c1} * p2^{c2} * … * pk^{ck}$,因为数据范围是$1≤b≤a≤5000$,a是大于b的,所以只需要求a就可以了,这样$b$,$a-b$都出来了
然后上下质因子出现的次数相约,剩下的就是我们想要的答案
代码
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
public class Main{
static int N = 5010;
static int[] p = new int[N];
static boolean[] st = new boolean[N];
static int[] sum = new int[N]; //存储所有质数出现的次数
static int cnt;
static List<Integer> list = new ArrayList<>();
public static void main(String[] args){
Scanner in = new Scanner(System.in);
int a = in.nextInt();
int b = in.nextInt();
get_primes(a);
for(int i = 0; i < cnt; i ++) //因为线性筛法每循环一次cnt就会++,所以不能等于
{
int t = p[i];
sum[i] = get(a, t) - get(b, t) - get(a - b, t);
}
list.add(1); //从1开始乘,否则会为0
for(int i = 0; i < cnt; i ++) //循环所有质数
for(int j = 1; j <= sum[i]; j ++) //循环所有质数出现的次数
list = mult(list, p[i]);
for(int i = list.size() - 1; i >= 0; i --) System.out.print(list.get(i));
}
private static void get_primes(int n) //线性筛法筛质数
{
for(int i = 2; i <= n; i ++)
{
if(!st[i]) p[cnt ++] = i;
for(int j = 0; p[j] <= n / i; j ++)
{
st[p[j] * i] = true;
if(i % p[j] == 0) break;
}
}
}
private static int get(int n, int p) //返回n!中所有质数出现的次数
{
int res = 0;
while(n != 0)
{
res += n / p;
n /= p;
}
return res;
}
private static List<Integer> mult(List<Integer> list, int b) //高精度乘法
{
int t = 0;
for(int i = 0; i < list.size(); i ++)
{
t += list.get(i) * b;
list.set(i , t % 10);
t /= 10;
}
while(t != 0)
{
list.add(t % 10);
t /= 10;
}
return list;
}
}
之前的高精度算法也可以啊,楼主还是没有看懂。。之前的是for (int i = 0; i < A.size() || t; i ++ )
只要t还大于0,就会不断把t % 10放置到结果中,而y总写的只是把进位单独处理了,十几个点赞的竟然没有人出来质疑
大佬,还是不理解为什么在返回n!中所有质数出现的次数时,除以p向下取整,然后求所有的个数就是质因子的个数???
比如说在1,2,3,4,5,6,7,8里面找2的个数,那我肯定先找2,不就是2,4,6,8四个吗,那下一步我就是找2的倍数,也就4,然后4,8两个,然后找8,8就一个,这样也就是2的个数也就是7次,然后8/2+8/4+8/8=7,,8/2得4,因为1~8里面偶数的差2就4个,2,4,6,8,1~8里面偶数差4的就两个,之后同理
比如8! = 1 * 2 * 3 * 4 * 5 * 6 * 7 * 8
其中8是质因数2的3次方,因此他能被2,4,8三个2的次方数整除;4是质因数2的平方,因此他能被2,4两个2的次方数整除。同理2和6中仅能拆出质因数2的一次方,因此它只能被2的一次方整除。
https://blog.csdn.net/spidy_harker/article/details/88414504