
更新:图源自算法基础课程讲解
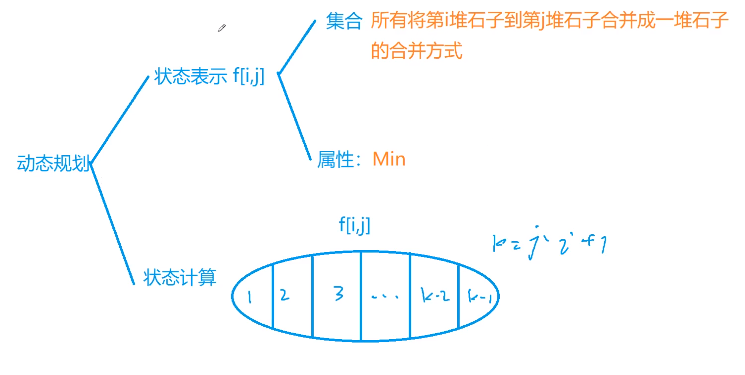
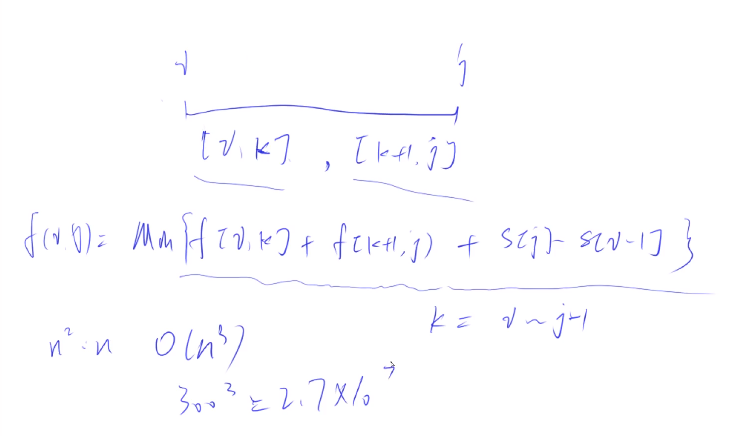
具有明显的阶段性(相邻的合并),所以只能区间dp,不能贪心
#include<bits/stdc++.h>
using namespace std;
const int N=310,INF=0x3f3f3f3f;
int f[N][N];
int s[N];
int n;
int main(){
cin>>n;
memset(f,INF,sizeof(f)); //记得初始化
for(int i=1;i<=n;i++){
cin>>s[i];
f[i][i]=0; //初始化
}
for(int i=1;i<=n;i++) s[i]+=s[i-1];
for(int len=2;len<=n;len++){
for(int l=1;l+len-1<=n;l++){
int r=l+len-1;
for(int k=l;k<r;k++){
f[l][r]=min(f[l][r],f[l][k]+f[k+1][r]+s[r]-s[l-1]);
}
}
}
cout<<f[1][n]<<endl;
return 0;
}
另一种区间划分方式:
#include<bits/stdc++.h>
using namespace std;
const int N=310;
int f[N][N],a[N],s[N];
int n;
int main(){
cin>>n;
memset(f,0x3f,sizeof(f));
for(int i=1;i<=n;i++){
cin>>a[i];
s[i]=s[i-1]+a[i];
f[i][i]=0;
}
for(int len=2;len<=n;len++){
for(int l=1;l+len-1<=n;l++){
int r=l+len-1;
for(int k=l+1;k<=r;k++){
f[l][r]=min(f[l][r],f[l][k-1]+f[k][r]+s[r]-s[l-1]);
}
}
}
cout<<f[1][n]<<endl;
}

y总说的最后一步我没明白s[j]-s[i-1]
为什么最后一步是这个
s代表前缀和数组,s[j]-s[i-1]代表a[i]到a[j]的和
就是不理解两俩合并之后权重改变了为什么还可以用原来的前缀和来更新
左边的区间[l,k-1]和右边的区间[k,r]合并,此时左边的区间和为s[k-1]-s[l-1],右边的区间和为s[r]-s[k-1],状态转移时这两个区间和要相加,即s[j]-s[i-1]
噢噢 明白了 谢谢
客气
Thanks♪(・ω・)ノ
我认为有个更好的理解方式,[l,k] [k + 1,r] 分别代表两个区间,那么之前这两个区间产生的代价是f[l][k-1]+f[k][r],现在我想要合并,就是计算[l, r]的和,两者加起来就是更新
我补充个例子 有两堆石子,第一堆个数为3,第二堆个数为2 而合并代价是3+2+(3+2)
假设有4堆石子:1 3 5 2
i=1,k=2,j=4
f[1,2]:将第一堆和第二堆这两堆石子合并成一堆石子
f[3,4]:将第三堆和第四堆这两堆石子合并成一堆石子
所以经过f[1,2]+f[3,4]后我们就成功将1 3 5 2这四堆石子合并成了4 7 这两堆石子
不过别忘了题目要求的是将这四堆石子合并成一堆石子
所以我们还需将4 7 这两堆石子合并成一堆石子
因此还需付出4+7=11的代价;而11=[1,4]的前缀和
总代价:(1+3)+(5+2)+4+7=22
找这句话找了好久。。。
左端点为什么需要满足式子?l+len-1<=n
非常不理解这个地方,为什么需要左端点加上长度值呢?
