
@TOC
==从Java角度来看,进程是运行时的程序,是计算机分配内存的最小单位。
线程是进程的一个执行单元,是cpu执行的最小单位。==
进程
程序由指令和数据组成,指令的运行,数据的读写需要将指令加载至CPU,数据运行至内存。当一个程序被运行,从磁盘加载这个程序代码至内存,这时就开启了一个进程。进程可以视为程序的一个实例。
线程
一个进程可以分为多个或一个线程。一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给CPU执行。Java中,线程作为最小调度单位,进程作为资源分配的最小单位。在windows中,进程是不活动的,只作为线程的容器。
并发(concurrent):同一时间应对多件事情的能力。(线程轮流使用CPU)
并行:同一时间动手做多件事情的能力。
如何创建线程?
1. 继承Thread类,重写run()方法
2. 实现Runnable接口,重写run方法,再创建Tread对象,去执行任务
1和2的区别:继承Thread类后,由于java是单继承的,所以就不能再继承其他类了,实现Runnable接口的方式,还可以再继承其他类
3. 实现Callable接口,重写call方法,创建Thread对象,去执行任务(call方法可以有返回值,可以抛出异常)
4. 线程池创建
线程中常用的方法:run(),start(),join(),yield(),sleep(),wait(),notify()
线程的状态:新建,就绪,运行,阻塞,死亡
多线程安全问题:多线程共享资源操作
如何解决线程安全问题?加锁,排队,一个一个来, 并发的执行
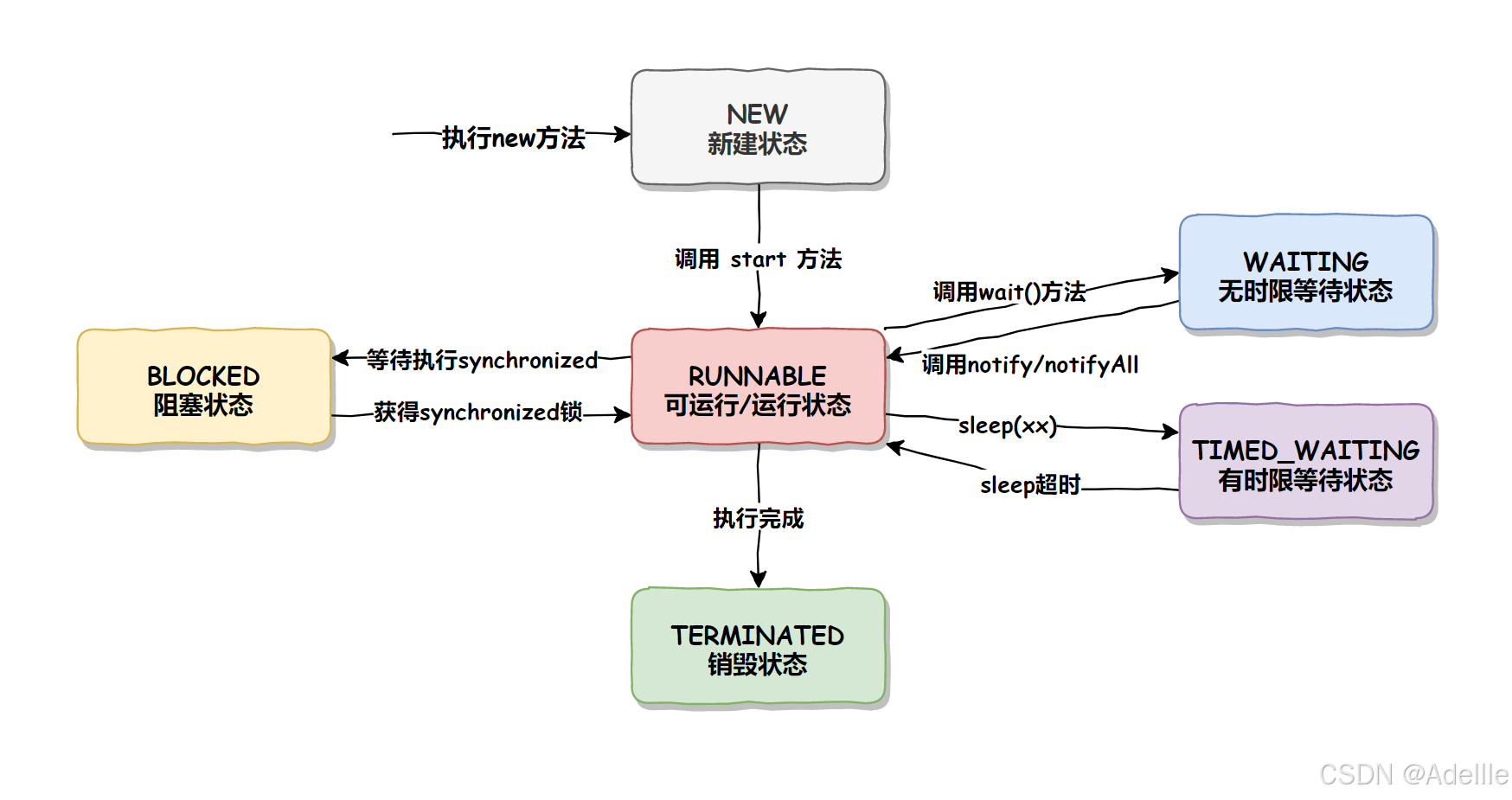
如何加锁:
1. synchronized关键字:同步对象(对多个对象来讲必须是同一个),用来记录有没有线程进入到同步代码块中。可以添加在代码块上,还可以添加在方法上。
synchronized(同步对象){
同步对象要求:多个线程对应的是同一个对象,用对象头中的一块区域来记录有没有进入到同步代码块中
}
synchronized修饰方法时,锁对象有两种:
1.修饰的是非静态方法,锁对象默认是this
2.修饰的是静态方法,锁对象是该类的Class对象
static synchronized void fun(){
}
Lock接口,ReentrantLock类实现了Lock锁,它拥有了与synchronized相同的并发性和内存语义,在实现线程安全的控制中比较常用的是ReentrantLock,可以显式加锁,释放锁。
ReentrantLock实现了Lock接口,所以可以成为Lock锁。
synchronized和ReentrantLock的区别:
- 实现原理不同: ReentrantLock是一种Java代码层面的控制实现,而synchronized是关键字,依靠的是底层编译后的指令实现。
- 加锁范围不同:ReentrantLock只能对某一代码块加锁,而synchronized可以对某一代码块或者方法加锁
- 加锁,释放锁方式不同: ReentrantLock需要我们手动释放锁,而synchronized是隐式自动释放锁(代码执行结束或出现异常,自动释放锁)。
线程死锁
