
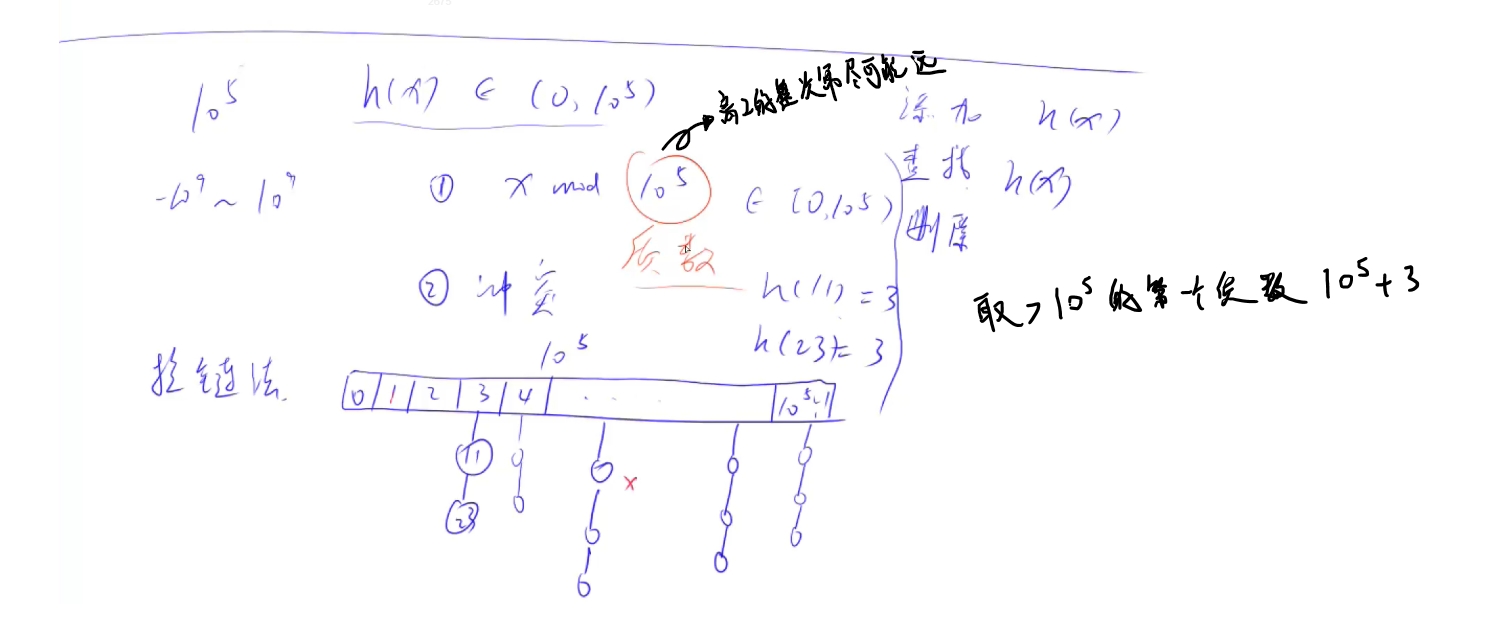
拉链法
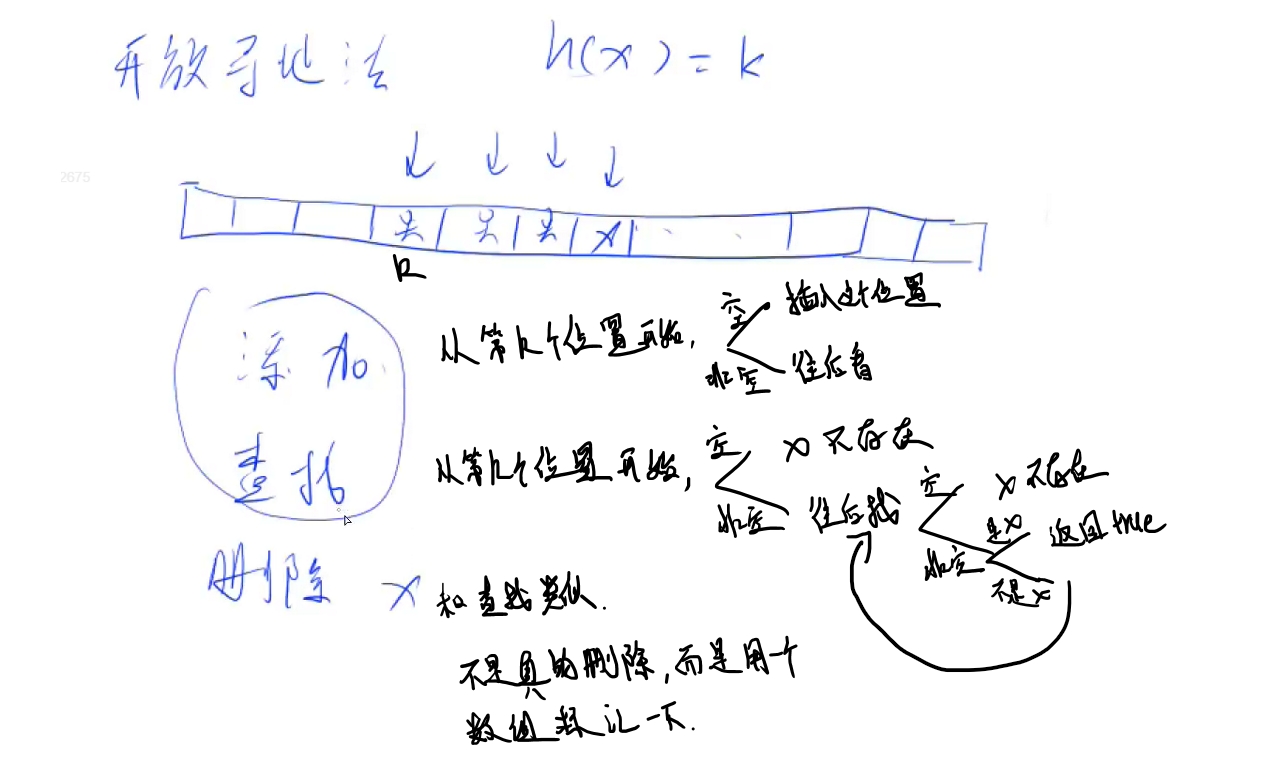
开放寻址法



拉链法代码
/*
* Project: 11_哈希表
* File Created:Sunday, January 17th 2021, 2:11:23 pm
* Author: Bug-Free
* Problem:AcWing 840. 模拟散列表 拉链法
*/
#include <cstring>
#include <iostream>
using namespace std;
const int N = 1e5 + 3; // 取大于1e5的第一个质数,取质数冲突的概率最小 可以百度
//* 开一个槽 h
int h[N], e[N], ne[N], idx; //邻接表
void insert(int x) {
// c++中如果是负数 那他取模也是负的 所以 加N 再 %N 就一定是一个正数
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
bool find(int x) {
//用上面同样的 Hash函数 讲x映射到 从 0-1e5 之间的数
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i]) {
if (e[i] == x) {
return true;
}
}
return false;
}
int n;
int main() {
cin >> n;
memset(h, -1, sizeof h); //将槽先清空 空指针一般用 -1 来表示
while (n--) {
string op;
int x;
cin >> op >> x;
if (op == "I") {
insert(x);
} else {
if (find(x)) {
puts("Yes");
} else {
puts("No");
}
}
}
return 0;
}
开放寻址法代码
/*
* Project: 11_哈希表
* File Created:Sunday, January 17th 2021, 4:39:01 pm
* Author: Bug-Free
* Problem:AcWing 840. 模拟散列表 开放寻址法
*/
#include <cstring>
#include <iostream>
using namespace std;
//开放寻址法一般开 数据范围的 2~3倍, 这样大概率就没有冲突了
const int N = 2e5 + 3; //大于数据范围的第一个质数
const int null = 0x3f3f3f3f; //规定空指针为 null 0x3f3f3f3f
int h[N];
int find(int x) {
