
CS:APP 第一章 计算机系统漫游
我们将通过hello.c的一生开始一次有趣(or not)的计算机系统漫游.
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}
1.1 信息就是位 + 上下文
hello程序在计算机中或者以 文本文件 形式存储(ASSII码), 或者以 二进制形式 存储. 本质上都是用0/1
比特序列标识数据,区分不同数据对象的唯一方法是我们读到这些数据的上下文.
{
int i; unsigned int ui;
i = ui = -1;
cout << i << endl << ui << endl;
}
/* 输出
-1
4294967295
*/
-1的二进制序列对于有符号和无符号的int类型标识的值不同.(这里上下文我的理解是不同的解释规则).
1.2 ‘hello’被其他程序翻译成不同格式
用编辑器写出大名鼎鼎的hello.c程序后, 以 .c 的格式保存. 但为了在系统上运行hello.c,
每条C语句–>低级机器指令, 这些指令按 可执行目标程序 的格式打包好以二进制磁盘文件形式保存起来.
在linux系统上, 只需一条指令即可完成源文件到目标文件的转化.
linux> gcc -o hello hell.c

这个过程分为四个阶段, 四个阶段的程序(预处理器、编译器、汇编器和链接器)构成了编译系统.

- 预处理阶段
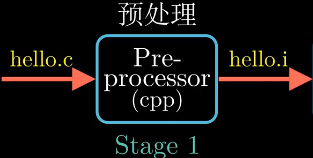
预处理器(cpp)根据字符以#开头命令修改原始C程序.比如hello.c的第一行#<stdio.h>命令告诉预处理器读取
系统头文件stdio.h的内容, 并把它直接插入程序文本中.hello.c–>hello.i - 编译阶段
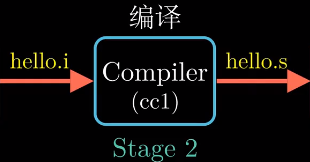
编译器(ccl)将文本文件hello.i翻译成汇编语言程序hello.s. - 汇编阶段
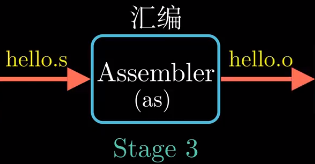
汇编器(as)将hello.s翻译成机器语言指令并打包成 可重定位目标程序(relocatable object program)(?)
的格式, 保存在二进制文件hello.o中. - 链接阶段
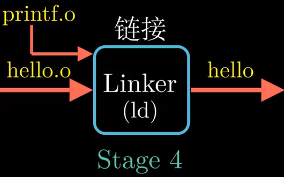
hello程序调用了printf函数,printf函数位于名为printf.o的单独预编译好的目标文件中, 连接器(ld)负责
将printf.o合并到hello.o的程序中, 得到可以运行的可执行文件hello.
1.3 了解编译系统如何工作是大有益处的 (为何要理解)
-
优化程序性能
-
理解链接时出现的错误
-
避免安全漏洞
1.4 处理器读并解释存储在内存中的指令
此时hello.c已经被编译系统翻译成可执行文件hello, 存储在磁盘中. 我们在shell中输入文件名
linux> ./hello
hello, world
linux>
shell 将加载并运行hello程序, 等待hello终止. hello程序在屏幕输出它的消息并终止. shell随后等待后续命令.
为了理解运行hello时发生了什么, 我们需要了解一个典型系统的硬件组织.