死锁:不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。
出现死锁后,不会出现异常,不会出现提示,只是所有的线程都处于阻塞状态,无法继续。
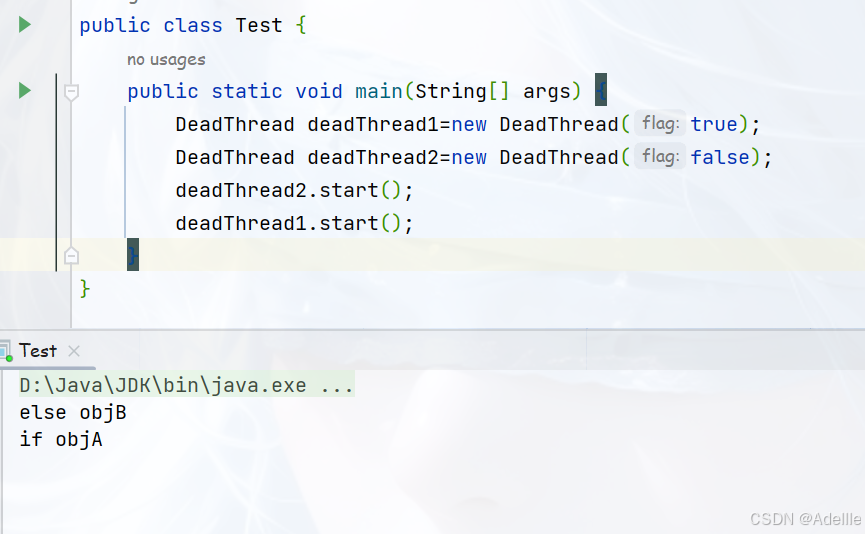
public class DeadThread extends Thread {
static Object objA = new Object();
static Object objB = new Object();
boolean flag;
public DeadThread(boolean flag) {
this.flag = flag;
}
@Override
public void run() {
if (flag) {
synchronized (objA) {
System.out.println("if objA");
synchronized (objB) {
System.out.println("if objB");
}
}
} else {
synchronized (objB) {
System.out.println("else objB");
synchronized (objA) {
System.out.println("else objA");
}
}
}
}
}
设计时考虑清楚锁的顺序,尽量减少嵌套的加锁交互数量。
守护线程
线程分为用户线程和守护线程,守护线程为其他线程提供服务的,最大的特点是当系统其他用户线程结束后,守护线程会自动结束。jvm垃圾回收线程就是一个守护线程
daemonThread.setDaemon(true);
//设置线程为守护线程,必须在线程启动前设置
线程通信
线程通信:指多个线程通过相互牵制,相互调度,即线程间的相互作用。
涉及三个方法:
.wait一旦执行此方法,当前线程就进入阻塞状态,并释放同步监视器。
.notify一旦执行此方法,就会唤醒被wait的一个线程,如果有多个线程被wait,就会唤醒优先级最高的那个。
.notifyAll一旦执行此方法,就会唤醒所有被wait的线程。
注意:wait(),notify(),notifyAll()三个方法必须使用在同步代码块或同步方法中。
两个线程交替打印1-100数字:
public class PrintNumThread extends Thread {
static int num = 1;
static Object obj = new Object();
@Override
public void run() {
while (num <= 100) {
synchronized (obj) {
obj.notifyAll();
System.out.println(Thread.currentThread().getName() + ":" + num);
num++;
try {
if (num <= 100) {
obj.wait();
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
}
sleep()和wait()的区别:
sleep()是让线程阻塞指定时间,时间到了之后自己唤醒进入到就绪状态,不会释放同步锁。是Thread类中的方法.
