
AcWing 原博客链接



















前言:本文自己在听 AcWing算法基础课和算法提高课 时精心制作的笔记,涵盖了上课的重点内容以及一些拓展,文后有noip考前注意事项。听说近几年ccf换了出题组,结果现在的题目基本上全是偏思维偏数学,除了搜索dp模拟以外其它算法考的较少(有时候连考纲里的算法也找不到了),常常出现考前复习算法模板压根用不上的情况。所以建议大家在了解掌握了算法的基础上,合理安排时间精力,不必对算法要求过高,一定要注重提高思维能力数学能力(或者说,智商?),例如大家都推荐的CodeForces上就有不少锻炼思维的好题,最后祝福大家能取得理想的成绩,加油!!
♥ I Iove OI ♥
“学习方法?学习方法的话哈就只有一条,啊只有一条,一定要提高自制力,啊这个是万变不离其宗,啊老生常谈的一个问题,只要自制力上去了,一切都不是问题。”——yxc
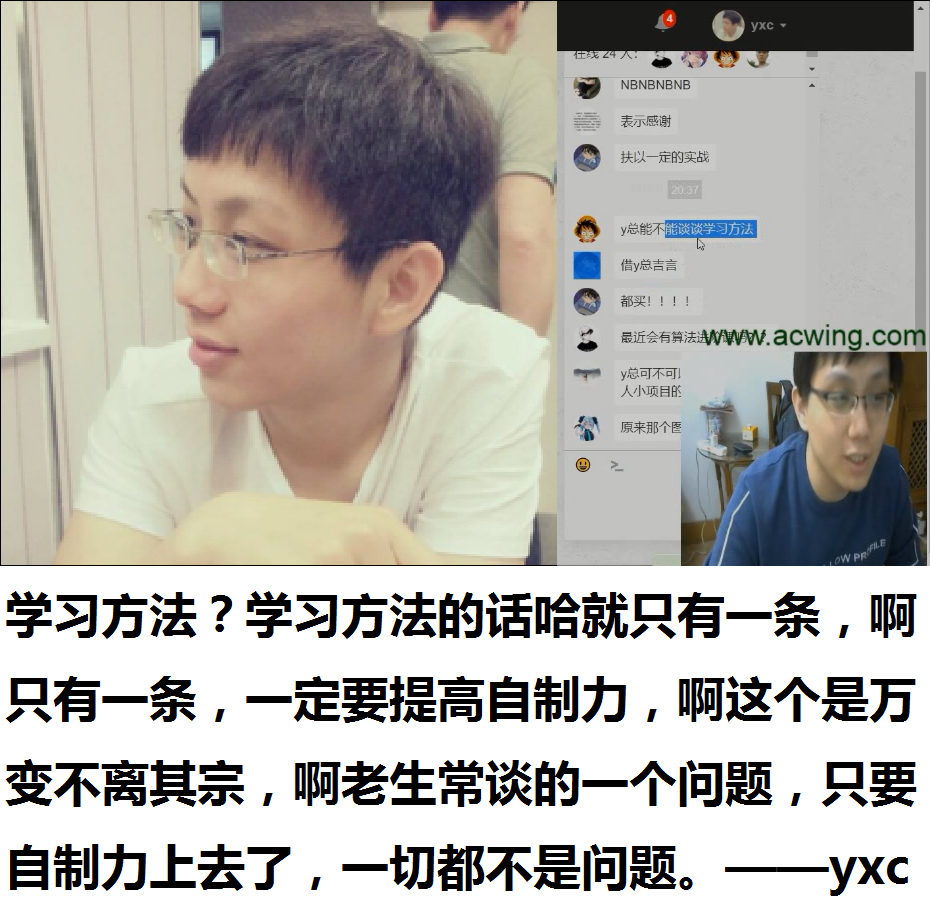
爱了爱了,谨记为人生格言之一qwq~
基础课
基础算法
-
有单调性一定可以二分,没有单调性可能可以二分
二分的本质是边界,区间可以一分为二,一边满足性质,一边不满足性质
求最小的最大,求最大的最小也常用二分 -
双指针:O(N^2)通过一定性质转化为O(N)
-
hash:模数取大于hash数组长度的一个质数(可以提前打表寻找合适的模数),且离2的整数次幂尽量远,删除操作一般不真的删除,打个标记即可
开放寻址法 数组需开2~3倍的空间
拉链法
字符串hash : 1.进制取P=131或13331,模数取Q=2^64(使用unsigned long long自然溢出即可)时,一般不会发生冲突 2.不要把一个字母映射为0 3.可用O(1)时间判断字符串
是否相等
* ≥x的数中最小的一个
while (l < r)
{
int mid = l + r >> 1;
if (a[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
- ≤x的数中最大的一个
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
- 离散化:1.保序:排序判重二分
2.不需保序:map/hash表
N×N的棋盘,N为奇数时,与八数码问题相同。逆序奇偶同性可互达
N为偶数时,空格每上下移动一次,奇偶性改变。称空格位置所在的行到目标空格所在的行步数为空格的距离(不计左右距离),若两个状态的可相互到达,则有,两个状态的逆序
奇偶性相同且空格距离为偶数,或者,逆序奇偶性不同且空格距离为奇数数。否则不能。
也就是说,当此表达式成立时,两个状态可相互到达:(状态1奇偶性==状态2奇偶性)==(空格距离%2==0)。
推广到三维N×N×N:
当N为奇数时,N-1和N^2-1均为偶数,也就是任意移动空格逆序奇偶性不变。那么逆序奇偶性相同的两个状态可相互到达。
当N为偶数时,N-1和N^2-1均为奇数,也就是令空格位置到目标状态空格位置的y z方向的距离之和,称为空格距离。若空格距离为偶数,两个逆序奇偶性相同的状态可相互到达;
若空格距离为奇数,两个逆序奇偶性不同的状态可相互到达。
原文链接:https://blog.csdn.net/hnust_xiehonghao/article/details/7951173
- 【模板】vector + __int128压位高精度
- 数组的函数传参
一维数组
传递数组给函数的3个原则
1.函数调用时只需传递数组名。
2.在函数定义中,形参的类型必须与数组的相同,数组的大小不必指定。
3.函数原型必须定义为参数是一个数组。
二维数组
1.函数调用时只需传递数组名。
2.在函数定义中,必须使用两个方括号以表明数组为二维的。
3.必须指定数组第二个维的大小。
4.函数原型的定义必须与函数头相同。
搜索
-
dfs使用stack,空间为O(h)
bfs使用queue空间为O(2^h) -
BFS具有两段性,单调性 => 最短路性质(当边权相等时,队列递增,相当于dijkstra的优先队列,将其转化为dijkstra即可证明其正确性,第一次搜到即为最短路),适用于求
最小,基于迭代,不会爆栈
当边权不相等时,如0和1,用deque + bfs做时每个点可能入队多次,第一次入队不一定为最优解,当做特殊的dijkstra做即可
当状态空间很大时,bfs的优化(双向bfs和A)才有效果
除朴素bfs每个点只入队一次之外,deque+bfs,A,dijkstra都可能入队多次
- 一个图是二分图当且仅当图中不含奇数边的环
图论
-
树的重心
定义:
一棵具有n个节点的无向树,若以某个节点为整棵树的根,他的每个儿子节点的大小(即子树的节点数)都<=n/2 ,则这个节点即为该树的重心
性质:
删除重心后所得的所有子树,节点数不超过原树的1/2,一棵树最多有两个重心
树中所有节点到重心的距离之和最小,如果有两个重心,那么他们距离之和相等
两个树通过一条边合并,新的重心在原树两个重心的路径上
树删除或添加一个叶子节点,重心最多只移动一条边 -
若图中每个点的出度均为1,则只能构成三种情况:1、一条链;2、一个环;3、一条链连接着一个环。此时求最小环除了Floyd之外还可以用并查集(记录到根的距离,唯一可以
形成环的情况就是链头的元素连到了链中的元素上,每次连边操作都是将一个链头连到另一条链上),搜索,tarjan等方法
在遍历过程中若遇到走过的点,用当前走到的步数减去在此节点原先记录的步数,便得到这个环的长度
- 最短路注重问题的转化和抽象(使原问题的方案和图上的路径一一对应)
| 类型 | 算法 | 时间复杂度 | 备注 | ||
|---|---|---|---|---|---|
| 最短路 | 单源最短路 | 所有边权非负 | 朴素Dijkstra | O(N ^ 2) | 适用于稠密图。基于贪心性质,每次找未拓展的点中dis最小的一个进行拓展,拓展过的点的dis一定是最优解 |
| 堆优化Dijkstra | O((M + N) * log N) | 适用于稀疏图。使用堆优化“找最小”的操作。手写堆可任意修改堆中元素,保证堆的大小不超过N,而使用stl堆会有冗余(用vis标记每个元素,第一次出队拓展后再出队就不再拓展),堆的大小不超过M,但由于M < N^2,logM < 2logN, 所以时间复杂度影响不大 | |||
| 存在负权边,但最短路径上不存在负权回路 | Bellman-Ford | O(NM) | 可用于求经不超过k条边的最短路(SPFA不行)。迭代k次后的dis表示从起点经过不超过k条边到每个点的最短距离,若迭代N次后仍有结点被更新,说明这条最短路径上至少有N条边,则一定是负环(但由于复杂度较高,一般用spfa判断负环) | ||
| SPFA | 一般O(M),最坏O(NM) | 在迭代过程中只有dis[U]改变了,dis[V]才需要更新,故用队列放入每次dis改变的点进行更新,每个点可能进队出队多次,vis表示其是否在队列中。可用于判断负环 | |||
| 多源汇最短路 | Floyd | O(N ^ 3) | dis[i][j]表示所有从i到j,经过节点编号不超过k的路径,可用于求最短路(不能处理负环);传递闭包;找最小环;dis[k][i][j]表示所有从i到j,经过边数恰好为k的路径,用倍增思想优化后可以用O(N ^ 3 * log_2 K)的时间复杂度求恰好(和bellman-ford不同)经过K条边的最短路(可以包含负环) | ||
| 最小生成树 | Prim | 朴素Prim | O(N ^ 2) | 适用于稠密图(邻接矩阵),尤其是完全图 | |
| 堆优化Prim | O(M log N) | 代码不如Kruskal好写,一般不用 | |||
| Kruskal | O(M log M) | 适用于稀疏图,可以合并少于N - 1条边,求最小生成“森林”,也可以在已有连通块的基础上继续求最小生成树。循环到第i条边时可以求出由前i条边(边权<=d[i].w的边)所构成的所有连通块, 每次加边都是将两个连通块进行连通,且此边为新连通块中的最大边 |