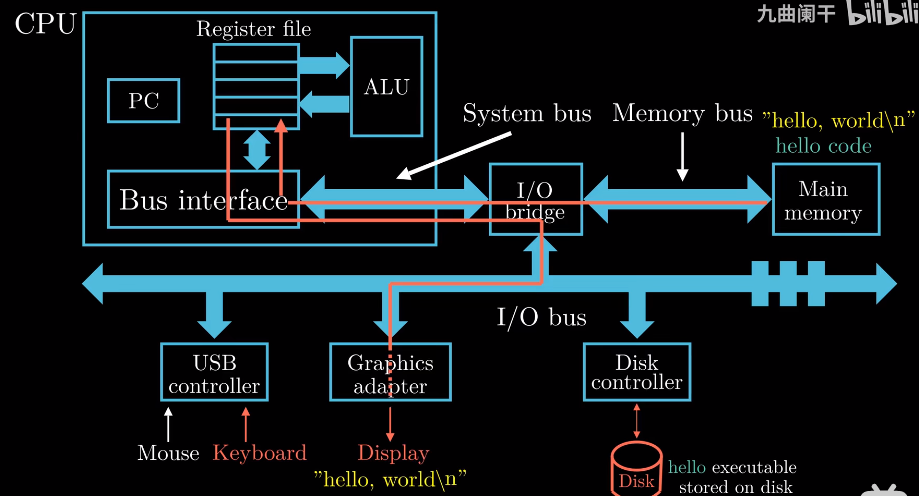
1.4.1 系统的硬件组成
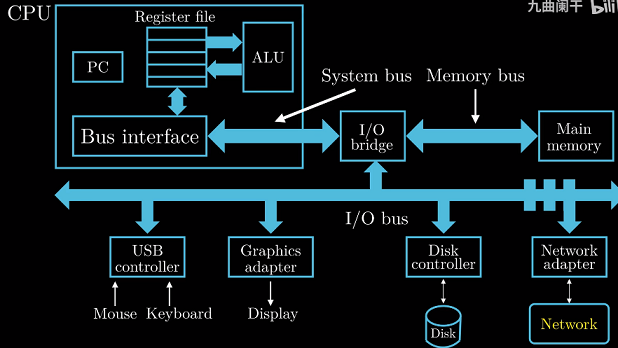
- CPU
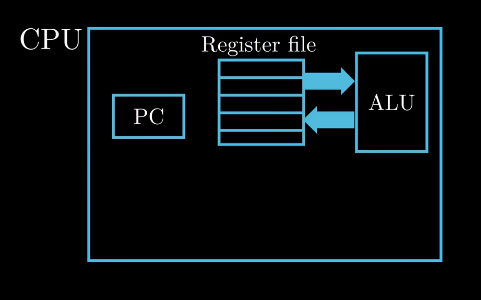
Central Processing Unit, 中央处理单元/处理器. 最终程序的机器指令在这里执行. 我们在这里关注几个
重要的组成部分.
PC Pragram Count, 程序计数器, 一个字单元, 存放将要执行指令的地址.
(字:在本书中字需要根据上下文判断其具体大小)
Register file寄存器文件, 一系列寄存器组成. 寄存器可以看作CPU内置存储器, 每个寄存器用一个名字唯一标识.
ALU Arithmatic/Logic Unit, 算数/逻辑单元, 对数据做算数或逻辑运算.
Else…
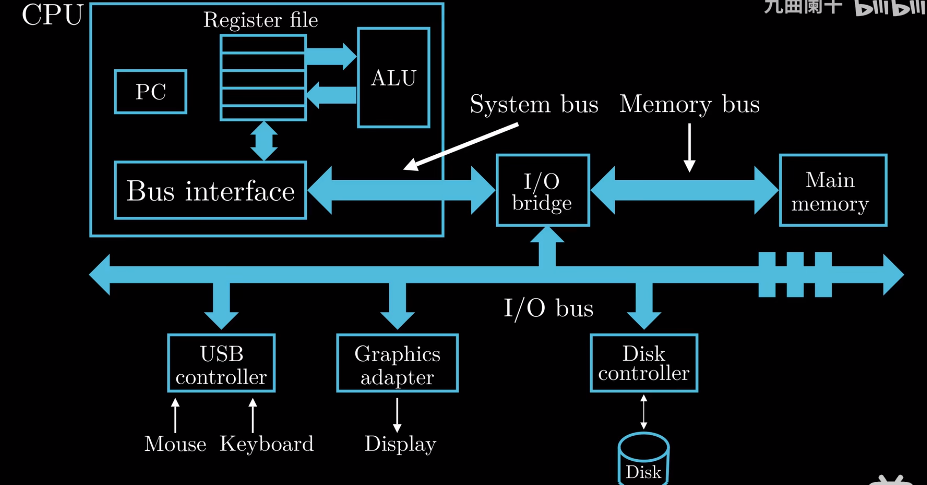
Main memeoy主存/内存, 在程序执行时保存程序的指令和数据.