wait()让线程进入等待(阻塞),不会自己唤醒,必须通过notify/notifyAll来唤醒。是Object类中的方法
共同点:都可以让线程进入阻塞状态。
生产者消费者问题
public class Counter {
int num = 0;
public synchronized void add() {
if (num == 0) {
this.notify();
num = 1;
System.out.println("生产者生产了一个资源:" + num);
} else {
try {
this.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
public synchronized void sub() {
if(num==0){
try {
this.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}else{
this.notify();
num = 0;
System.out.println("消费者消费了一个资源:" + num);
}
}
}
-------------------------------------------------------
public class Producter extends Thread{
Counter counter;
public Producter(Counter counter) {
this.counter = counter;
}
@Override
public void run(){
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
counter.add();
}
}
}
---------------------------------------------------
public class Consumer extends Thread{
Counter counter;
public Consumer(Counter counter) {
this.counter = counter;
}
@Override
public void run(){
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
counter.sub();
}
}
}
---------------------------------------------------------
public class Test {
public static void main(String[] args) {
Counter counter=new Counter();
Consumer c = new Consumer(counter);
Producter p = new Producter(counter);
c.start();
p.start();
}
}
新增创建线程方式
实现Callable接口与使用Runnable相比,Callable功能更强大些
- 相比run()方法,可以有返回值
- 方法可以抛出异常
- 支持泛型的返回值
- 需要借助FutureTask类,获取返回结果
public class Test {
public static void main(String[] args) {
SumTask sumTask = new SumTask();
FutureTask<Integer> futureTask = new FutureTask(sumTask);
Thread thread = new Thread(futureTask);
thread.start();
Integer integer = null;
try {
integer = futureTask.get();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
System.out.println(integer);
}
}
---------------------------------------
public class SumTask implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum=0;
for(int i=0;i<=10;i++){
sum+=i;
}
return sum;
}
}
线程进阶
多线程优点:提高线程响应速度,可以多个线程各自完成自己的工作,提高硬件设备的利用率。
缺点:在多个线程同时访问共享数据时,可能出现资源争夺问题。线程中的重点就是解决线程安全问题。(接下来解决的重点问题)
并发执行:是在一个时间段内依次轮流执行(微观串行,宏观并行)
并行执行:是真正意义上的同一时间点上一起执行
多线程场景下,对共享资源的访问应该是并发的执行
平常所说的高并发,此处指的并发,就是很多用户一起访问
并发编程核心问题:不可见性、乱序性、非原子性
不可见性
一个线程对共享变量的修改,另一个线程不能立刻看到,我们称为不可见性。
由于想让程序响应处理速度更快,java内存模型设计有主内存和工作内存(线程使用的内寸),线程中不能直接对主内存中的数据进行操作,必须将主内存数据加载到工作内存(本地内存),这样在多核CPU下,就会产生不可见性。
我们的目标要做到可见性
volatile关键字(解决不可见性、乱序性)
一旦一个共享变量被volatile关键字修饰以后,
- 保证了不同线程对这个变量操作的可见性,即一个线程修改了某个变量的值,这个新值对其他线程来说立即可见;
(可见性)- 禁止进行指令重排序;
(有序性)- volatile不能保证对变量操作的原子性。
(非原子性)
volatile的底层实现原理(待更新...)
JMM(待更新...)