- 图上限制次数的操作可以尝试考虑分层图
数学
- 试除法判断质数时循环边界应写成i <= N / i,i <= sqrt(N)效率较低,i * i <= N当N接近int上限时i*i会溢出为负数
- N中最多只包含一个大于sqrt(N)的质因子
- 小于2的整数既不是质数也不是合数
- 质数定理:N足够大时,1~N中有N /lnN个质数(实际范围建议一定要自己根据数据范围验证并更正),而合数很稠密,接近N
- 线性筛原理:
从小到大枚举p[j]
1.if i%p[j] == 0 则p[j]是i的最小质因子,也是p
[j] * i 的最小质因子,标记后即退出循环
2.if i%p[j] != 0 则p[j]一定小于i的最小质因子,p[j]也一定是p[j] * i的最小质因子
注:第二层循环枚举j的时候可以不加上j <= cnt的边界条件,因为i为合数时会在j=最小质因子时停止,i为质数时会在j=i时停止 - a mod b = a - ⌊a/b⌋ * b
- 若a,b互素,则a必然存在模b的逆元;若a,b不互素,则a必然不存在模b的逆元
- 逆元的递推公式inv[0] = inv[1] = 1 , inv[i]=(M-M/i)*inv[M%i]%M (其中M为模数,要求为奇质数)
- ax+by=(a,b)的通解为x = x0 - b/d * k, y = y0 + a/d * k(k为整数)
- 由(a, b) = (b, a % b) ==> ax + by = by’ + (a -a / b * b)x’可以推出exgcd的式子
- 解同余方程ax+by=c的注意事项:
(a,b)是ax+by能凑出来的最小正整数,ax+by一定是(a,b)的倍数(因为a,b都是其倍数)
设d = gcd(a,b), 则d | c时才有解
由于x0 / d不一定能整除,所以不能写成x0 / d * c的形式,而应写成c / d * x0的形式
注意在(ll)c / d * x0的计算过程中转换为ll防止int溢出
通过不断加减b / d可求int范围内的通解,可以用mod (b / d)实现,而加减d 个 b / d就相当于加减一个b,所以mod B肯定也能得到一个解。求最小正整数解用(x0 % P + P) % P,P = abs(b / d); - d = a ^ b ^ c 可以推出 a = d ^ b ^ c.
异或运算还具有消去律:a^b=b^c => a=c,与、或运算均不满足该性质。
现在给你其中有n对数和1个单独的数(一对数指这两个数相等),要求用O(n)的时间找出单独的数,把所有的数字异或起来即可 - EXCRT
- 高斯消元 O(N^3)
- 找主元(为了保证精度应找当前列中各行绝对值最大的数)
- 把当前行与绝对值最大数所在行交换
- 将当前行同除以该数,使该系数变为1
- 将下面各行的当前列系数都减为1
- 从最后一行往前将倒三角矩阵化为对角线矩阵
每个自由变量的每个取值都对应一组解,自由变量的个数就是高斯消元后N - 非零行的个数 - SG定理:游戏和的SG函数等于各个游戏SG函数的Nim和(Nim和:各个数相异或的结果)
多个独立局面的SG值,等于这些局面SG的异或和 - 求多个元素两两乘积之和 = 所有元素和的平方 - 平方和,如2ab+2bc+2ac=(a+b+c)^2-(a^2+b^2+c^2)
其它
-
系统为某一程序分配空间时,所需时间与空间大小无关,与申请次数有关
stl常见用法 见 “算法基础课 第二章 数据结构(三)” -
调试代码常用方法:1.输出中间变量的结果 2.删去(注释掉)一部分代码进行检查
debug之前先通读一遍,过滤掉大多错误 - 每道题写代码调试出现的错误可以标注在代码注释中方便以后再次注意
- 数组越界了什么错误都有可能发生,不一定是段错误或RE
- C++ if 的判断条件,非0即真(负数也为真)
if (A || B) 如果A是真,就不会计算B表达式了
if (A && B) 如果A是假,就不会计算B表达式了 - 对于二进制数i,for (int j = (i - 1); j; j = (j - 1) & i)可以枚举出其所有非全集子集j(改成int j = i即包含了全集),比如 i = (1101)2的时候,j可以枚举到:1101、1100、1001、1000、0101、0100、0001、(0000)
提高课
DP
-
闫氏DP思考法
状态表示:集合与属性(max/min/数量)
状态计算:集合的划分(原则:不漏/一般不重复)
重要的划分依据:最后
看当前是由哪些状态转移过来,或者当前可以更新哪些状态
闫氏最优化问题分析法:
最优化问题可以从集合角度考虑,不重不漏
在一个有限集合中求最值或个数
若是无限集合,常证明最优解在一个有限子集中 -
当状态较少无法转移时可以考虑增加一维状态转移
增加数组的维度,将更多的条件和状态记录下来,有可能更利于进行转移
如果遇见选择或者不选择状态的题目时,可以考虑背包,可以额外用数组的一维0或1表示拿与不拿的状态
背包问题:for物品 for体积 for决策
对于f[i个物品,体积j]=价值w
体积最多是i 初始化全部为0 枚举时体积j>=0
体积恰好是i 初始化f[0,0]=0,f[0,j]=+oo 枚举时体积>=0
体积至少是i 初始化f[0,0]=0,f[0,j]=+oo 枚举时体积可以为负数(>=负数可以转换为>=0)求方案数初始化总结
二维情况
1、体积至多j,f[0][i] = 1, 0 <= i <= m,其余是0
2、体积恰好j,f[0][0] = 1, 其余是0
3、体积至少j,f[0][0] = 1,其余是0
一维情况
1、体积至多j,f[i] = 1, 0 <= i <= m,
2、体积恰好j,f[0] = 1, 其余是0
3、体积至少j,f[0] = 1,其余是0
求最大值最小值初始化总结
二维情况
1、体积至多j,f[i,k] = 0,0 <= i <= n, 0 <= k <= m(只会求价值的最大值)
2、体积恰好j,
当求价值的最小值:f[0][0] = 0, 其余是INF
当求价值的最大值:f[0][0] = 0, 其余是-INF
3、体积至少j,f[0][0] = 0,其余是INF(只会求价值的最小值)
一维情况
1、体积至多j,f[i] = 0, 0 <= i <= m(只会求价值的最大值)
2、体积恰好j,
当求价值的最小值:f[0] = 0, 其余是INF
当求价值的最大值:f[0] = 0, 其余是-INF
3、体积至少j,f[0] = 0,其余是INF(只会求价值的最小值)
作者:小呆呆
链接:https://www.acwing.com/blog/content/458/
-
完全背包:求前缀的属性
多重背包:求“滑动窗口”的属性
拓展:https://blog.csdn.net/qq_35577488/article/details/108932689
https://blog.csdn.net/qq_35577488/article/details/108937340 -
N<=20 可能考虑状压dp
-
状压dp中为避免顺序不同的重复转移,可以预处理出每个二进制数的最后一位0,每次转移时把最后一位0变为1即可(把1变为0也是一样的道理)
-
当一层状态只与前几层状态有关时,可以进行滚动数组优化,注意滚动数组的每一层是否都要初始化
-
数位dp:分成贴合上界和不贴合上界两种情况,不贴合上界情况可以用数学方法直接算或是用f记忆化存储答案(有时可以预处理),贴合上界的情况对下一位继续进行分类
-
单调队列尽量用数组写,deque比较慢
head=0,tail=0或tail=-1皆可
某些题目里队列中的第一个元素很特殊,会取0,那么此时head = tail = 0会表示定义了一个队列,且队列中已经有一个元素0了,而不是定义了一个空队列。 -
斜率优化dp:
怎么在维护的凸包中找到截距最小的点?