Bus公交车/总线, 在各个部件之间传递数据
I/O输入输出设备, 如键盘、鼠标以及磁盘等. 每个输入设备通过 控制器 或 适配器* 与IO总线相连.
CPU和内存类似大脑的信息处理部分和记忆存储部分, Bus类似传递信号的神经元, I/O类似我们的感官器官,
与外界交换信息.
1.4.2 运行hello程序
首先我们在shell中输入./hello字符串, shell程序将输入字符串逐一读入寄存器, CPU把hello
这个字符串放入内存memory中.
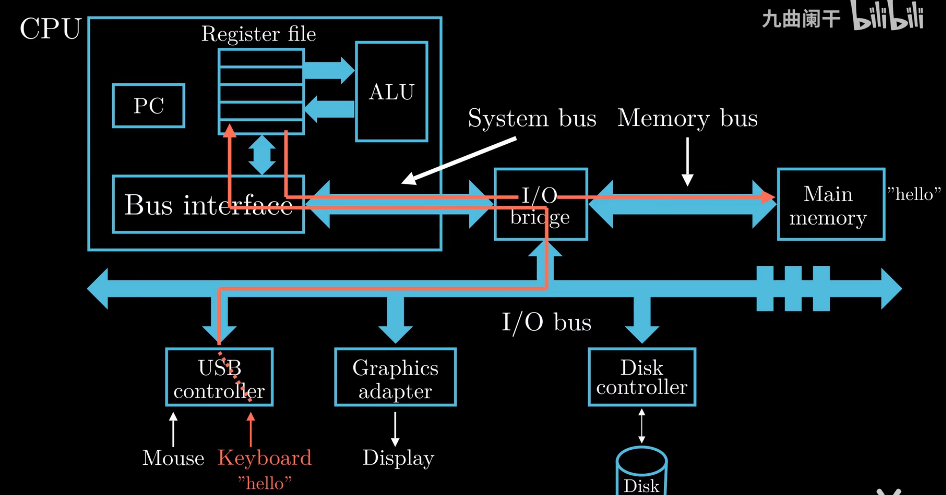
当我们完成输入按下回车时, shell程序知道我们完成了命令输入, 执行一系列指令加载可执行文件hello,
将hello中的数据和代码复制进内存. 数据是我们想要显示的"hello world\n", 这个复制过程会用到DMA
(Direct Memory Access)技术, 数据不经过CPU直接从Disk进入memory. 当hello中的代码和数据被加载入
内存中, CPU开始执行main函数中的指令, main函数只有一个打印功能.
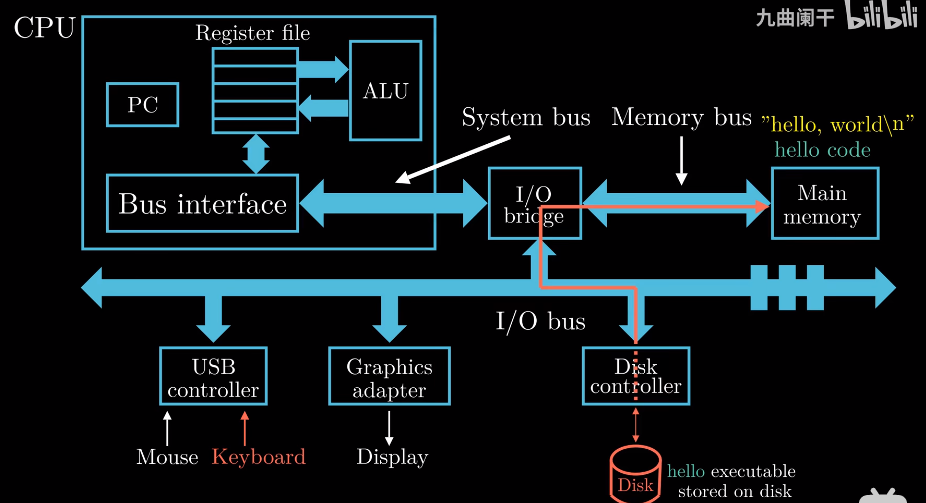
CPU会将"hello world\n"复制到寄存器文件中, 再从寄存器文件到显示设备. 最终hello, world显示在屏幕上.