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x) {
t++;
if (t == N) {
t = 0;
}
}
return t; //如果这个位置是空的, 则返回的是他应该存储的位置
}
int n;
int main() {
cin >> n;
memset(h, 0x3f, sizeof h); //规定空指针为 0x3f3f3f3f
while (n--) {
string op;
int x;
cin >> op >> x;
if (op == "I") {
h[find(x)] = x;
} else {
if (h[find(x)] == null) {
puts("No");
} else {
puts("Yes");
}
}
}
return 0;
}

此题最快的解法应该是使用
gp_hash_table:#include <iostream> #include <chrono> #include <ext/pb_ds/assoc_container.hpp> using namespace std; using namespace __gnu_pbds; const int RANDOM = chrono::high_resolution_clock::now().time_since_epoch().count(); struct chash { inline int operator ()(int x) const { return x ^ RANDOM; } }; int main() { ios::sync_with_stdio(false); cin.tie(nullptr); int q; cin >> q; gp_hash_table<int, null_type, chash> s; while(q--) { char op; int x; cin >> op >> x; if(op == 'I') s.insert(x); else cout << (s.find(x) == s.end()? "No": "Yes") << '\n'; } return 0; }116 ms,各种 STL 写法见这里。
#include <iostream> #include <cstring> #include <algorithm> #include <set> using namespace std; int main() { int n; cin>>n; set<int>s; while (n -- ) { char op; int a; cin>>op>>a; if(op=='I')s.insert(a); else { if(s.count(a))cout<<"Yes"<<endl; else cout<<"No"<<endl; } } }STL大法好!