相当于在一个单调的队列中,找到第一个大于某-个数的点。
1.斜率单调递增,新加的点的横坐标也单调递增。
在查询的时候。可以将队头小于当前斜率的点全部阳掉。
在插入的时候,将队尾所有不在凸包上的点全部删掉。
2.斜率不再具有单调性,但是新加的点的橫坐标一定单调递增。
在查询的时候,只能二分来找。
在插入的时候,将队尾不在凸包上的点全部删掉。
3.新加的点的橫坐标不再具有单调性,但是斜率一定单调递增。
可以倒序DP,设计一个状态转移方程,让 sumTi是横坐标,sumCi是斜率中的一项。仍然可以用单调队列维护凸壳,用二分法求出最优决策——摘自《算法竞赛进阶指南》第五版327页。
4.斜率、新加的点的橫坐标都不再具有单调性
用平衡树维护(NOI2007) -
在进行状态转移时如果很多转移都没有用,可以进行路径压缩(或称离散化),比如说在线性dp中dp[i] -> dp[j],通过将i->j的距离修改为 (j - i) % lcm(lcm是所有转移步数的最小公倍数)将很长的区间变小,注意看一下dp[j]最后一步是可以由哪些状态转移过来的,这些状态必须在压缩后可以走到(比如人为的再将距离加上一个lcm)
例如 [NOIP2005 提高组] 过河 -
有时候题目中如“每张卡片仅能使用一次”这样的让人以为是搜索回溯的条件也可以转化为“每种卡片最多使用k次”(同一种卡片完全相同)这样的与动态规划相接近的条件
-
数据范围较小时考虑状压dp或搜索
-
用后序遍历求一棵树的dfs序列可用于dp(如有依赖的背包问题,[NOIP2006 提高组] 金明的预算方案),一个点的左兄弟就是dfs进入这个点时dfs序列中的最后一个点
-
AcWing 1086. 恨7不成妻:可用后几位和与后几位平方和推出平方和,如61111^2+62222^2+63333^2 = 3(60000)^2 + (1111^2+2222^2+3333^2) + 260000*(1111+2222+3333)
贪心
-
贪心证明方法:
❶反证法
例如:若最优解不是按从小到大排序,则必然存在相邻两项A,B且A>B
❷A:贪心结果 B:最优解
A=B 即证A<=B 且 A>=B
B<=A 方案合法
A<=B 调整法:
假设A与B方案不同,找到第一个不同的位置,将贪心方案与最优方案等价互换,对结果没有影响,从贪心方案同样能得到最优解(最优解一定能替换成算法所得解)
❸数学归纳法
❹邻项交换法(特别是排序问题)
【贪心做法建议先证明,找反例调试】 -
证明最小值技巧:先证ans>=x,再构造一种方案证可以取等,则最小值为x
-
证明任意一个方法都对应一个解,任意一个解都对应一个方法,两个问题一一对应,包含集合相同
搜索
-
dfs求最小步数:
1.记一个全局最小值
2.迭代加深 -
Floodfill 在线性时间内找到某点所在连通块
-
meet in the middle 适用于状态数量很大的题目,一般是指数级别,复杂度从O(x^n)优化为O(2*x^(n/2)),注意要求搜索图中的节点状态都是可逆的
-
bfs第一次入队为最优解(第一次入队后判重)
dijkstra第一次出队为最优解(第一次出队后判重)
A*:(不需判重)
只有终点能保证第一次出队时为最短距离
除终点之外的点可能被扩展多次 - 栈空间默认是1MB
- 走迷宫模型,每个点只走一次,不需回溯;走状态模型,需要回溯后再走到下一个状态
- 搜索顺序:按“组合”的方式来搜,而不是按“排列”的方式,可以避免重复,比如按下标升序搜索
- 尽量减少搜索树的分支,如“把x加到之前任意一组”改为“每一组都尽量枚举完,把x加到最后一组中”
- 先保证正确性再优化
剪枝:
1.优化搜索顺序(一般优先选择搜索分支较少的节点,要求能搜索到所有方案)
2.排除等效冗余(如按“组合”顺序进行枚举)
3.可行性剪枝(如上下界剪枝)
4.最优性剪枝
5.记忆化搜索 - 迭代加深:适用于分支较深,但答案所在层数较浅,且比bfs所用空间少,且IDA*可以配合迭代加深使用
图论
半欧拉图:只有欧拉路径,没有欧拉回路的图。
判定:
首先是个连通图
如果所有点的度数都是偶数则为欧拉图。
如果只有两个点的度数为奇数,其它点的度数都是偶数,该图为半欧拉图。
寻找欧拉路径和欧拉回路的方法:
从起点出发,若当前点是x,递归走与x点所有相连的没有走过的路径,走完把x按顺序存起来, 最后倒序输出就是欧拉回路。
在半欧拉图中,要求欧拉路径的话,从度数为奇数的点出发就行了。
-
邻接表建图最好先memset(head, -1, sizeof head);
不过memset比较费时 -
乘法最短路
对w1w2w3取log,log(w1w2w3) = logw1 + logw2 + logw3,可转化为一般的最短路问题
当0<=w<1时,logw<0,求log(w1w2w3)的最大值可变形为求(-logw1) + (-logw2) + (-logw3)的最小值,即非负权图上的最短路问题,可用dijkstra
当w>=0时,边权可正可负,用spfa即可 - 邻接表忘记初始化表头可能会导致TLE
- 对于拓扑图最短路, 不管边权正负,均可按拓扑序搜索
- dp大多相当于拓扑图上的最短路问题
当依赖关系存在环不可以用dp,但可以转化为最短路,dp和最短路都可用看成在集合上的最优化问题。
一些dp可以用高斯消元 - dijkstra的适用前提:点第一次出堆即为最优解,不会再被其它点更新,也只有这样才能保证其时间复杂度
bellman-ford的适用前提:最短路经过边数小于n - 1 - 多源多汇最短路可以用超级源点超级汇点
- 分层最短路可以从dp的角度考虑
- 对于边权0和1的最短路,deque+bfs可以保证在最坏情况下仍是线性复杂度
- 求方案数:先求出最优解,再分别求出每个子集中等于最优解的元素个数。DP类型的问题状态更新必须满足拓扑序。对于最短路求解方案数,考虑最短路树(简单考虑可以认为边权都大于0),图上不可能有权值和为0的环(会导致方案数无数种)
求解单源最短路径的算法可以分为三大类:
(1)BFS:每次扩展一层,只入队一次,出队一次,被更新的点的父节点一定已经是最短距离了,并且这个点的条数已经被完全更新过了,一定可以得到拓扑图。
(2)Dijkstra(包含双端队列广搜):每个点只出队一次,第一次出队的时候一定已是最小值了,且已确定最短距离的点不可能再被更新,可以构成拓扑性质
(3)Bellman_ford(spfa):不一定满足拓扑序。因为某个点可能入队多次,出队多次,被更新距离的点也是不确定的。
如果图中存在负权边,可以先使用spfa求出最短路径;然后建立最短路径树,用dis[v] == dis[u] + w[i]在这个树上统计最短路径次数,注意u的最短路径数应当提前算完 -
(最小生成树)如何证明当前边一定可以被选:
假设不选当前边,最终得到一棵树,再把当前边加上,必然出现一个环,在环上一定可以找出一条长度不小于当前边的边,那么将当前边替换上去,结果一定不会变差 -
DAG常用拓扑排序得到遍历顺序,有向有环图可以想到缩点,利用DAG的特性,许多算法在 DAG 上可以有更优/更方便的解。