1.5 高速缓存 Cache Matters
hello执行中数据信息需要在磁盘, 内存, 处理器以及I/O设备间进行搬运. 这揭示出一个问题:系统花费大量时间
把一个信息挪到另一个地方. 系统设计人员的一个主要任务就是缩短信息搬运所花费的时间.
存储设备越大, 花费时间越慢, 但造价相对便宜.

比如一个典型系统上disk比memory大1000倍,但对CPU而言从disk读取一个字的时间开销
比从memory大1000万倍,对于CPU(寄存器文件)和内存同理,并且随着半导体奇数的进步
,处理器与主存间的差距(CPU更快)还在持续扩大.
针对CPU与memory间的差距, 系统设计者采用一个内存介于两者之间的cache作为中间桥梁.
chache : load recent stuff 存储最近可能会用到的信息. 速度介于两者之间, 所为信息流的缓冲区.
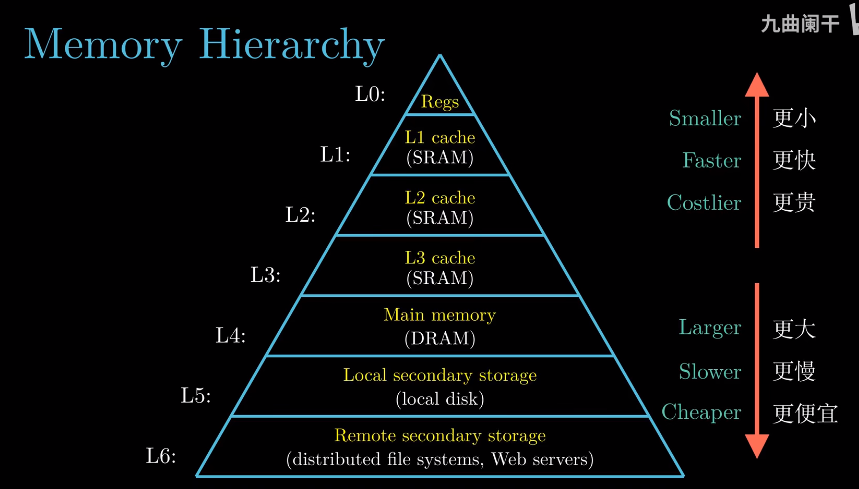
1.6 存储设备形成层次结构
按存储设备的大小, 速度, 和造假的高低可以组织成一个层次结构. 存储器的层次结构的主要思想是上一层的
存储器作为第一层存储器的高速缓存.
1.7 操作系统管理硬件
回到hello, 在shell加载运行hello和hello输出自己的消息时,shell和hello都没有直接访问键盘、显示器、磁盘或者内存. 取而代之的是, 它们依靠 操作系统 提供的服务.
可以把操作系统看成应用程序和硬件之间插入的一层软件, 所有应用程序对硬件的操作都有操作系统来完成.

操作系统作为计算机系统的管理者和魔术师(基本功能)1.管理者 : 防止硬件被失控的程序滥用; 魔术师 : 向
应用程序提供简单一致的机制来控制复杂而通常大不相同的低级硬件设备.