忘了可以直接STL做了,我是大笨蛋T^T
如果数据过大,例如要存储下标超过1e9,就不适合用STL,用手写哈希表不仅省空间,速度还更快
可以看看例题4407
大佬4185这道题建议用stl吗
容器unordered_map 真是百试不厌
#include <iostream> #include <unordered_map> using namespace std; const int N = 100010; unordered_map<int , int > mp; // 左边是数值 右边是出现与否 int main() { int i; int n; char temp ; int tempx; cin >> n; for(i=1 ; i<=n ; i++) { cin >> temp >> tempx; if(temp == 'I') { if(mp.find(tempx) == mp.end()) // 没有 { mp.insert({tempx , 1}); } else {} ; // 如果有 不管 } else { if (mp.find(tempx) != mp.end()) { cout << "Yes" << endl; } else {cout << "No" << endl;} } } return 0; }zygg太强了
为什么将 null = 0x3f3f3f3f 可以过 ; 而将 null = 1e9+100;会超时啊?(-1e9<n<1e9);
你去搜0x3f3f3f在menset里面有一个优点。可能和这
个有关系
我猜你用meset初始化了。
综述,如果用
memset(h, 1e9 + 10, siezeof h), 数组中的每个元素会被初始化为01100100 01100100 01100100 01100100(补码)人话:如果你输出数组中的元素,你会发现值压根不是
1e9 + 100#### Python
from collections import defaultdict Mod = 1000003 def insert(x): k = (x % Mod + Mod) % Mod graph[k].append(x) def find(x): k = (x % Mod + Mod) % Mod if x in graph[k]: return True else: return False n = int(input()) graph = defaultdict(list) for i in range(n): op, x = input().split() x = int(x) if op == 'I': insert(x) else: if find(x): print("Yes") else: print("No")我想问一下为什么mod N 就是映射到0-N
是0到 n-1.因为是整除N得到的余数
那一段字看着好眼熟,是算法竞赛进阶指南里的?
为什么要开N这么大的数组啊?
因为数据范围是1e5 如果要把所有数据都映射下来这是最小的
开放寻址中,k=N时,为什么要将k赋值0呢
走到底了,还没找到,就从前面k=0再往后面找
可是从头开始再找和第一遍找,有什么区别呢
刚进入函数时,t可以是0到N-1中的任何数字,假如t=66,那么遍历66到N-1后,发现都不行,h[t] != x,那么就要回到0,从头开始搜。
噢噢谢谢!可是我还发现,把那一行去了也能ac,是为什么呢?
可能数据不完善吧
我一开始也没有懂,后来一想 数组最大长度为 0-n-1,当第n-1个位置用完的时候,不用用第N个位置,不然数组越界了,应该从头开始探测
拉链法最迷的就是h[k]那个,你这样写我还是看不懂啊,哈哈
懂了,hh
同理不是很懂,感觉因该是单链表没有学好。唔
我也不太懂h[k]的含义😭
hk就相当于head
h[k]就等于是单链表带头节点的head指针
h[k]是一个数值,idx是元素的位置,让h[k]=idx 我是实在理解不了
h[k]是模拟的散列表,e[i]是链子,就算是在h[k]这个头结点后面插入也不应该这样写啊,我实在理解不了,时隔4个月,懂了的话希望解答一下,谢谢
这个插入是头插法,你自己模拟一下应该就懂h[ ]数组的含义了
它这个拉链法是在k=(x%N+N)%N中相同的点,也就是具有同样k的数,拉一条链子。然后我们查询一个数的时候,就去遍历这条链子上的数。举个例子,比如a和b是在一个链子上。开始的时候,idx=0,e[0]=a,ne[0]=h[k]=-1,h[k]=idx=0,idx=1;插入b的时候,e[1]=b,ne[1]=h[k]=0,h[k]=idx=1,idx=2;
这样我们就把a,b串在了一条链子上,即b-a。查询的时候,比如查a,k=(a%N+N)%N,此时i=h[k]=1,e[1]=b;然后i=ne[1]=0,e[0]=a,也就是找到了a.