-
无向图的最小生成树一定是最小瓶颈生成树
- 如果边权可正可负,求将所有点连通的最小边权和,可以把负权边先全部选上再kruskal
- 一定存在一棵次小生成树和最小生成树只有一条边不同,对最小生成树插入非树边删除环上树边的方法可以求严格次小生成树和非严格次小生成树
-
判断负环:常用cnt[x]记录1到x的最短路所包含的边数,若cnt[x] >= N则说明有负环,注意初始化时将所有点都加入队列,dis可初始化成任意值(可以从虚拟源点的角度考虑)。
优化:❶trick:当更新次数超过2 * N时,图中还有可能存在负环,可以直接判断存在,如果N比较小而M比较大的话可能考虑将更新次数上限调大,这是损失一定正确性来优化时间
❷将队列换成栈(不要用stl,用手写,队列下标是递增的,进队次数可能会很多,所以访问到的下标可能很大,需要循环队列。但栈不管插入多少次,最多只会用前n个位置,不需要循环。),或把基于bfs的spfa改成基于dfs,但注意可能严重降低负环不存在时计算最短路的效率 -
差分约束
❶求不等式组的可行解
源点需要满足的条件:从源点出发可以走到所有的边。
步骤:
[1]先将每个不等式xi <= xj + c,转化成一条从xj走到xi,长度为c的一条边
[2]找一个超级源点,一定可以遍历到所有边(可以遍历到所有点则可遍历所有边,反之不一定成立)
[3]从源点求一遍单源最短路
如果存在负环,则无解;如果没有负环,则dis[i]就是原不等式组的一个可行解
❷求最大值或者最小值(这里的最值指的是每个变量的最值)
结论:如果求的是最小值,则应该求最长路;如果求的是最大值,则应该求最短路;(xi <= xj + c可直接用最短路,负环无解;xi >= xj + c可直接用最长路,正环无解,也可转化为xj <= xi + (-c) ; xi = xj可转化为xi <= xj且xi >= xj ; xi < xj可转化为xi <= xj - 1)
可行解只能满足相对大小关系,如果不等式中有绝对值条件xi <= C才可以求最值,对于这样的条件建立一个超级源点0,然后建立0->i,长度是c的边即可。
以求xi的最大值为例:对于所有xi在左边的关系x_i <= x_i-1 + c_i-1都可以放缩:x_i <= x_i-2 + c_i-2 + c_i-1<=…<=x_0 + c_0 + c_1 +…+c_i-1,即x_i <= c_0 + c_1 + c_2 +..+c_i-1,这里的c_0~c_i-1即为从0到i的一条路径上的边,边权和即为xi的一个上界,xi的最大值即为所有上界的最小值,也就是从0到x的最短路;同理,xi的最小值即为从0到x的最长路(若从0到不了i,dis[i] = inf,意味着不等式链有残缺,xi可以取任何值)
若既要判断负环又要求最短路,可以初始化把所有的点都压入队列,但除了dis[1] = 0之外dis都为inf -
tarjan、缩点(可建图)、依据拓扑序递推(用tarjan缩点所得连通分量编号递减的顺序一定是拓扑序)
将有向图变为一个SCC最少需要加max{入度为0的点数,出度为0的点数}条边 -
e-DCC性质
不管删掉哪条边图依然联通
e-DCC <=> 任意两点之间都存在两条不相交(没有公共边)的路径
桥的两个端点不一定是割点
e_DCC中,每个边只会属于一个e_DCC,且桥不会属于任何e_DCC
e-DCC不一定是v-DCC
将无向图变为一个e-DCC最少需要加⌊ cnt + 1 / 2 ⌋条边,其中cnt是叶子节点个数(度为1)
e-DCC缩点后是一棵树(将一棵树变为一个e-DCC 至少增加的边数 =( 这棵树总度数为1的结点数 + 1 )/ 2) -
v-DCC性质
每个割点至少属于两个v-DCC
两个割点之间的边不一定是桥
v-DCC不一定是e-DCC
一个点也是一个v-DCC
->关于Tarjan算法中用dfn不能用low的问题 -
二分图(一般都是无向图,但两点之间只建一条有向边)
一个图是二分图 <=> 图中不存在奇数环 <=> 染色不存在矛盾
最大匹配数 = 最小点覆盖 = 总点数 - 最大独立集 = 总点数 - 最小路径点覆盖 - 字典序拓扑排序可以用优先队列
- 查分约束 求最小值(最长路)
- 边权可正可负 spfa O(KM)
- 边权非负 tarjan O(N + M) 若有解,每个SCC内的边都为0,一旦有正边就会构成正环
- 边权为正 拓扑排序 O(N + M) 一旦有环则无解
- 如果对于两个图N, M,一个图的所有结点都要向另一张图的所有结点连边,总共要连N * M条边,但如在中间加一个虚拟点,左图所有结点向虚拟点连边,右图所有结点向虚拟点连边,则可优化为总共只需要N + M边
- 宽搜的倒序就是拓扑序
数据结构
- 在01区间中求从后往前第一个为0的位置可以用并查集优化
- 并查集常见操作:1.在根节点记录每个集合大小
2.用带权并查集记录每个点到根节点距离(相当于每个点出度为1的有向图)
inline int find(int X){
if (fa[X] == X) return X;
int root = find(fa[X]);//防止多次合并成一条链的情况,必须先更新父节点
d[X] += d[fa[X]]; //d[X]是 X 到 fa[X] 的距离,再加上fa[X] 到 root的距离即可
return fa[X] = root;
}
if (fx != fy){
f[fx] = fy;
d[px] = -d[x] + d[y] + s;
} //注意这里x -> y长为s的边转换成了fx -> fy的一条边
将元素分成k类:1.带边权并查集 记录每个点到根节点距离 维护元素相对关系 时间复杂度与k无关,k较大时宜选择
2.扩展域并查集 将每个元素按分类拆成多个条件,同一个集合中一个条件成立则其它条件也成立 相当于枚举各类情况 每次操作O(k)
区间染色问题:长为n的序列,每次将l到r的数全染成c色,求最终的序列颜色。
我们考虑将染色反着来,则一个数若被染色一次,则这就是它的最终颜色,不会改变。
所以下次若在遇到这个数则需要跳过,也就是对已经染色的区间[l,r],我们令其中的所有数都有一个指针,以指向右边第一个还没有操作的数。
于是我们令fa[i]表示i右边(包括i)第一个没有染色的数,将i染色后,令fa[i] = find(i + 1),用并查集操作即可。
具有无向(或者说双向)的传递性关系(若已知A与B,B与C的关系,则可以推出A与C的关系)可以用并查集或传递闭包,而具有有向的传递性关系只能用传递闭包
敌人的敌人是朋友(例:[NOIP2010 提高组] 关押罪犯)在对敌人进行合并时,注意一定要将find其祖先进行合并,即f[x] = find(enemy[y])
* 循环队列
int hh = 0, tt = 0;
Q[tt++] = X;
...
while(hh != tt){
int U = Q[hh++];
if (hh == maxn) hh = 0;
...