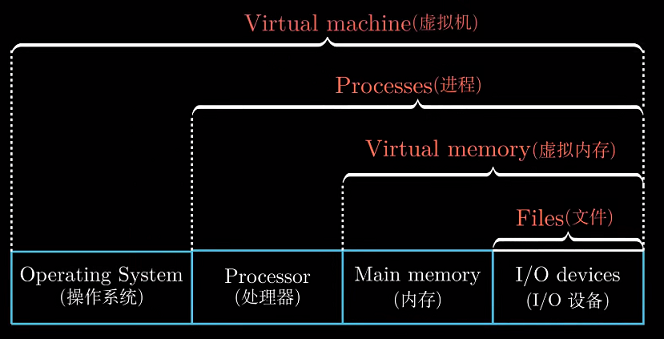
操作系统通过几个基本的抽象概念(进程、虚拟内存和文件)来实现这两个功能.
抽象 : 找到不同对象的共同点. 譬如AcWing上的用户都可以抽象为人类.
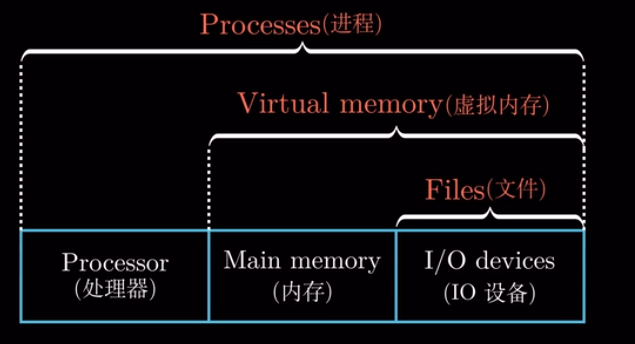
1.7.1 进程
进程是操作系统对一个正在运行的程序的一种抽象. 在一个系统上可以同时运行多个程序, 好像每个程序都
在独占使用CPU和硬件. 事实这是一个CPU通过在不同进程间切换运行实现的, 操作系统实现这种交错执行的
机制称为 上下文切换 .
以shell加载hello的运行为例介绍进程 上下文切换 (Switch Context).
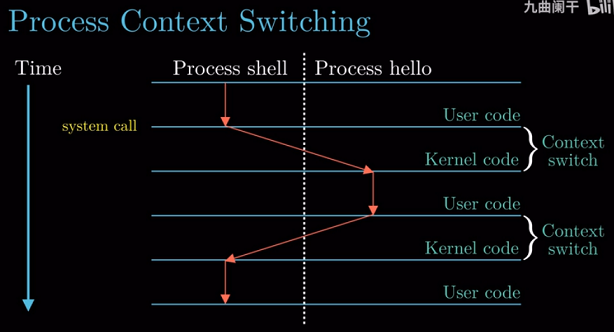
进程切换过程
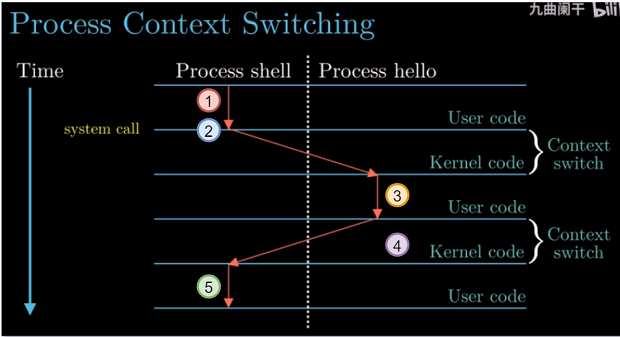
shell运行, 等待命令输入- 用户输入
hello,shell通过系统调用system call执行请求. 系统调用将控制权从shell进程传递给操作系统,
操作系统保存shell进程的上下文, 创建hello进程及其上下文, 将控制权转移给hello进程.(进程切换) hello进程运行.hello进程运行完毕, 操作系统恢复shell进程上下文, 将控制权转递给shell.shell继续运行, 等待命令输入.
上述过程经常提到上下文(context), 上下文是操作系统跟踪运行进程所需的所有状态信息, 比如PC和寄存器在
切换时的值, 以及主存中的内容.