乱序性
指令在执行过程中,为了优化性能,有的时候会改变程序中语句的先后顺序。
这种改变可能会影响程序整个运行结果。
CPU的读等待同时指令执行是CPU乱序执行的根源。读指令的同时可以执行不影响其他指令。
非原子性
线程切换带来的非原子性问题。
原子的意思代表不可分。一个或多个操作在CPU执行的过程中不被中断的特性,我们称为原子性。原子性是拒绝多线程交叉操作的,不论是多核还是单核,具有原子性的量,同一时刻只能有一个线程对它进行操作。
CPU能保证原子操作是CPU指令级别的,而不是高级语言的操作符。线程导致了原子性问题。
如何保证原子性(加锁、原子变量)
同一时刻只有一个线程执行,我们称为互斥。如果我们能够保证对共享变量的修改是互斥的,那么就能保证原子性了。
- 加锁是一种阻塞式方式实现
- 原子变量是一种非阻塞式方式实现
加锁
互斥的,A线程执行时加锁,此时其他线程就不能再执行了
原子变量
在java.util.concurrent包下面提供了一些类,可以在不加锁的情况下实现++操作的原子性。这些类称为原子类AtomicInteger。
原子类内部实现是volatile+CAS机制
原子类内部实现使用了不加锁的CAS机制
CAS(compare-and-swap)算法:比较并交换
CAS算法:是一种不加锁的实现(乐观锁)机制,采用自旋的思想,当一个线程进行++操作时,可先从内存中取出共享变量,记录一个预估值,然后在工作内存中修改共享变量,当将修改的变量写回主内存前,要判断预估值是否与主内存中的值一致,如果一致说明没有其他线程修改过。如果不一致,说明其他线程修改过,需要重新获取主内存共享变量,重复之前的操作。
CAS缺点:CAS使用自旋的方式,由于该锁会不断循环判断,因此不会类似synchronized线程阻塞导致线程切换。但是不断的自旋,会导致CPU的消耗过高。
原子类适合在低并发情况使用
会产生ABA问题(A->B->A):一个线程获取内存值为A,当线程修改后要写内存时,但已经有其他线程改变了内存值,又有线程将内存值改回到与当前预估值相同的值。
如何解决ABA问题?使用有版本号的原子类
Java中的锁分类(synchronized、ReentrantLock、ReentrantReadWriteLock)
Java中有很多锁的名词,这些并不全指锁,有的指锁的特性,有的指锁的设计,有的指锁的状态。
乐观锁/悲观锁
乐观锁