Q[tt++] = V;
if (tt == maxn) tt = 0;
}
-
对顶堆:1.小根堆的所有元素大于等于大根堆的所有元素
2.大根堆的元素个数与小根堆元素个数相等或多1 -
ST表建议预处理log函数省时间,for (int i = 2 ; i <= N ; i++) lg[i] = lg[i >> 1] + 1;
对于st[i][j]=f(st[i][j-1],st[i+(1<<j-1)][j-1]),我们将i,j的顺序调换一下可以提高效率 -
BIT(树状数组)的原数组下标一定要从1开始,它只支持满足“区间减法”的操作,即知道[1, r] [1, l - 1]的信息,就可以推出[l,r]的信息,如区间和,区间异或和,乘积。
树状数组初始化:
1.用update操作 O(NlogN) - 先求前缀和数组S,tr[x] = S[x] - S[x - lowbit(x)] O(N)
- tr[x] = a[x] + [x - lowbit(x) + 1, x - 1]的区间和
for(int x = 1;x <= n;x ++) {
tr[x] = a[x];
for(int i = x - 1;i >= x - lowbit(x) + 1;i -= lowbit(i))
tr[x] += tr[i];
}
二分 + 树状数组可以同时实现平衡树的删除元素和查询第k大元素的操作
线段树是否需要维护额外信息:通过左右子区间的属性能不能算出父区间的属性?
可持久化的前提:本身的拓扑结构不变
Trie的trick,如果空间限制不太够的话,可以根据根据空间限制开trie数组(注意数组空间略小于空间限制)
单词A中单词B出现的次数,其实就是看在A所有的前缀中以单词B为后缀的次数,与next数组类似
- 双队列优化:对一个单调队列中的数进行修改操作后再放入队列,如果修改后不一定是队列最大值最小值(不能确定放队头还是队尾),同时多次操作得到的一系列新数都有序的话,可以再开一个单调队列存储新数,每次的最大值即为单调两队列队尾的最大值
例如“合并果子”问题(哈夫曼树)中的O(nlogn)堆做法就可以优化为O(n)桶排 + 双队列做法 - 一般区间操作首先要想差分
数学
-
用分治可以快速求等比数列之和
-
gcd具有结合律、交换律,gcd(a−nb,b)=gcd(a,b),gcd(a,b)=gcd(a,−b),gcd(a,a)=a,
gcd(ka,kb)=k*gcd(a,b)
当k与b互质,gcd(ka,b)=gcd(a,b),也就是约掉两个数中只有一个数含有的因子不影响gcd。特殊地,当k=2时,可用于高精度求gcd
(a1, a2, a3,…, an) = (a1, a2 - a1, a3 - a2, …, an - a(n-1))可用于差分 + 线段树实现区间加减 + 区间求gcd -
异或和同样可以预处理前缀异或和数组,[l, r]的异或和 = S[r] ^ S[l - 1]
-
1/2 + 1/3 + 1/4 + … + 1/N = ln N + c ≈ logN
1/2 + 1/3 + 1/5 + … + 1/N(分母是质数) ≈ loglogN -
N的因子有d,则也有N/d,设d≤N/d,得d≤√N,即N一定有小于等于√N的因子,利用此性质可以用1~√N的质数的倍数筛出N范围内多个较小区间的质数(二次筛法)。数论中数据范围较大时,常尝试用小范围求出大范围,起到四两拨千斤的作用
-
⌈N / P⌉ * P大于等于N的最小的P的倍数,即(N + P - 1)/ P * P,注:⌈N / P⌉ = ⌊(N + P - 1) / P ⌋ , 上取整和下取整函数为floor和ceil
-
给一个数N分解质因数的最坏时间复杂度是√N
-
N!中因子P的次数为⌊N/P⌋ + ⌊N/P/P⌋ + ⌊N/P/P/P⌋ + … + ⌊N/(P^k)⌋ ( P^k<=N)
- 除了全等数列之外,一个数列的前三项不可能既等差又等比
- 正难则反, 补集思想
- 取模余数在数学定义中是非负的,但C++中负数取模可能是负数,需要先+P再%P转化。取模运算中有减法时一定要注意是否需要转化
-
1~N中所有数的数的约数个数之和为N/1 + N/2 + N/3 + … + N/N ≈ NlogN,int范围内(0≤N≤2147483647)约数最多的数的约数个数为1600个
-
关于约数的题目一般不去对每个数求约数(O(N√N)),而是去考虑其倍数(N / 1 + N / 2 +…+ N / N = O(NlogN))
-
对于y = c / (x + a),a,c为正常数,x,y皆为正整数,要求x的个数,即为求c的约数个数
-
10 ^ 6内有78498个质数
- 当题目没有思路的时候可以尝试想想题目有什么性质
-
lcm(x, y) = x * y / gcd(x, y)
-
求一个数N的因数从1~√N进行枚举需要O(√N),如果先筛出1~√N内的质数,再对N质因数分解,用dfs构造所有约数可以使时间复杂度优化到O(√N / log(N))
- C++中余数的正负与被除数的正负相同,与数学定义有区别
5 % -2 = 1, -5 % 2 = -1, -5 % -2 = -1 - 当相乘结果爆long long,但超出范围不多,相加不爆long long时,可以用龟速乘
- 矩阵乘法具有结合律,不具有交换律。矩阵快速幂中求快速幂的矩阵不能有变量,应把变量化成不带变量系数的式子
-
当dp的每一个状态和上一个状态都有一个线性递推关系,且各项系数不变时,可以用矩阵快速幂优化(当然矩阵不能太大,矩阵乘法的复杂度是O(N^3))
-
快速幂的乘法运算记得先(ll)强转类型
-
求组合数时先看一下数据范围及是否取模,判断是否需要高精度。
当N很大时,C(N, K)可以分解质因数再约分转化为乘法高精度来求。
对于高精度,在数据范围可以的情况下,用递推式只需高精度加法,较好写。
模数为质数时才可以用lucas
当C(M, N)中M很大N很小时,可以直接用定义求组合数效率较高,即M * (M - 1) * … * (M - N + 1) / N!,注意初始化fac[0] = fac[1] = inv[0] = inv[1] = 1,[inv[i]=(M-M/i)*inv[M%i]%M](https://www.luogu.com.cn/blog/zjp-shadow/cheng-fa-ni-yuan) 递推求inv的话还要再进行阶乘 -
求逆元:
一个数有逆元的充分必要条件是gcd(a,p)=1,此时逆元唯一存在
模数为质数时才可使用费马小定理
模数不论是否为质数都可用exgcd,(x0 % p + p) % p即为逆元
递推求逆元注意初始化 inv[0] = inv[1] = 1; [inv[i]=(M-M/i)*inv[M%i]%M](https://www.luogu.com.cn/blog/zjp-shadow/cheng-fa-ni-yuan)
当数较小时分数取模可以用公式(a / b) % p = a % (p * b) / b; -
组合计数:递推法,隔板法,加法原理,乘法原理,排列组合(Lucas, Catania数列/明安图数),容斥原理(补集思想)
- 对于同一直线(斜率不是0或无穷大)上的点,其规律常常与坐标或横纵坐标差的gcd有关,如(a, b)和(c, d)所在直线上,这两点之间的整数格点有gcd(c - a, d - b) - 1个
- 对于不等式组0 ≤ a1 ≤ a2 ≤ … ≤ ak ≤ N, ai是整数,求a序列的方案数
1 . 可以构造差分数组x1 = a1, x2 = a2 - a1, x3 = a3 - a2, … , ak = ak - a(k - 1), 相当于x1 + x2 + x3 + … + xk ≤ N,xi 为非负整数 <===> (对于x为非负整数的问题进行映射,转化为正整数,则可以使用隔板法) (x1 + 1) + (x2 + 1) + … + (xk + 1) ≤ N + k, 即y1 + y2 + … + yk ≤ N + k, yi 为正整数 转化为线性不等式(如果是等号,可以直接用C(N + k - 1, k - 1)),使用隔板法,相当于有N + k个1, 在N + k个空隙(开头不能插,但末尾可以插)中插入k个板,其中第k个板表示其右边的1全部不选,这样就可以使前k - 1个板隔开的数的总和为≤N + k的所有可能的数,方案数即为C(N + k, k)
2 . 将非严格单调递增序列转化为严格单调递增序列,令b1 = a1, b2 = a2 + 1, b3 = a3 + 2, …, bk = ak + k - 1, 则a序列可以映射为0 ≤ b1 < b2 < b3 < … < bk ≤ N + k -1 , 用C(N + k - 1 - 0 + 1, k)
3 . 实际上我们在意的是元素的相对关系,对于L ≤ a1 ≤ a2 ≤ … ≤ ak ≤ R的问题可以映射转化为0 ≤ a1 ≤ a2 ≤ … ≤ ak ≤ N,令N = R - L即可
4 . 如果k不确定,需要枚举的话,需要使用组合数公式C(N + 1, 1) + C(N + 2, 2) + … + C(N + M, M) = (C(N + 1, N + 1) - 1) + C(N + 1, N) + C(N + 2, N) + … + C(N + M, N) = C(N + 2, N + 1) - 1 + C(N + 2, N) + … + C(N + M, N) = C(N + M + 1, N + 1) - 1 - 对于x1 + x2 + … + xn = M, xi ≥ 0
<===> 设yi = xi + 1, y1 + y2 + … + yn = M + n, yi > 0, 隔板法即可,方案数为C(M + n - 1, n - 1) - 卡特兰数的判断:
- 递推式f[n] = f[1] * f[n - 1] + f[2] * f[n - 2] +…, 如二叉树个数
- 挖掘性质:任意前缀中0的个数≥1的个数
C(2n, n) - C(2n, n - 1) = C(2n, n) / (n + 1)
若有f[3] = 5 ,可考虑卡特兰数。
卡特兰数列:1, 2, 5, 14, 42, 132, 429, 1430, 4862, 16796, 58786
斐波那契数列:1、1、2、3、5、8、13、21、34 - 容斥原理常与集合的并集有关,可用二进制枚举所有并集情况,时间复杂度为O(2 ^ N), 题目N的范围一般很小
- 整除分块:用O(√n)求∑⌊n / i⌋,定义使⌊a/g(x)⌋ = ⌊a/x⌋的最大的g(x)(即⌊a/(g(x)+1)⌋ < ⌊a/x⌋)等于⌊a/⌊a/x⌋⌋
- E(aX + bY) = aE(X) + bE(Y)(a,b是X,Y发生的概率,常数项可以直接提出)
期望问题往往起点唯一,终点不唯一,常从终点倒推至起点 - 线性筛素数
void get_prime(int N){
for (int i = 2 ; i <= N ; i++){
if (!vis[i]) prime[++cnt] = i, vis[i] = i;
for (int j = 1 ; prime[j] <= N / i ; j++){ //注意<= N / i这里必须有等号
vis[prime[j] * i] = prime[j];
if (i % prime[j] == 0) break;
}
}
}
- 枚举一个数的所有因数
for(int i=1;i*i<=x;i++)
if(x%i==0){
...