记住一点就好:h[k]是用来存取模后为k的当前链子的头下标。
谢谢谢谢,已经理解深刻了
谢谢谢谢,已经懂了
解释的好!!!
那个可以当成赋值嘛
为什么我memset函数里的长度用N表示就通过不了用sizeof就能通过呀
拉链法:81ms
开放寻执法:639ms
差距#include <cstring> #include <iostream> using namespace std; const int N = 100003; template <class key, class val> class has { public: val h[N], e[N], ne[N]; int idx; void clear() { memset(h, -1, sizeof h); } void insert(val x) { int k = (x % N + N) % N; e[idx] = x; ne[idx] = h[k]; h[k] = idx ++ ; } bool count(int x) { int k = (x % N + N) % N; for (val i = h[k]; ~i; i = ne[i]) if (e[i] == x) return true; return false; } }; int main() { has <int, int> hh; hh.clear(); int n = 0; scanf("%d", &n); while (n -- ) { char op[2]; int x = 0; scanf("%s%d", op, &x); if (*op == 'I') hh.insert(x); else { if (hh.count(x)) puts("Yes"); else puts("No"); } } return 0; }我把idx初始化为1,然后将h数组初始化从1到n为-1,为什么不正确
弄个好点的模数线性探测就行
点这里
#include[HTML_REMOVED]
#include[HTML_REMOVED]
using namespace std;
int main()
{
set[HTML_REMOVED]st;
int n;
cin>>n;
while(n–)
{
string s;
int x;
cin>>s>>x;
if(s==”I”) st.insert(x);
else
{
if(st.count(x)) cout<<”Yes”<<endl;
else cout<<”No”<<endl;
}
}
return 0;
}
为什么不
map<int, bool>呢?因为map常数巨大。
知道了,谢谢,
但是我map也过了因为这道题目叫做模拟哈希表O.o
我试了一下,unordered_set 是160ms,作者的两份都是三百以上QaQ
好强/se
大佬,代码可以给我看看嘛,我一开始也是这个思路没写出来
蒟蒻一枚~
#include<iostream> #include<unordered_set> using namespace std; int main() { int s; unordered_set<int> set; cin>>s; getchar(); while(s--){ char c;int k; scanf("%c %d",&c,&k); getchar(); if(c=='I'){ set.insert(k); }else{ if(set.count(k)){ printf("Yes\n"); }else{ printf("No\n"); } } } return 0; }但是空间占的多
#include<iostream> #include<unordered_set> using namespace std; int main() { int s; unordered_set<int> set; cin>>s; while(s--){ string c;int k; cin>>c>>k; if(c=="I"){ set.insert(k); }else{ if(set.count(k)){ printf("Yes\n"); }else{ printf("No\n"); } } } return 0; }改了一点点能过,虽然占的空间大一点点,但是时间都差不多,这么写好方便哈哈哈
谢谢老板的思路
爱了
unordered_set容器可以存在重复元素对吗
不会的
有一个问题 ,数插入的次数x (<1e5)都比 mod(p) 的p 小(p =1e5 + 3)
那对应的不就是一一映射吗? 没有必要创造链表 来存储重复映射到p的元素啊。
简而言之,就是槽开多了, 槽的数量比 要映射的原集合 元素数量还要多
次数和一一映射没有关系吧 这里又不能保证是单射
对,是这样
为什么要开N这么大的数组啊?
拉链法中的N 是最接近最大范围(10的5次方的质数) 开放寻址法中,一般需要开固定槽的两到三倍(防止冲突,课上讲的),故选择2*10的五次方最近的质数
不一定是一 一映射,比如所有的数中没有一个数映射到2,那2就必须浪费了,所以槽的数量就要开大些
大佬请问h[N]的那个槽是干什么用的呀 我看main函数里面没有用到h[N]这个槽啊~并且还有清空槽 感觉有点抽象 求解求解~
insert这个函数和查找函数用到了啊
我理解是相当于头指针,每次插入完后,h[k]都跟着idx加1然后指向下一个点。
不懂那个e数组和ne数组是什么
看一下单链表和双链表