乐观锁认为对于同一个数据的并发操作,是不会发生修改的。乐观锁其实就是不加锁。并发修改时,进行比较,满足条件进行更新,否则再次比较。例如原子类。
悲观锁(例如synchronized)
悲观锁认为不加锁的是肯定会出问题的,使用java中提供的各种锁实现加锁。悲观锁适合写操作比较多的情况,乐观锁适合读多写少的情况。
可重入锁
当一个线程进入到一个同步方法中,然后在此方法中要调用另一个同步方法,而且两个方法共用同一把锁,此时线程是可以进入到另一个同步方法中的。
读写锁
ReentrantReadWriteLock可以实现读锁和写锁,读写可以使用一个锁实现,都是读的时候,多个线程可以共享这把锁(可以同时进入),一旦有写的操作,那么就要一个一个操作
读读共享
读写互斥
写写互斥
加读锁是防止在另外的线程在此时写入数据,防止读取脏数据
分段锁
JDK8之后去除了真正的分段锁,现在的分段锁不是锁,而是一种实现思想。
分段锁并非一种实际的锁,而是一种思想。用于将数据分段,并在每个分段上都会单独加锁,把锁进一步细粒度化,以提高并发效率。
例如ConcurrentHashMap,没有给方法加锁,而是用hash表中第一个节点当作锁,这样就可以有多把锁,提高并发效率。
自旋锁
也不是锁,是获取锁的方式。例如:
- 原子类,需要改变内存中的变量,需要不断尝试
- synchronized加锁,其他线程不断尝试获取锁
共享锁/独占锁
共享锁
多个线程可以共享的一把锁,读写锁中的读锁,都是读操作时多个线程共用一把锁
独占锁
synchronized、ReentratLock,互斥的,读写锁中的写锁
公平锁/非公平锁
公平锁
公平锁(Fair Lock)是按照请求锁的顺序分配,拥有稳定获取锁的机会。
非公平锁
非公平锁(Nonfair Lock)是指不按照请求锁的顺序分配,不一定拥有获取锁的机会。
synchronized是一种非公平锁
ReentrantLock默认非公平锁,但是底层可以通过AQS来实现线程调度,所以可以使其变成公平锁。
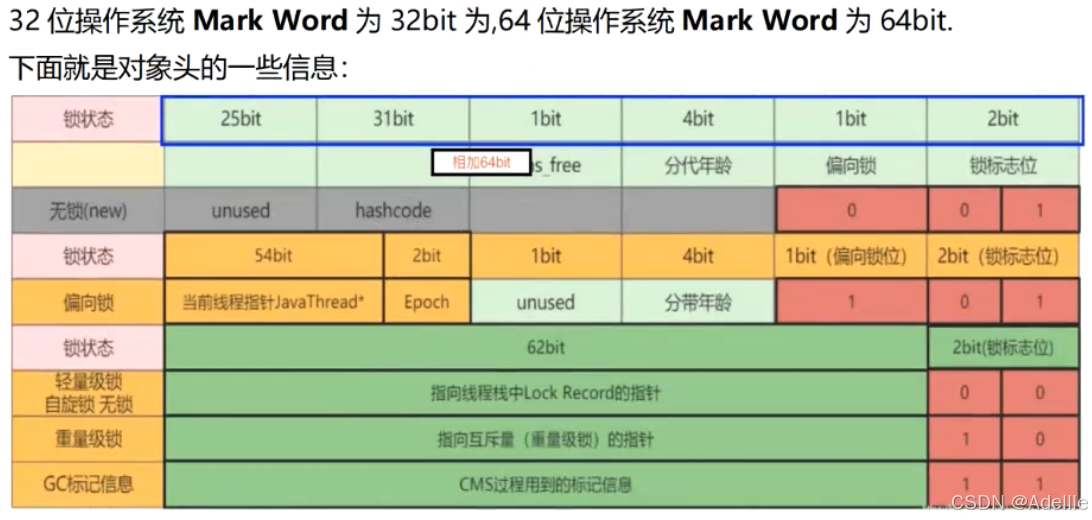
偏向锁/轻量级锁/重量级锁(锁的状态)
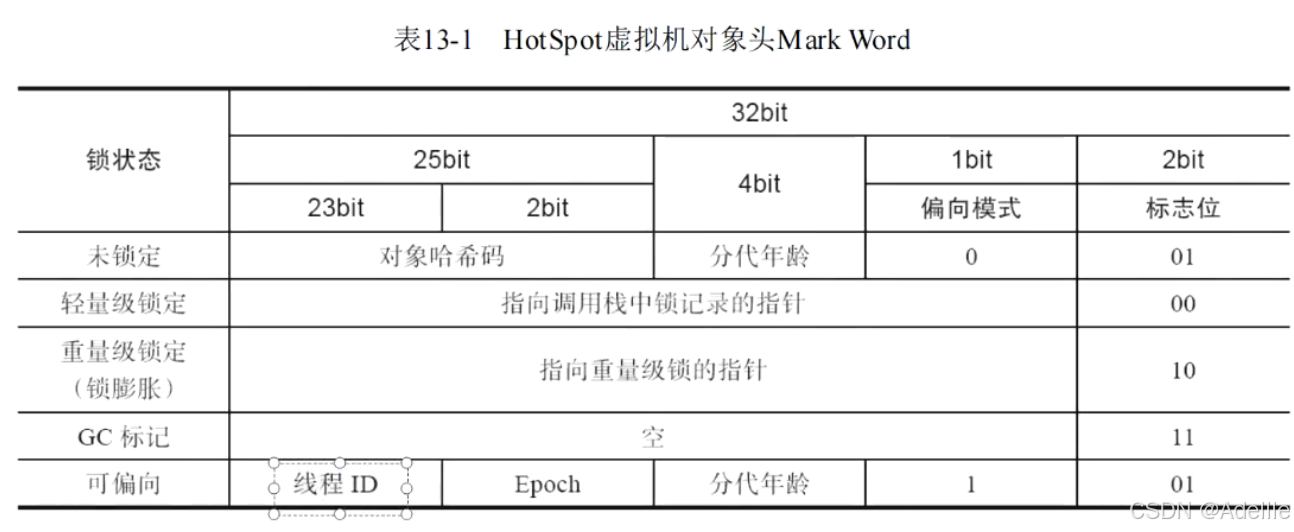
是针对synchronized锁的状态:
无锁状态:没有任何线程进入同步代码块偏向锁状态:当前只有一个线程访问,在对象头的Mark Word中记录线程id,下次此线程访问可直接获取锁轻量级锁状态:锁状态为偏向锁,此时继续有线程访问,升级为轻量级锁,会让线程以自旋方式获取锁,线程不会阻塞重量级锁状态:锁状态为轻量级锁,线程自旋获取锁的次数到达一定数量时,锁的状态升级为重量级锁,会让自旋次数多的线程进入到阻塞状态,因为访问量大,线程都自旋获得锁,CPU消耗大
锁的状态是通过对象监视器在对象头中的字段来表明的。四种状态会随着竞争的情况逐渐升级。
这四种状态都不是Java语言中的锁,而是JVM为了提高锁的获取与释放效率而做的优化(使用synchronized时)
偏向锁
偏向锁是指一段同步代码块一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
轻量级锁
轻量级锁是指当锁是偏向锁的时候,此时又有一个线程访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋形式尝试获取锁,不会阻塞,提高性能。
重量级锁
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。在高并发情况下,出现大量线程自旋获得锁,对CPU销毁较大,升级为重量级锁后,获取不到锁的线程将阻塞,等待操作系统的调度。
以上状态设计是Java为了优化synchronized锁
对象结构
synchronized锁的实现(通过底层指令控制实现)
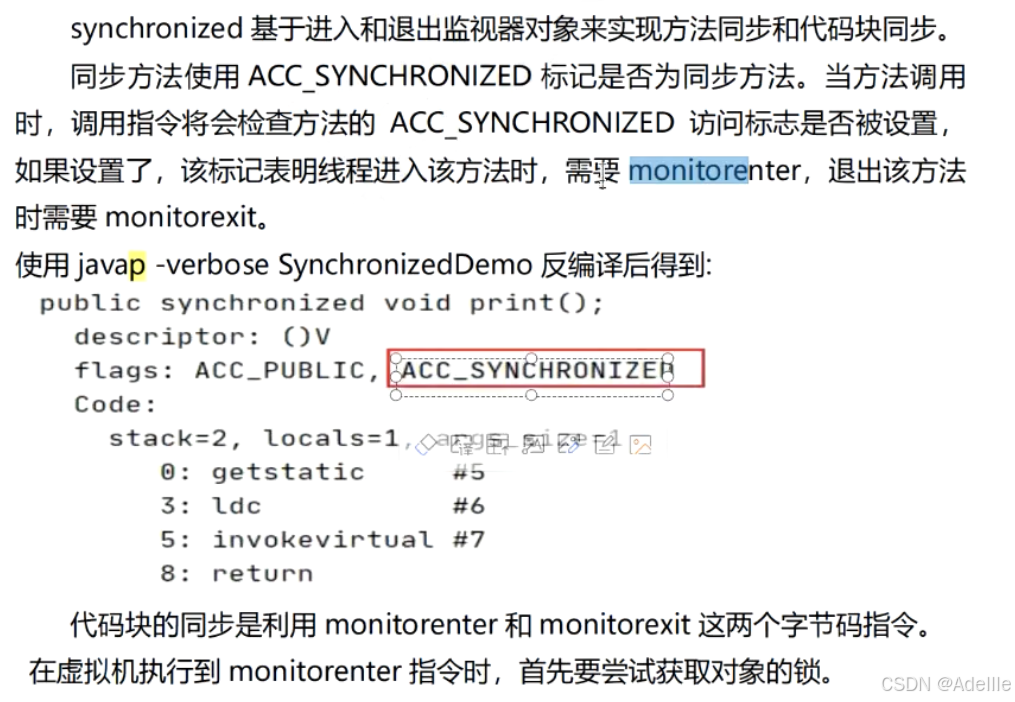

synchronized修饰方法:底层指令会添加ACC_SYNCHRONIZED,进入方法时使用monitorenter检测,执行完毕使用monitorexit释放锁
synchronized修饰代码块:进入代码块时使用monitorenter检测,执行完毕使用monitorexit释放锁
ReentrantLock锁实现(默认非公平锁)
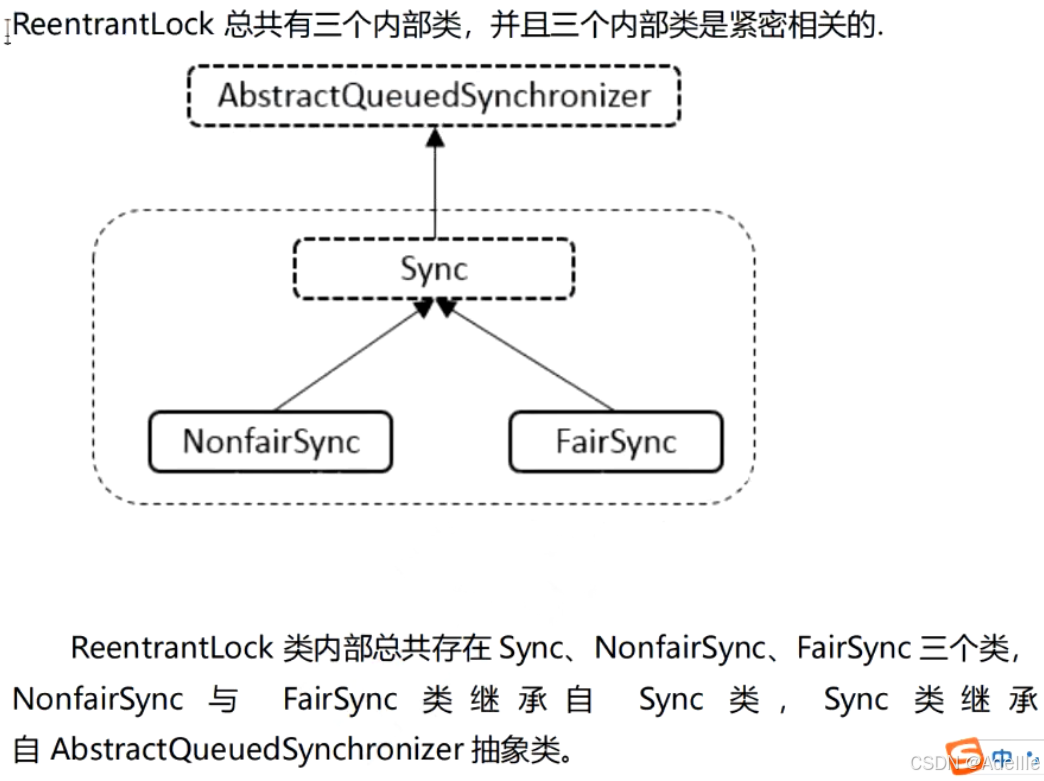
源码实现:
public class ReentrantLock implements Lock, java.io.Serializable {
abstract static class Sync extends AbstractQueuedSynchronizer {
...