int j=x/i;//得到另一个因子
if(i==j) continue;
...
}
-
gcd(x,a0)=a1 —> a1 | x 且 gcd(x/a1,a0/a1)=1
lcm(x,b0)=b1 —> x | b1 且 gcd(b1/b0,b1/x)=1
(例:[NOIP2009 提高组] Hankson 的趣味题) -
有向无环图上移棋子
一个棋子 先手必胜 <===> SG(S) != 0
多个棋子 先手必胜 <===> SG(S1) ^ SG(S2) ^ … ^ SG(Sk) != 0 -
二项式定理
(a+b)n=∑nk=0Cknakbn−k
(ax+by)k=∑kp=0Cpk(ax)p(by)k−p=∑kp=0(Cpkapbk−p)xpyk−p -
s[i] 表示数字 i 出现的次数,再开一个 ss[i] 数组,数字 i 每出现一次,ss[i] 就加上 i ,然后对 s[i] 和 ss[i] 数组求一遍前缀和。利用前缀和ss[r] - ss[l]可以求出在 (l, r] 区间内所有数的和,用 s[r] - s[l] 可以求出在 (l, r] 区间内所有数的个数,ss[r] - ss[l] - (s[r] - s[l]) * l即可得到所有比 l 大的数都减去 l 得到的总和(AcWing 3993. 石子游戏)
-
[NOIP2014 提高组] 解方程
将一元n次多项式的求值问题转化为n个一次式的算法
需要经过(n+1)*n/2次乘法和n次加法,而秦九韶算法只需要n次乘法和n次加法
其它
字符
- 字符串函数
#include<cctype>
1、isalpha(x) 判断x是否为字母
2、isdigit(x) 判断x是否为数字
3、islower(x) 判断x是否为小写字母
4、isupper(x) 判断x是否为大写字母
5、isalnum(x) 判断x是否为字母或数字
6、ispunct(x) 判断x是否为标点符号
7、isspace(x) 判断x是否为空格
8、toupper(x) 如果x是小写字母,将其转换成大写字母
9、tolower(x) 如果x是大写字母,将其转换成小写字母
#include<string>
1、s.erase(x,y) 表示将字符串s从x位置起删除y个字符
2、s.insert(x,y) 表示将字符串y(或字符y)插入到s的x位置处
3、s.push_back(x) 表示在s的末尾插入字符x
reverse(s.begin(),s.end()) 将字符串s翻转
str.replace(2,4, "ABCD"); //从下标为2的位置,替换4个字节,为"ABCD"
- C++字符串摘录
- s.substr(pos, n)中若pos的值超过了string的大小,则函数会抛出一个out_of_range异常;若pos+n的值超过了string的大小,只拷贝到string的末尾
- char数组函数整理
-
memcpy(d + 1,s + 2,3); 从字符数组d的第1位(最前面一位为第0位)开始,用s字符数组从第2位开始的3位字符覆盖
相当于memcpy(d + 1,s+2sizeof(char),3sizeof(char)); -
“空格+%c”或“%s”能够忽略getchar缓冲区的空白字符
scanf的格式匹配字符串中空格表示空白字符的占位符(任何空白字符都会自动匹配上这个空格,所以相当于这个空白字符被getchar掉了)
而%s则会忽略前导的空白字符
【为了防止空白字符的干扰,即使读入一个字符也建议用%s】 -
字母’A’的ASCII码是41H(0100 0001B),字母’a’的ASCII码是61H(0110 0001B),字母’A’与’a’的二进制后5位是相同的,所以无论是大写字母还是小写字母x,x & 31(1 1111B)的值就是x在字母表里的顺序。
-
对于输入有很多字符的模拟题,如果在线操作比较复杂,可以尝试用字符串保存输入再进行处理
输入输出
- 快读快输
template <typename TT>
void inline rd(TT &x){
x = 0;
TT f = 1;
char ch = getchar();
for ( ; ch < '0' || ch > '9' ; ch = getchar()) if (ch == '-') f = -1;
for ( ; ch >= '0' && ch <= '9' ; x = (x<<3) + (x<<1) + (ch^48), ch = getchar());
x *= f;
}
template <typename TT>
void inline wt(TT x){
if (x < 0) x = ~(x - 1), putchar('-');
if (x > 9) wt(x / 10);
putchar(x % 10 + '0');
}
ios::sync_with_stdio(false) 需特别注意无输出的错位输出的比赛常见错误
- cin解锁(ios::sync_with_stdio(false))不要和scanf 、getchar、puts、gets等混用(会因为缓冲区出现问题)
ios::sync_with_stdio(false);cin.tie(0), cout.tie(0); -
sstream库:stringstream ss 赋值有两种方式, 1. ss(s) ; 2. ss << s; 使用ss可以先接收字符串,再将字符串作为 输入流 >> 转化成整型(会忽略字符串里 的空格、回车、tab)。 缓冲区中,getline(cin, s) 遇到回车会结束接收,并且删掉的回车。
-
对于一些题目需要注意输入数据是否已经排好了顺序*,有时候输入数据并没有说明保证有序,可能需要先sort一遍。建图注意是否有自环重边。注意如果输入(x,y)时需要
x<y,数据会不会出现x>y的情况 - 快读适用于数据量大的,比如 10^6及以上 级别的数据,scanf对中等数据比快读快
快读快输注意0和负数的情况
数据类型
-
能用int尽量不用long long,容易MLE,在计算过程中int强转ll即可
-
unsigned long long的范围是[0,2^64-1],越界以后相当于对2^64求模(遇到范围是2^63,取模2^64的这种题目,要想到用unsigned long long类型)
long long的范围是[-2^63,2^63-1],越上界后会从-2^63开始计数,越下界则从2^63-1开始计数
double可以存储比unsigned long long更大的数字
原因是无符号 long long 会存储精确整数,而 double 存储尾数有限的精度和一个指数。
这允许 double 存储非常大的数字(大约10^308 ),一个 double 中有大约15个(近16个)有效的十进制数字,
也就是说double的精度(15或16位)比long long(19位)位要小,但是double取值范围为 -1.7976E+308 到到-4.94065645841246544E-324,正值取值范围为 4.94065645841246544E-324 到 1.797693E+308。
对于long long
其64位的范围应该是[-2^63 ,2^63],既-9223372036854775808~9223372036854775807。
long double 会保存二进制最高 64 位和指数
double的这种存储方式也就意味着 2 的幂是不会对精度产生影响的
-
double fmod(double x,double y) 返回x除以y的余数。
fmod()用来对浮点数进行取模,设x=k*n+h,则返回值为h(h和x的符号相同)。
%只用于整型的计算,后一个数不能为0;
fmod()可以对浮点型数据进行取模运算,后一个数可以为0,返回NaN(NaN,是Not a Number的缩写,用于处理计算中出现的错误情况,比如 0.0 除以 0.0 或者求负数的平方根)。 -
对于超出unsigned long long范围不是很多的数,可以尝试用long double(取模可以用fmod,注意精度损失,cout默认只保留6位有效数字,应当使用printf(“%LF”),F小写和大写没影响,但是 l 必须大写成L,如果”%LF”无输出,则只好强转double保留15位有效数字)或两个unsigned long long代替高精度
-
lcm为防止溢出,不可先乘后除,而且为保证精度应尽量整除
-
四舍五入可以用
