
题目描述
在一个排序的链表中,存在重复的节点,请删除该链表中重复的节点,重复的节点不保留。
数据范围
链表中节点 $val$ 值取值范围 $[0,100]$。
链表长度 $[0,100]$。
样例1
输入:1->2->3->3->4->4->5
输出:1->2->5
样例2
输入:1->1->1->2->3
输出:2->3
思路
这是一道链表加双指针的题目,由于链表已经排好序了,所以其实可以把链表分成数值相同的几个区间,分别枚举每个区间,如果这一个区间长度大于$1$,就把这一段全部删掉。
在枚举每个区间时,可以采用双指针算法,第一个指针指向上一个区间的最后一个结点,第二个指针指向枚举的区间的最后一个数的后面一个数,再判断区间元素数量是否大于$1$,其实就是看第一个指针的后面的后面是否是第二个指针(这样区间内的数只有一个)。
如果你没看懂的话,就看下下面这幅图:
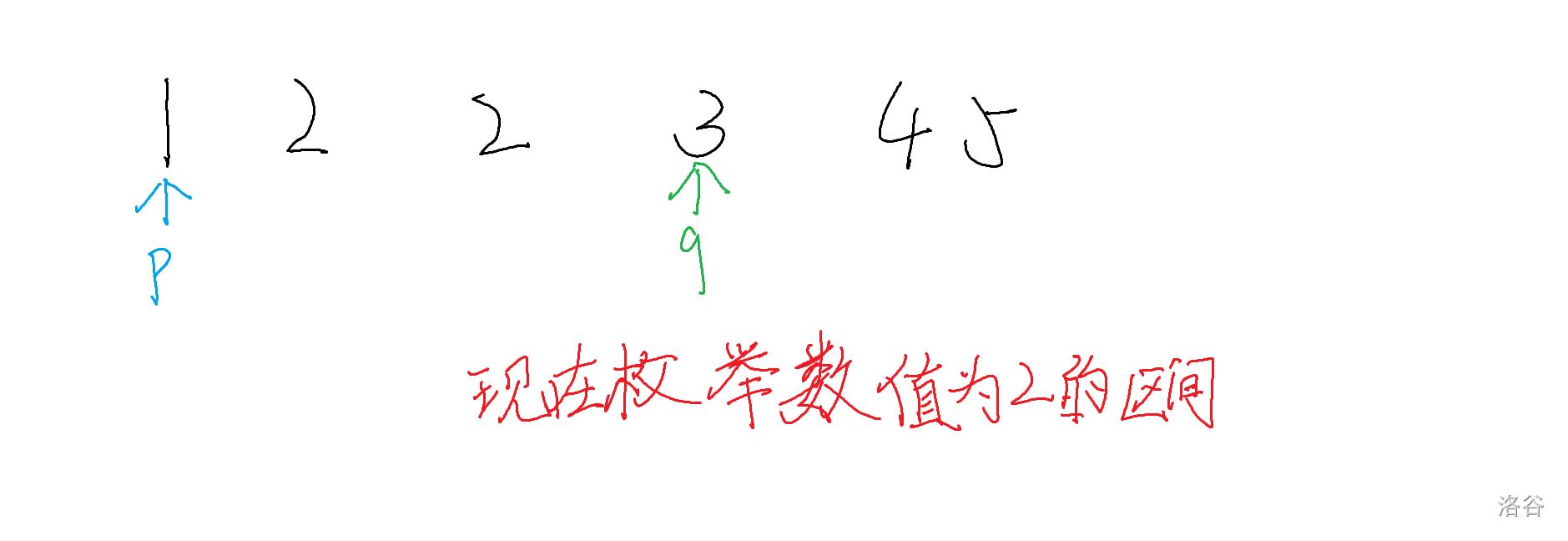
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* head) {
//虚拟结点方便处理头结点被删
ListNode *dummy = new ListNode(-1);
dummy -> next = head;
ListNode *p = dummy;
while (p -> next)
{
ListNode *q = p -> next;
//双指针
while (q && p -> next -> val == q -> val)
q = q -> next;
//只有一个数,第一个指针往后走
if (p -> next -> next == q)
p = p -> next;
//否则全删掉
else
p -> next = q;
}
return dummy -> next;
}
};
好了,这篇题解到这里就结束了,感谢观看,Thanks♪(・ω・)ノ!!!
$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\quad$$\mathcal{writer\enspace by \enspace acwing}$ : $\mathfrak{天元之弈}$

if (p -> next -> next == q)
p = p -> next; 这句话咋理解
因为一开始q = p->next ,while语句里p->next->val == q->val一定成立一次,q就一定会向后移动一位。这时候若没有重复元素,q就在p->next->next这个节点上了。
有个问题,我不太懂,dummy的next一开始时指向head的,循环中也没有改变dummy的next值,为什么【1,1,1,2,3,4】这种情况,dummy的next会变成2呢?不应该是原本head结点的1嘛?不太明白
因为用p=dummy,p指针改变就把dummy的指针指向改了
棒
谢谢