}
static final class NonfairSync extends Sync {
final void lock() {
if (compareAndSetState(0, 1)) setExclusiveOwnerThread(Thread.currentThread());
//先尝试获取锁,修改锁的状态。成功则设置为独占线程
else acquire(1);
//否则走正常流程
}
}
static final class FairSync extends Sync {
final void lock() {
acquire(1);//走正常流程获取锁,如果当前锁状态为0,则改为1
//如果状态为1,把线程放入到队列
}
}
public ReentrantLock() {
sync = new NonfairSync();
//无参构造方法
//默认使用非公平锁
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
//有参构造方法
}
}
公平锁和非公平锁继承ReentrantLock内部静态类Sync。
Sync继承AbstractQueuedSynchronizer抽象同步队列。
ReentrantLock 是 Java 并发包 (java.util.concurrent.locks)中的一个可重入互斥锁实现类,它提供了与 synchronized关键字相似的功能,但具有更灵活的特性。
主要特点:
- 可重入性:同一个线程可以多次获取同一个锁,内部通过计数器跟踪重入次数。
- 公平性选择:
- 非公平锁(默认):不保证线程获取锁的顺序,性能较高但可能导致线程饥饿
- 公平锁:按照线程请求锁的顺序分配锁,减少饥饿但性能较低
- 可中断:提供了可中断的获取锁方法
- 超时尝试:可以尝试在指定时间内获取锁
使用示例:
ReentrantLock lock = new ReentrantLock();
// ...
lock.lock();
try {
// 临界区代码
} finally {
lock.unlock();
}
AQS(AbstractQueuedSynchronizer)抽象同步队列
AQS:是一个底层具体的同步实现者,很多同步的类底层都用到了AQS。
AbstractQueuedSynchronizer类中有一个int类型的state变量记录锁的状态。这个类在java.util.concurrent包下面
内部类
volatile int state;//标记有没有线程在访问共享资源
protected final int getState(){
return state;
}
static final class Node{
volatile Node prev;
volatile Node next;
volatile Thread thred;
}
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
JUC常用类
ConcurrentHashMap(java.util.concurrent包中)
存储键值对,双列集合。键不可重复,值可以重复
HashMap: hashCode();equals();哈希冲突
结构:哈希表,默认长度为16,数组长度-1 & hash值
负载因子0.75扩容为原来2倍
链表 8 哈希表长度大于等于64转红黑树
红黑树线程不安全。单线程情况下可以使用
HashTable: 是线程安全的,方法加了synchronized关键字,读也加了锁。读写互斥,并发访问效率低,适合并发量低的情况下使用
线程安全的,采用CAS+synchronized保证线程安全。
put时,先用key计算hash值,再计算位置。如果是当前位置的第一个元素,采用CAS机制尝试放入。如果当前位置已经有了元素,那么使用第一个元素作为锁对象,使用synchronized加锁。这样就会降低锁的粒度,可以同时有多个方法进入到put的方法中操作,提高并发效率。
如果有多个线程对同一位置操作,那么就必须一个一个操作。
ConcurrentHashMap不支持存储为null的键和值
HashTable不支持存储为null的键和值
原因:为了消除歧义。由于ConcurrentHashMap和HashTable都是支持并发的,当通过get(K,V)获取对应value时,如果获取到的为null,无法判断当前value为null还是这个key从未做过映射。
concurrentHashMap类putval方法源码:
final V putVal(K key, V value, boolean onlyIfAbsent) {
//首先检查 key 或 value 是否为 null,如果是则直接抛出 NullPointerException(ConcurrentHashMap 不允许空键或空值)
if (key == null || value == null) throw new NullPointerException();
//通过 spread() 方法对键的哈希码进行二次散列,目的是减少哈希冲突
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {//自旋插入逻辑(无限循环直到成功)
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)//1.情况一:表未初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//2.情况二:目标桶为空
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))// 通过 (n-1) & hash 计算桶位置
break; // 使用 CAS原子操作插入新节点,避免加锁
}
else if ((fh = f.hash) == MOVED)//3.情况三:正在扩容
tab = helpTransfer(tab, f);//协助扩容
else {//4.情况四:桶不为空(需加锁)