<cmath>中的round函数(保留几位小数可以先乘10的幂再round再除以10的幂)也可以用%.0lf输出,若强转int的话小数部分会直接舍弃
STL
-
非C++11可以用map,但是使用unordered_map(数据存储无序,不保证与插入顺序一致)需要
#include<tr1/unordered_map和using namespace tr1;
unordered_multimap,unordered_set和unordered_multiset同理 -
set的insert不支持返回迭代器,需要二分查找,但multiset可以
typedef multiset<int>::iterator iter;
iter it=s.insert(x);//插入x,并返回x在s中的位置(迭代器)
-
set专有的s.lower_bound(x)比lower_bound(s.begin(), s.end(), x)会更快
-
对于结构体/pair 赋值,a={x,y}是C++11开始才有的语法
旧版本可以这样写:
1.转化为pair类型
a=(pair[HTML_REMOVED]){x,y};
2.调用pair的构造函数
a=pair[HTML_REMOVED](x,y);
3.使用STL中的make_pair函数
a=make_pair(x,y); -
iostream包含
<string>和<utility>(可以使用pair类型)头文件,包含swap,max,min,getline(接收一行字符串,忽略回车符。),不包含freopen(只在[HTML_REMOVED]库中) -
end()指向的是最后一个元素的下一个位置,back()返回的是最后一个元素.类比字符串,end( )返回的是’\0’,back( )返回的是字符串的最后一个字符
优化技巧
-
越在内层循环的数组维度在定义数组时越靠后,能提高运行效率(在连续的存储空间内)(例如ST表的数组,倍增数组注意把指数的一维放在前面)
-
ST表建议预处理log函数省时间,for (int i = 2 ; i <= N ; i++) lg[i] = lg[i >> 1] + 1;
对于st[i][j]=f(st[i][j-1],st[i+(1<<j-1)][j-1]),我们将i,j的顺序调换一下可以提高效率 -
noip可以用exit(0)和goto,但是请谨慎使用。goto 语句可用于跳出深嵌套循环,可以往后跳,也可以往前跳,且一直往后执行。goto只能在函数体内跳转,不能跳到函数体外的函数。即goto有局部作用域,需要在同一个栈内。
-
万能头
include<bits/stdc++.h>(注意有些比赛可能不允许使用) 会增加编译时间,但是比赛评测程序的时间限制指的是运行时间限制,而不是编译时间限制,所以包含万能头文件不会影响到评分。 -
memset使用时要小心,在给char以外的数组赋值时,一般初始化为0或者-1或者0x3f或者-0x3f。
memset -1其实是赋值为NaN,NaN在任何比较运算都返回false -
CLOCKS_PER_SEC可以返回1s内clock()对应值,注意clock()运算速度慢,可以每多少次循环执行一次clock()
-
iostream库中有rand()可以产生0~0x7fff(32367)的随机数,初始化种子srand((unsigned int)time(0))(使用time函数获取系统时间,得到的值是一个时间戳,即从1970年1月1日0点到现在时间的秒数,然后将得到的time_t类型数据转化为(unsigned int)的数
-
建议一次性写好常用头文件,这样就不用写到一半再补加,打断思路)
-
分配空间比较慢,用static可以防止每次重新分配空间
解题技巧
-
编程:思维(数学),编程能力(实践,即手速【非常重要,需要自己练】+正确率)
-
解题注意尝试逆向思维
-
别忘了打表也是一种颇有妙用的算法
-
noip一定要把暴力分部分分拿足
-
看到题目可以先考虑暴力模拟的方法,理解题意,理清思路,然后再根据理想的时间复杂度找到复杂度的瓶颈,对代码各步不断进行优化直到满足要求,注意在空间足够的情况下最好不要为省空间而压缩数组减少变量,在时间复杂度足够的情况下不要使用太多不一定正确而又复杂的优化,码风应清晰,不要压行,尽可能防止自己出错
-
考试注意事项:
保持心态,可以带口香糖之类食物缓解压力,简单题要看清题意先做,很久没有思路就要想方设法写暴力 -
在做题前把细节想清楚,怎么写比较简便
-
对于较大数据范围,如果自己的做法会超时,当数据比较随机时可以尝试trick:减少操作次数,比如人为限定循环执行的次数以保证不超时,期望能得到正确答案
-
对于多个变量的数据范围,可以尝试从小的数据范围找突破口
-
对于O(N ^ 2)优化为O(N):尝试能不能从多层循环枚举多个变量 改为 (使用一些数组存储答案)只枚举一个变量
例如要枚举左右边界,可以考虑通过记录前缀和、记录最后一个合法左边界的位置等方法,使得只需枚举右边界即可解出答案 -
注意部分分,当题目有多个条件时可以考虑满足其中部分条件的做法,再尝试添加一个条件的做法应该如何改进
-
想学好算法,要提高打代码的速度
想学好数学,要提高写字速度,多练习多计算,提高计算能力与熟练度,尤其是高中生
——yxc
暴力强解很重要,与其去想很多技巧,不如去强解,因为强解很快,计算能力足够强就可以掩盖掉很多劣势,技巧跳跃性强,发挥不稳定,不容易想到,而暴力可以规避掉这些风险
——yxc
其它
-
在把数组作为参数传递给函数时,函数的数组参数相当于指向该数组第一个元素的指针,所以不可以通过sizeof运算符得到函数数组的大小,直接用数组大小 * 字节数即可。而对于全局变量和局部变量(如函数内新建的数组)可以直接用sizeof
-
strict weak ordering
stl的相关容器要求严格弱序。
即 a>b 和 b>a 不能同时为真。
stl判断等价用的是 !(a<b) && !(b<a)
所以重载<运算符的时候应判断<,不可判断<= -
矩阵乘法具有结合律不具有交换律
具有结合律的问题可以尝试倍增优化 -
y1, next, prev, has, hash在非c++11中可能会与保留字冲突
-
noip已将栈空间开至内存空间的大小,不需担心爆栈的问题
-
对于二维数组数组名作为形参,函数形参声明一定要至少给出第二个维度的大小
NOIP
-
[洛谷日报#86]OIer 必知的编程技巧
-
OI选手常见作死错误列表
应特别注意ios::sync_with_stdio(false) 无输出的错位输出的比赛常见错误
-
(转)CSP前必须记住的30句话
- guide入门必看文章
- 由数据范围反推算法复杂度以及算法内容
guide推荐字体:Consolas
关闭自动补全,修改括号匹配、背景色、光标行高亮 - 优化技巧
普及组
模拟1: 2004不高兴的津津, 2004花生采集,2005陶陶摘苹果, 2005校i ]外的树
模拟2: 2010按水问题, 2012刀宝, 2016买铅笔, 2018标题统计
枚举1: 2010数字统计, 2010导弹拦截2012质因数分解, 2013计数问题
枚举2: 2014珠心算测验, 2014比例简化,2015扫雷游戏,2016回文日期
字符串处理: 2003兵 乓球,2008ISBN号码,2008立体图,2009多项式输出
排序: 2006明明的随机数, 2007奖学金, 2009分数线划定, 2011瑞土轮
数学: 2003麦森数, 2005循环, 2006数列, 2016魔法阵
贪心: 2004火星 人2007纪念品分组, 2008排座椅, 2015推销员
DP1:
2003数字游戏,2006开心的金明,2007守望者的逃离,2014子矩阵
DP2:
2008传球游戏,2009道路游戏, 2011表达式的值,2012摆花
提高组
模拟: 2003侦探推理, 20104机器翻译, 2015神奇的幻方,2017时间复杂度
二分: 2010关押罪犯 201 1聪明的质检员2012借教室, 2015跳石头
数学: 2009Hankson的计算题, 201 1计算系数, 2016组合数问题, 2017小凯的疑惑
贪心: 2004合并果子, 201 1观光公交2012国王游戏, 2013积木大赛
DFS: 2003传染病控制, 2009靶形数独,201 1Mayan游戏, 2015斗地主
树: 2007树网的核, 2014联合权值,2015运输计划, 2018旅行
图论: 2003神经网络, 2008双栈排序, 2009最优贸易, 2015信息传递
