
题目描述
最近的降雨,使田地中的一些地方出现了积水,field[i][j] 表示田地第 i 行 j 列的位置有:
- 若为
W, 表示该位置为积水; - 若为
., 表示该位置为旱地。
已知一些相邻的积水形成了若干个池塘,若以 W 为中心的八个方向相邻积水视为同一片池塘。
请返回田地中池塘的数量。
样例
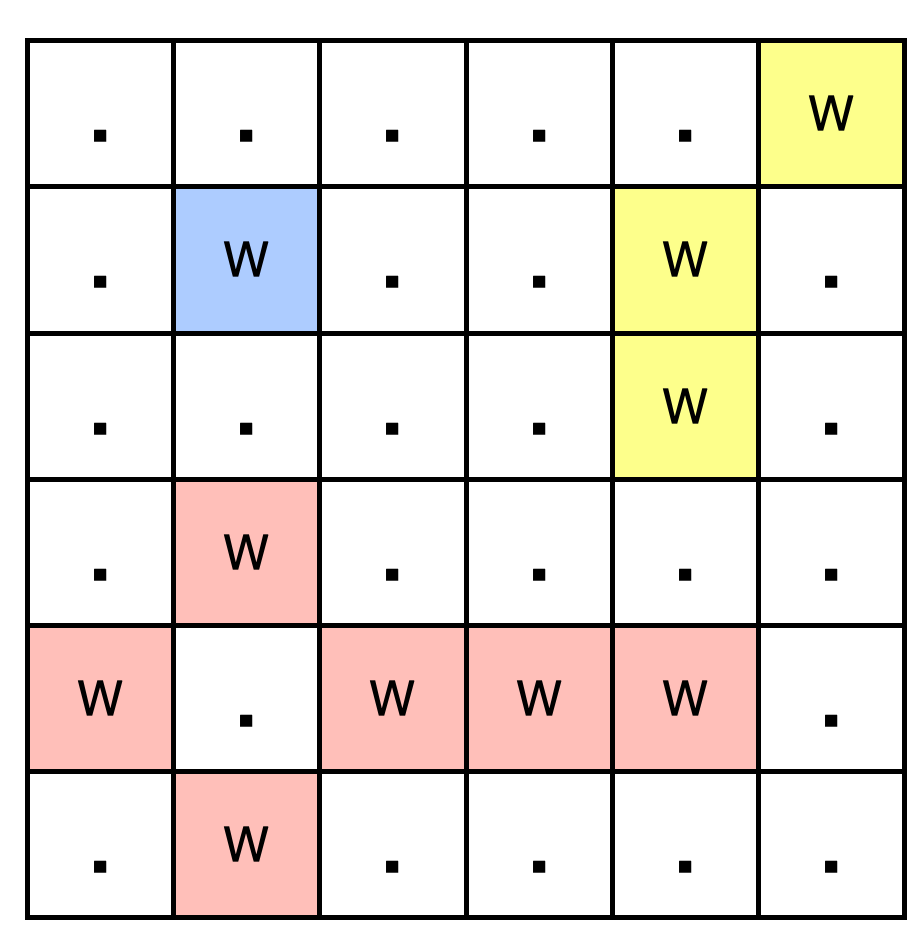
输入: field = [".....W",".W..W.","....W.",".W....","W.WWW.",".W...."]
输出:3
解释:如下图所示,共有 3 个池塘:
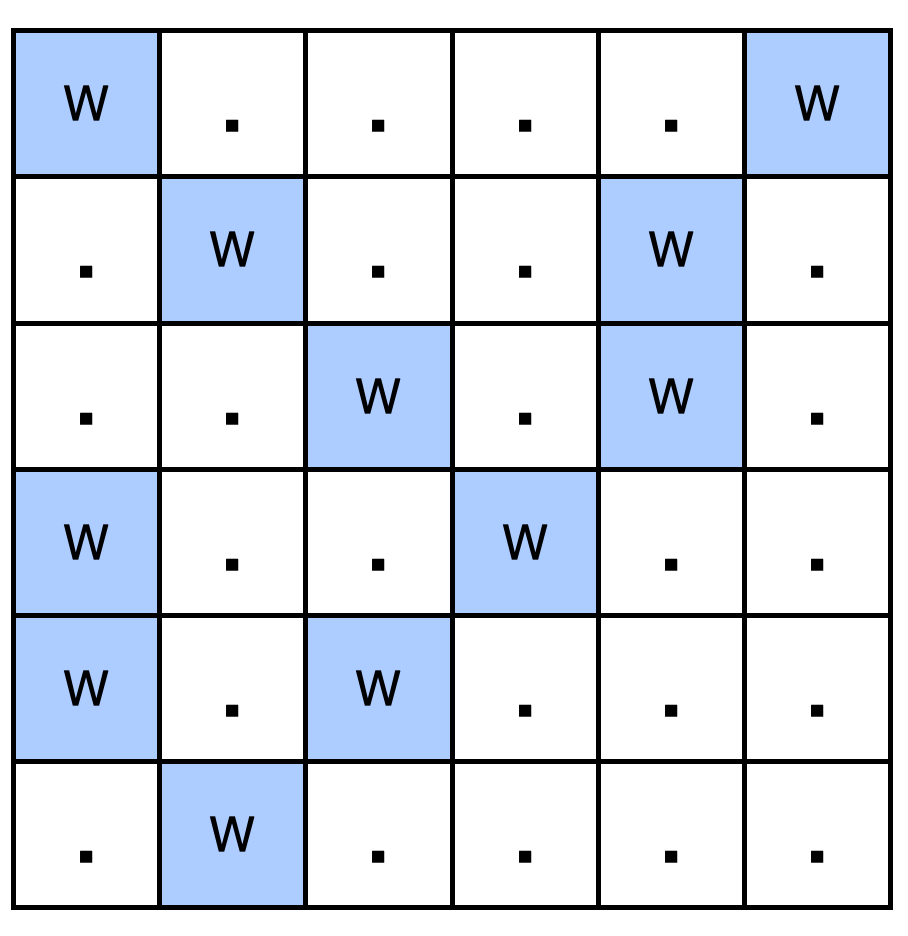
输入: field = ["W....W",".W..W.","..W.W.","W..W..","W.W...",".W...."]
输出:1
解释:如下图所示,共有 1 个池塘:
限制
1 <= field.length, field[i].length <= 100field中仅包含W和.。
算法
(深度优先遍历) $O(mn)$
- 裸的 Flood Fill,可采用深搜或者宽搜。
时间复杂度
- 每个位置最多遍历一次,故时间复杂度为 $O(mn)$。
空间复杂度
- 需要 $O(mn)$ 的额外空间存储递归的系统栈或者宽搜队列。
C++ 代码
const int dx[] = {0, -1, -1, -1, 0, 1, 1, 1};
const int dy[] = {-1, -1, 0, 1, 1, 1, 0, -1};
class Solution {
private:
int m, n;
void dfs(int x, int y, vector<string> &field) {
field[x][y] = '.';
for (int i = 0; i < 8; i++) {
int tx = x + dx[i], ty = y + dy[i];
if (tx < 0 || tx >= m || ty < 0 || ty >= n)
continue;
if (field[tx][ty] == 'W')
dfs(tx, ty, field);
}
}
public:
int lakeCount(vector<string>& field) {
m = field.size();
n = field[0].size();
int ans = 0;
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
if (field[i][j] == 'W') {
dfs(i, j, field);
ans++;
}
return ans;
}
};