上述进程切换的过程类似于 : 小A和小B需要向语文老师富有感情的背诵诗歌, 先是小A背诵, 如果小A突然忘词
了, 为了节省时间老师让小A记住当时背诵的地方和当时的情感, 接着让小B背诵, 如果小B背诵忘词或者
小B背完了, 那么老师让小B记住(小B忘词)当时背诵的地方和当时的情感, 让小A接着当时的地方继续背诵,
就好像小A一直在向老师背诵, 没有间断过一样.
(例子并不是完美契合进程的切换过程, 只是便于理解)
1.7.2 线程
现代操作系统中, 一个进程实际由多个线程组成, 每个线程运行在进程的上下文中, 共享数据和代码.
1.7.3 虚拟内存
虚拟内存是对内存的抽象, 它给进程提供了一个假象, 即每个进程都在独自占用内存空间. 每个进程看到的
内存都是一致的, 称为虚拟地址内存.
下面以Linux进程的虚拟地址空间为例.
地址从下向上增大, 从0开始.
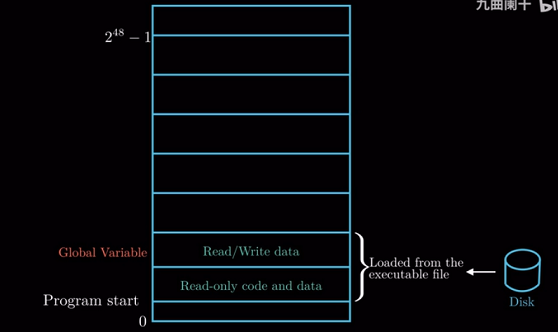
第一个区域用来存放程序的代码和数据, 这个区域的内容由可执行文件加载而来, 如上面的hello. 对于
所有进程来讲, 代码都是从固定的地址开始的. 这个读写数据区域可以存放如C的全局变量等数据.
顺着地址增大的方向, 继续往上看就是堆(heap), C中的malloc函数申请的内存区域就在堆中. 程序的代码和数据区
在程序一开始就指定了大小, 但堆可以在运行时动态的扩展和收缩.
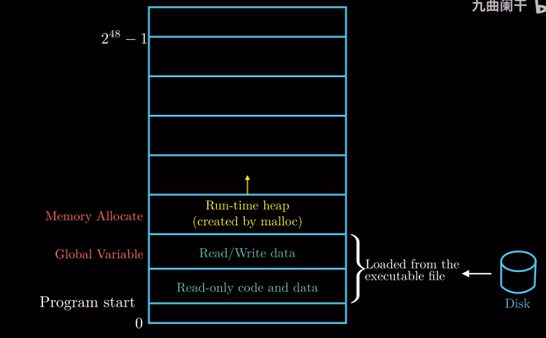
接下来就是共享库的存放区域. 这个区域主要存放像C的标准库和数学库这种共享库的代码和数据, 例如
hello中的printf函数就存放在这里.
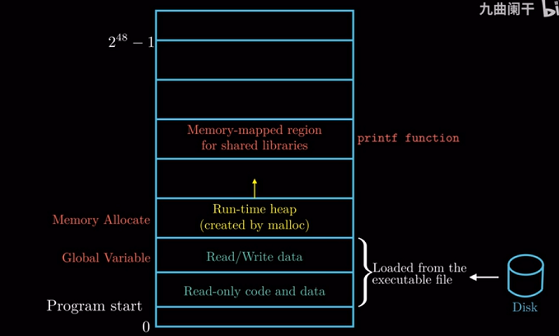
接着我们来到的区域是用户栈(user stack), 程序中的函数调用本质上就是压栈.
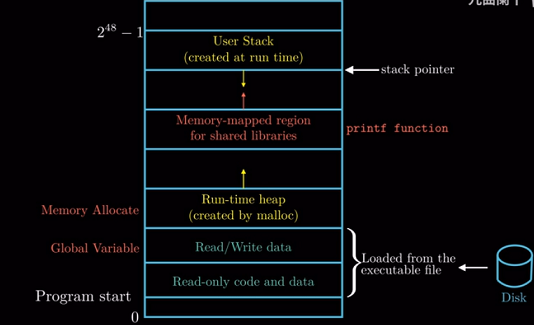
最后我们来到地址空间的顶部, 这个区域是为内核保存的区域, 应用程序不能读写这个区域的数据, 也不能直接
调用内核中的函数, 是应用程序的禁地, 或者说这个区域对应用程序是不可见的.