DP1: 2003加分二叉树, 2004合唱队形, 2005过河,2006金明的预算方案
DP2: 2007矩阵取数游戏, 2008传纸条,2010乌龟棋2015子串
DP3: 2016愤怒的小鸟, 2016换教室, 2017宝藏2018保卫王国
好东西:
♥ 我的QQ音乐宝藏歌单 ♥ (强烈安利qwq\~
OIerDb选手成绩资料库
mikutap音乐游戏
graph图论绘图工具
weavesilk对称之美
euclidea尺规作图游戏
arras.io
woomy.arras.io
taming.io
diep.io
florr.io
zombs.io
nightz.io
zombsroyale.io
iogames
在线PS
标准指法练习TT(不一定适合打代码)及安装包
(打代码按键方式建议根据个人习惯喜好)
截屏转换Latex数学公式软件:Mathpix Snip
excel转换markdown 表格制作软件:Typora
markdown latex表格在线生成
sm.ms在线图库
geogebra数学绘图工具
numberempire数学计算器
oeis数列大全
一些还未来的及整理也不会再回来整理的东西
- 善用调试
- noi linux2.0中Geany的快捷键:
缩进和撤销缩进代码块
CRTL + I 缩进
CRTL + U 撤销缩进
2.将代码块注释掉
CRTL + E 注释(再按一次取消注释)
Ctrl (shift)+
Ctrl -
F8,F9,F5 - 分段打表
- namespace的使用
- gnu-pbds
- 带负环最短路计数,标记负环
- manacher算法
- 网页视频
- 入度为0出度为0极大回路
- 生成函数
- 最大团
- 有时候在树上一层一层地操作,可以先按层搜索预处理找出每层的节点
- 在一条线段(序列)上截取一段有长度限制的片段,可以用双指针尺取法
- 正难则反 例:[CSP-S2019] Emiya 家今天的饭
- 没时间打高精度,可以尝试用取模判断尾数的方法期望一定的正确性
sscanf快读中加入取余
clz = __builtin_clz(-num);
ctz = __builtin_ctz(num);
__builtin_popcount(num);
fgets
https://www.cnblogs.com/9527s/p/9332903.html
https://www.cnblogs.com/stayathust/p/3913393.html
https://www.cnblogs.com/bluestorm/p/3168719.html
C语言提供了几个标准库函数,可以将任意类型(整型、长整型、浮点型等)的数字转换为字符串,下面列举了各函数的方法及其说明。
● itoa():将整型值转换为字符串。
● ltoa():将长整型值转换为字符串。
● ultoa():将无符号长整型值转换为字符串。
● gcvt():将浮点型数转换为字符串,取四舍五入。
● ecvt():将双精度浮点型值转换为字符串,转换结果中不包含十进制小数点。
● fcvt():指定位数为转换精度,其余同ecvt()。
函数名: fcvt
功 能: 把一个浮点数转换为字符串
用 法: char fcvt(double value, int ndigit, int decpt, int *sign);
参数:
value:要转换的浮点数,输入参数
ndigit:小数点后面的位数,输入参数
decpt:表示小数点的位置,输出参数
sign:表示符号,0为正数,1为负数,输出参数
string = ecvt(value,ndig,&dec,&sign);
printf(“string = %s dec = %d sign = %d\n”,
string, dec, sign);
除此外,还可以使用sprintf系列函数把数字转换成字符串,其比itoa()系列函数运行速度慢
string/array to int/float
C/C++语言提供了几个标准库函数,可以将字符串转换为任意类型(整型、长整型、浮点型等)。
(跳过前面的空白字符(例如空格,tab缩进等)
● atof():将字符串转换为双精度浮点型值。
● atoi():将字符串转换为整型值。
● atol():将字符串转换为长整型值。
● strtod():将字符串转换为双精度浮点型值,并报告不能被转换的所有剩余数字。
● strtol():将字符串转换为长整值,并报告不能被转换的所有剩余数字。
● strtoul():将字符串转换为无符号长整型值,并报告不能被转换的所有剩余数字。
如n = atoi(itoa(num, str, 2))可以实现十进制转二进制
sscanf sprintf
https://www.cnblogs.com/Anker/p/3351168.html
https://bbs.csdn.net/topics/390306452
pbds
https://baijiahao.baidu.com/s?id=1610302746201562113&wfr=spider&for=pc
注:pbds的哈希表的[]运算符,不知道怎么回事非常占用栈空间不能在dfs中调用,而且慢。相较之下,unordered_map就好很多
rope
https://blog.csdn.net/qq_35649707/article/details/78828560
https://www.cnblogs.com/arcturus/p/9282360.html
// 利用reserve和resize提高vector的效率
// https://blog.csdn.net/qq_37037492/article/details/86568290
https://www.luogu.com.cn/blog/CharlieVinnie/jiang-ji-ge-xiao-hua
文件读写freopen千万别忘 忘了没分
头文件如果对时间复杂度没有苛刻要求就用[HTML_REMOVED]
十分不建议用指针、堆区那些会泄露的
考试提早到
文件名看清楚,不要加多一个后缀名 (比如seix.cpp不要写成seix.cpp.cpp)
善用调试 不会快去学
背模板(高精度、01背包、快读、堆优化迪杰斯特拉等等)
仔细检查考号
变量名建议省去元音字母避免重名
1.缩进和撤销缩进代码块
CRTL + I 缩进
CRTL + U 撤销缩进
2.将代码块注释掉
CRTL + E 注释(再按一次取消注释)
Ctrl (shift)+
Ctrl -
int相乘可能需要ll
分段打表
namespace
https://www.luogu.com.cn/blog/Chanis/gnu-pbds
ext头文件
带负环最短路计数,标记负环
♥ NOIP 2021 RP++ ♥

从2021-07-15到2021-08-09整天都在看基础课提高课视频,暑假爆肝了26天终于看完视频并完成打卡,最后一次noip,希望能竭尽全力吧!
y总经典语录收藏
2021/11/20 从容AFO
感谢一路以来给予我支持和帮助的朋友们,感谢OI所带给我的一切,也祝福所有为之努力的OIer,祝大家幸福快乐~

写太好啦!
赞!!
抓住活的bt7274
神中神 orz
太神了
大佬用一下 MarkDown 和 LATEX 会更好~
哈哈哈y总格言还有语气就太有意思了(你怎么能发语音?)
大佬是已经保送了么
看他博客啊,直接afo了属于是
#### tql
好强哇orz
好文!!!
大佬是怎么学习的呢,是学了一个板块然后做一个板块的题吗,感觉自己的效率好低
不敢称大佬 我是已经有一点基础了然后今年高二参加最后一次noip所以比较赶时间,暑假的时候整天都看看了一个月,每天大概看三四个视频并且做完对应的打卡习题。。当然如果你是新学算法,不赶时间的话,还是要花点时间好好理解的,不用图快,像开学之后的话每个周末能看一个视频并做做习题的话效率就不错了,建议慢慢来,做好习题,打好基础!
我是已经有一点基础了然后今年高二参加最后一次noip所以比较赶时间,暑假的时候整天都看看了一个月,每天大概看三四个视频并且做完对应的打卡习题。。当然如果你是新学算法,不赶时间的话,还是要花点时间好好理解的,不用图快,像开学之后的话每个周末能看一个视频并做做习题的话效率就不错了,建议慢慢来,做好习题,打好基础!
高二,我现在大二算是科班还啥也不会,牛波一
太强了,26天刷完基础提高%%%
不敢不敢,我菜死了
多多做做思考记录很棒的
嗯嗯,谢谢老师鼓励!!