
二维前缀和推导
如图:
 {:width=”50%”}
{:width=”50%”}
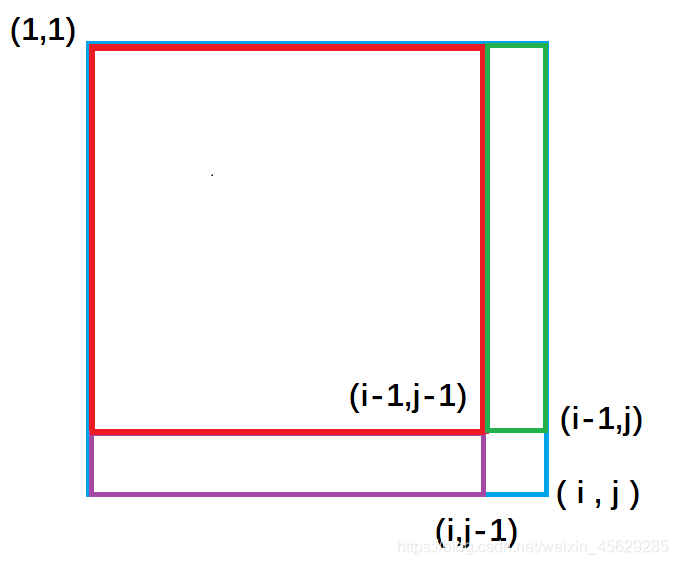
紫色面积是指(1,1)左上角到(i,j-1)右下角的矩形面积, 绿色面积是指(1,1)左上角到(i-1, j )右下角的矩形面积。每一个颜色的矩形面积都代表了它所包围元素的和。
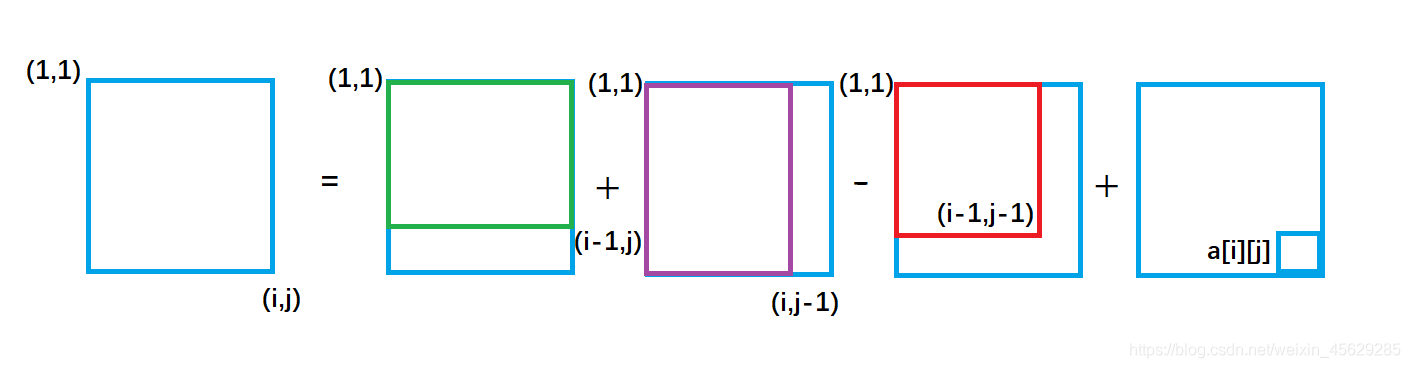
从图中我们很容易看出,整个外围蓝色矩形面积s[i][j] = 绿色面积s[i-1][j] + 紫色面积s[i][j-1] - 重复加的红色的面积s[i-1][j-1]+小方块的面积a[i][j];
因此得出二维前缀和预处理公式
s[i] [j] = s[i-1][j] + s[i][j-1 ] + a[i] [j] - s[i-1][ j-1]
接下来回归问题去求以(x1,y1)为左上角和以(x2,y2)为右下角的矩阵的元素的和。
如图:
 {:width=”50%”}
{:width=”50%”}
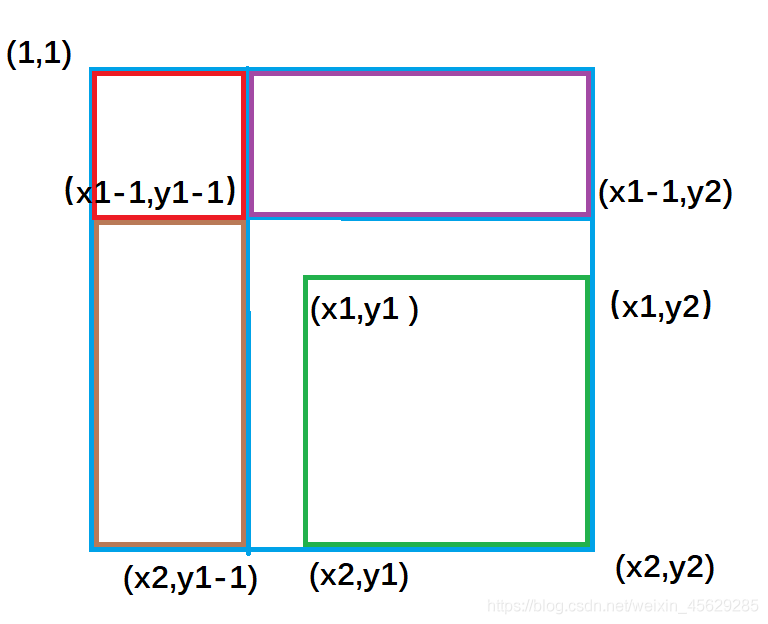
紫色面积是指 ( 1,1 )左上角到(x1-1,y2)右下角的矩形面积 ,黄色面积是指(1,1)左上角到(x2,y1-1)右下角的矩形面积;
不难推出:
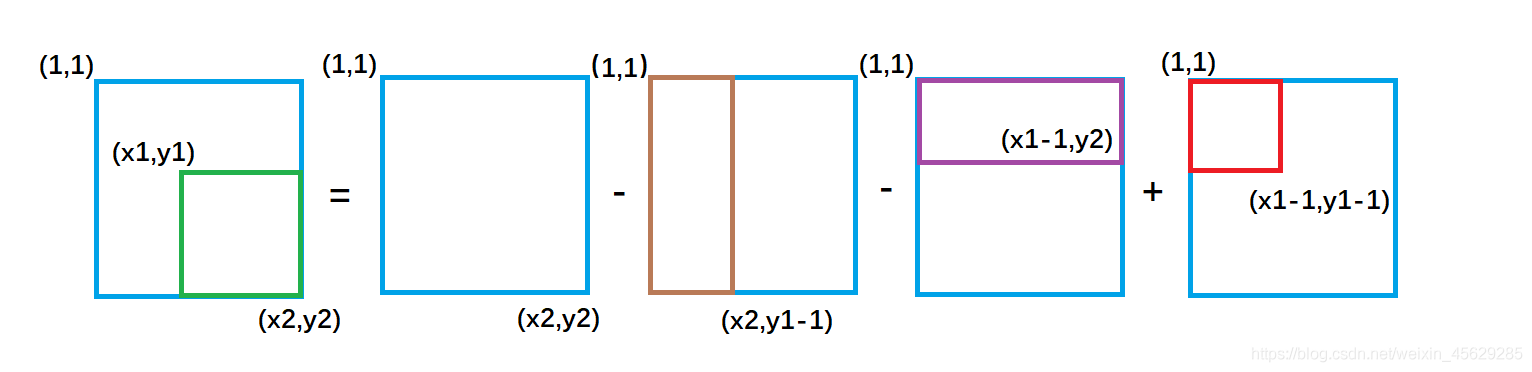
绿色矩形的面积 = 整个外围面积s[x2, y2] - 黄色面积s[x2, y1 - 1] - 紫色面积s[x1 - 1, y2] + 重复减去的红色面积 s[x1 - 1, y1 - 1]
因此二维前缀和的结论为:
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
s[x2, y2] - s[x1 - 1, y2] - s[x2, y1 - 1] + s[x1 - 1, y1 - 1]
总结:

代码:
#include <iostream>
using namespace std;
const int N = 1010;
int n, m, q;
int s[N][N];
int main()
{
scanf("%d%d%d", &n, &m, &q);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
scanf("%d", &s[i][j]);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1];
while (q -- )
{
int x1, y1, x2, y2;
scanf("%d%d%d%d", &x1, &y1, &x2, &y2);