假设左端点值为l,区间长度为len,那么右端点显然为l+len-1,根据题意右端点要在n以内
因为 r - l + 1 = len
所以 r = len + l - 1
为什么f要进行初始化呀?
f[i][i]=0是什么意思
本身自己不需要合并,所以需要的体力为0
懂了,谢谢
为什么一旦右端点写成i + len 输出结果为0?
为什么在枚举左端点的时候限制条件可以是i+len-1呢?就是这个非常不明白
这个是区间的最大值,如果超过,就不存在
第二行N个数,表示每堆石子的质量(均不超过1000)。1≤N≤300 怎么根据这两个条件判断f [ ][ ]初值要为1e8?????
因为最后要求的是最小值,设一个超级大的数可以被后面计算使用min迭代掉,但是要是默认的0可能会影响计算结果
请问为什么初始化为INF?
初始化为无穷大,是因为将初值为无穷大视为非法操作,另一方面在求最小值的问题中,初值设为INF是常用的解决技巧。
懂了,多谢老哥
客气了
右端点为什么是 i + len - 1 ? 如果len是2 左端点是1 右端点应该是3吧
左端点为1,代表1和2合并,所以右端点为2
我的理解是len是区间长度,len为2说明有两堆,左端点是1则右端点下标就是2
请问为啥要从2枚举啊 orz
至少需要两堆才能合并的
谢谢
不应该是堆的长度是大于一才有意义吗?
都是一个意思啊
300的3次方是 2.7e7吧
是啊
请问为什么要先枚举长度
因为要保证后面使用到的状态在前面被计算过,所以只能先枚举长度(这也是区间dp基本的技巧,所有的区间dp问题,第一维都是枚举区间长度)
懂了,谢谢大佬
怎么样才可以判断某一个题是区间dp啊
看能否是区间转移过来的状态(很多时候是靠题感
您好,我想问一下第一种代码 for(int k=l ; k<r ; k++) ,k为什么不能等于 r ?
$因为会用到f[k+1][r],显然k+1<=r,即k<r$
但实际等于 r 也可以AC ?
$能ac不代表程序是对的,和题目数据有关系$
$说明现在的数据求最优解中,没有用到最后一堆石子来划分的,所以能够ac,但是程序是不对的$
$可以从状态的定义来思考,f[l][r]代表从第l堆石子合并到第r堆石子$
$当实际等于 r ,即f[r+1][r],显然是不合法的一种状态$
边界把
请问一下,为什么最后输出的是 f[1][n] ,每次输出结果的时候就不是很明白。
初始化和输出等问题还是要从状态的定义来出发,本题中f[i][j]代表从第i堆石子合并到第j堆所花费的最小代价,那么从第一堆合并到第n堆的最小代价显然为f[1][n]
哦哦,一句话就懂了,谢谢orz
别客气
这里用len枚举区间长度是预处理的意思么
是保证在计算f[l][r]时,f[l][k-1]和f[k][r]已经算过了
因为len从小到大遍历,f[l][k-1]和f[k][r]的len显然小于f[l][r],所以能够保证可以计算出f[l][r]
再弱弱问一下k的意思是什么
k是保证区间内的代价最小么
别客气的,k代表决策点,也可以理解为划分点,表示将l到k-1分为一段,k到r分为一段
谢谢
这两个区间划分的方式处理起来有区别吗
一般是没有区别的(例如本题),部分题目只能选择一边,但是这种题目比较少
ok
建议不要用付费课程里的截图。
已向yxc老师申请,老师说注明图片来源即可,感谢提醒
不好意思
也是为了方便大家学习,客气了
还是不太好啦,毕竟是付费课程
打卡可以用吗QWQ
同学 这里的S[]指的是什么?
前缀和
嗯嗯
orz
互相学习
没看懂这里的len表示的啥?是区间长度吗?
是的,就是区间长度
ok谢谢大佬
应该是点的个数吧