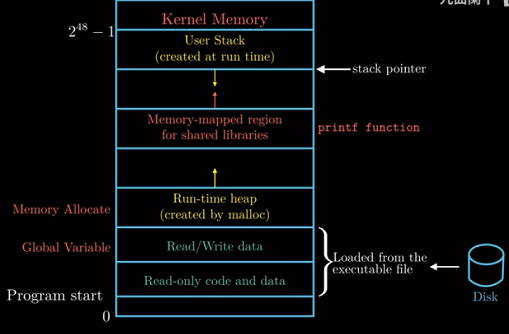
1.7.4 文件
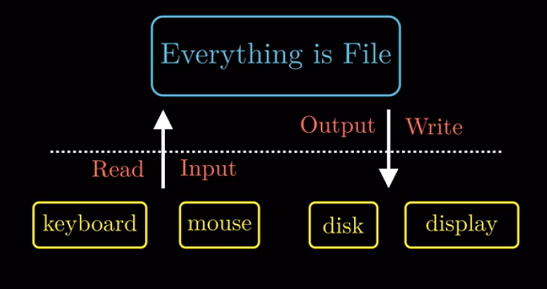
文件就是字节序列, 仅此而已. 所以每个I/0设备, 包括磁盘、 键盘、显示器甚至网络都可以看成是文件.
Linux的哲学 : 一切皆是文件. 系统中的输入输出都可以通过文件读写函数完成.
1.8 系统之间通过网络通信
系统漫游至此, 我们一直把系统视为一个孤立的硬件和软件的集合体. 实际上, 现代系统经常通过网络
和其他系统连接到一起. 从一个单独系统来看, 网络可以视为一个I/O设备.
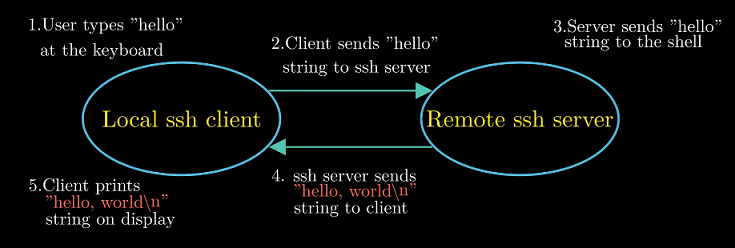
CS:APP以telnet为例讲述如何使用本地计算机的telnet客户端连接远程主机telnet服务器.
由于telnet的安全性问题, 目前ssh的连接方式更普遍, 下面以ssh为例.
通过网络在远程主机上运行hello程序 :
- 在
ssh客户端输入’hello’ ssh客户端将hello字符串通过网络发送到ssh服务端ssh服务端将’hello’发送到远程主机的shell程序shell加载运行hello,将运行结果返回给ssh服务端,ssh服务端通过网络将结果发送给ssh客户端ssh客户端在屏幕上显示运行结果
1.9 几个重要概念
1.9.1 加速比 / Amdahl 定律
阿达姆定律 : 当我们对系统的某个部分加速时, 其对系统整体性能的影响取决于该部分的重要性和加速程度.
假设一个应用程序执行所需时间Told. 假设程序分为两部分, 部分可加速, 占比α. 也就是可加速部分执行
时间为αTold, 不可加速执行时间(1-α)Told.

程序经过优化后, 可加速部分新能提升k倍, 那么加速部分花费时间为αTold / k.
加速后花费时间以及加速比S.

当a = 0.6, k = 3. 加速比S = 1 / (1-0.6) + 0.6/3 = 1.67
我们来考虑一个极限情况, k->INF, 也就是把可以加速的60%加速到几乎不花时间, 此时S = 1 / (1-a).