printf("%d\n", s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]);
}
return 0;
}

博主为什么用cin和cout写会爆栈呢
简单来讲scanf 和 cin 在时间效率上差别很大的原因是:
在scanf元素的类型我们已经告知了,机器不用再去查找元素类型,scanf需要自己写格式,是一种格式化输入。
而在cin 元素类型由机器自己查找,cin是字符流输入,需要先存入缓冲区再输入。
咋还是错的…大佬们帮忙看看啊
#include<iostream> #include<cstdio> using namespace std; int a[1001][1001],x1[200010],y1[200010],x2[200010],y2[200010],d[1001][1001]; int main() { int n,m,q; cin>>n>>m>>q; for(int i = 0;i < n;i ++){ for(int j = 0;j < m;j ++){ cin>>a[i][j];d[i][j]=d[i-1][j]+d[i][j-1]-d[i-1][j-1]+a[i][j]; } } for(int i = 0;i < q;i ++) { cin>>x1[i]>>y1[i]>>x2[i]>>y2[i]; cout<<d[x2[i]-1][y2[i]-1]+d[x1[i]-2][y1[i]-2]-d[x1[i]-2][y2[i]-1]-d[x2[i]-1][y1[i]-2]<<endl; } return 0; }下标从1开始最好,你让i=1,j=1然后到n就好了,不然会有边界问题,从零开始和矩阵对应不上
下标从0开始最后会减到-1,导致数组越界。
s[x2, y2] - s[x1, y2] - s[x2, y1] + s[x1 , y1] 请问求子矩阵的和不能这样计算吗
不行,因为这样就会把边界的值漏掉,建议自己把两个矩阵都画出来然后再来看,就会清晰很多
可以类比一维的前缀和,求i到j之间的和为s[j]-[i-1];
s数组是包含下标的数的,而我们要求的是下标之间的和(包括下标)
不是漏掉,而是不能不能多减去“自己”。
请问大图中减掉后不还剩蓝色和绿色中间一个L型的面积吗
orz
66666
tql
orz
大佬 图片挂掉了
会有segment错误
%%%
赞
妙妙秒
orz
为什么用cout会爆了
简单来讲scanf 和 cin 在时间效率上差别很大的原因是:
在scanf元素的类型我们已经告知了,机器不用再去查找元素类型,scanf需要自己写格式,是一种格式化输入。
而在cin 元素类型由机器自己查找,cin是字符流输入,需要先存入缓冲区再输入。
太厉害了!
yyds!!!!!
66666很厉害!!
还是没懂为啥求部分和的公式要写成y1-1,x1-1什么的
懂了懂了哈哈