那么整个系统获得的净加速度也只有2.5. 因此在计算机世界中, 如果我们需要把系统性能提高2倍或更多,
只有通过优化大部分组件才能获得(提高a)
1.9.2 并发和并行
并发 : 一个同时具有多个活动的系统
并行 : 通过并发加快一个系统.
三个层次:(以获得更高的计算能力)
1. 线程级并发
2. 指令级并行
3. 单指令多数据并行
1.9.3 虚拟机
虚拟机是对整个计算机的抽象, 包括操作系统、处理器以及程序.
课程PPT中有趣的部分
Course Theme : Abstraction Is Good But Don’t Forget Reality
1.Ints are not Integers, Floats are not Reals

Ex1 : x2>=0 ?
Float’s: Yes!
Int’s:
int main()
{
int s = 50000 * 50000;
int a = 300 * 400 * 500 * 600, b = 600 * 400 * 500 * 300;
cout << "s = " << s << endl;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
}
/*
*s = -1794967296
*a = 1640261632
*b = 1640261632
*/
在C中, int的平方不一定大于0(溢出), 但仍然满足乘法的交换律与结合律.
EX2 : (x+y)+z=x+(y+z) ?
Int’s: Yes!
Float’s:
int main()
{
double d1 = (2e20 + -2e20) + 3.14;
double d2 = 2e20 + (-2e20 + 3.14);
cout << "d1 = " << d1 << endl;
cout << "d2 = " << d2 << endl;
}
/*
*d1 = 3.14
*d2 = 0
*/
Memery Matters
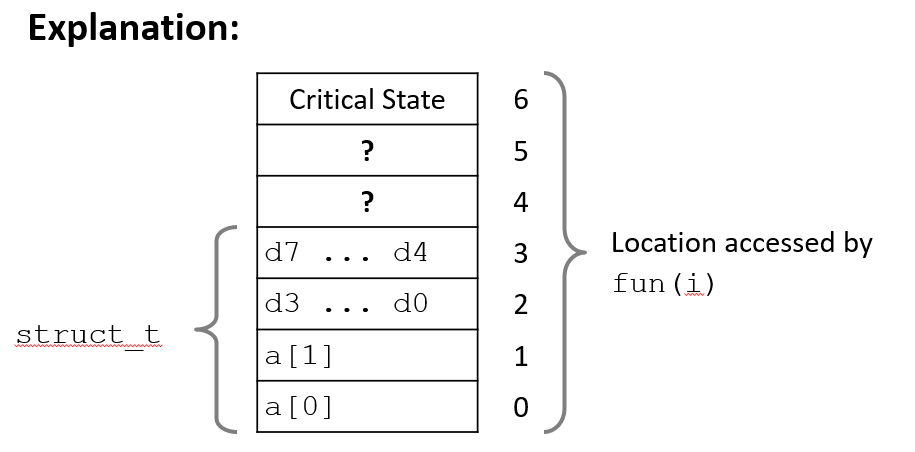
typedef struct
{
int a[2];
double d;
}struct_t;
double fun(int i)
{
struct_t s;
s.d = 3.14;
s.a[i] = 1073741824;
return s.d;
}
/*
fun(0) = 3.140000
fun(1) = 3.140000
fun(2) = 3.140000
fun(3) = 2.000001
fun(4) Segmentation Fault
*/
Memory System Performance Example

相同的执行结果, 只是先行后列还是先列后行的顺序不同, 导致执行速度差了几十倍.

请问 .s 文件这个后缀字母s 是有什么含义或者是什么英文字母的首字母吗. .i是intermediate .o是object
可能和assembly有关, 但我不清楚具体含义是啥 = =
最后一个是不是因为前一个比较容易Cache Hit,后一个容易Cache Miss?
好像是数组元素在内存中是按每行的各列依次排列(a[ i ][ j ]的地址在a[ i ][j + 1]的地址旁边)导致的, 还没看到那 = =
我记得内存本来就是按矩阵存的
不错,加油
关注了,也想好好学学csapp,希望博主持续更新呀!
好的, 加油哦
你,你不会是yxc吧?!
是yxc的粉丝