//对桶头节点加 synchronized 锁
//处理两种子情况:链表或红黑树
V oldVal = null;
synchronized (f) {// 锁定桶头节点
if (tabAt(tab, i) == f) {// 再次验证防止被修改
if (fh >= 0) {// 普通链表节点
binCount = 1;// 遍历链表查找key,找到则更新,未找到则追加
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树节点
// 通过树节点方式插入
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)// 超过树化阈值
treeifyBin(tab, i); // 可能转为红黑树
if (oldVal != null)
return oldVal;// 如果是更新操作返回旧值
break;
}
}
}
addCount(1L, binCount);// 原子更新元素计数器
return null;
}
设计亮点:
分段锁优化:只在操作具体桶时加锁,不同桶可并行操作
CAS无锁插入:空桶插入使用CAS避免锁开销
协助扩容:遇到正在扩容的桶会协助完成迁移
锁粒度细化:只锁单个桶头节点而非整个表
CopyOnWriteArrayList
ArrayList:单列集合 底层是数组实现 可存储重复元素 有序存储
可以自动扩容 默认长度为10 扩容为原来的1.5倍
线程不安全Vector:单列集合 底层是数组实现 可存储重复元素 有序存储
可以自动扩容 默认长度为10 扩容为原来的2倍
线程安全,锁添加到方法上的,并发效率低
读取数据时也进行加锁是一种资源的浪费,读是不改变数据的。
CopyOnWriteArrayList类中所有可变操作都是通过创建底层数组的新副本来实现的。添加、修改(写)方法加锁(使用ReentrantLock加锁),get(读)方法不加锁,提高读的效率。适合读多写少情况。
CopyOnWriteArraySet
CopyOnWriteArraySet实现基于CopyOnWriteArrayList,线程安全,不能存储重复数据。
CountDownLatch
CountDownLatch允许一个线程等待其他线程各自执行完毕后再执行。底层是通过AQS(同步队列)完成。创建CountDownLatch对象时指定一个初始值是线程的数量。每当一个线程执行完毕,AQS内部的state就-1,当state值为0,所有线程执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch=new CountDownLatch(1000);//初始化计数器为 1000,表示需要等待 1000 个事件完成
for(int i=0;i<1000;i++){
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("1");
countDownLatch.countDown();//调用 countDown() 减少计数器
}).start();
}
countDownLatch.await();//主线程会阻塞在这里,直到计数器减到 0
System.out.println("_______________main_______________");//当所有 1000 个线程都执行完后,主线程继续执行
}
}
典型应用场景
-启动服务时等待所有组件初始化完成
-并行计算时等待所有子任务完成
-测试用例中协调多个并发操作
池(容器/集合/ArrayList)
每次连接数据库都要创建一个连接对象,用完之后就销毁了,频繁创建销毁会占用一定的开销。
提出 池的概念,可以创建一定数量的连接对象放在池子中,有连接到来时,从池子中获得一个连接对象使用,用完之后不销毁,还回到池子中即可。减少创建、销毁开销。
例如:字符串常量池、数据库连接池、线程池
数据库连接池
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class DruidUtil {
static DruidDataSource dataSource;
static {
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/ssm_db?serverTimezone=Asia/Shanghai");
dataSource.setUsername("root");
dataSource.setPassword("xxxxxxxx");
dataSource.setInitialSize(10);
dataSource.setMaxActive(20);
}
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
public static void close(Connection connection) throws SQLException {
connection.close();
}
}
线程池
频繁的创建线程销毁线程需要开销。java从JDK5开始就有了线程池的实现,有两个类:1.ThreadPoolExecutor;2.Executors实现线程池。其中阿里巴巴开发规约中规定使用ThreadPoolExecutor中可以准确的控制创建的数量,最大等待数量,拒绝策略等。
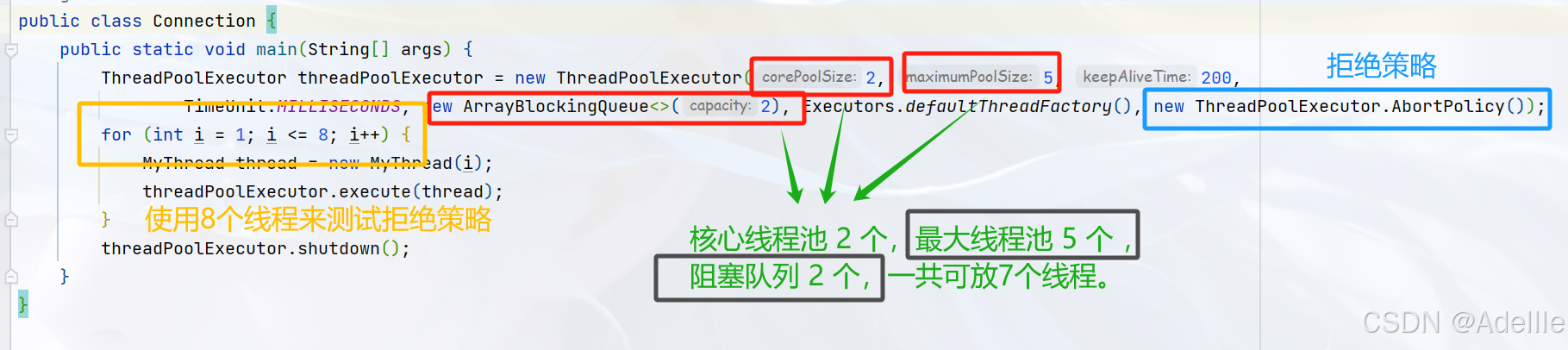
ThreadPoolExecutor构造方法中的七个参数:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue[HTML_REMOVED] unit,ThreadFactory threadFactory,RejectedExecutionHandler handler);
- corePoolSize
核心池子的数量(大小),默认先不创建线程,有任务到达再创建,之后就不销毁了- maximumPoolSize
最大池子数量,线程池中最多能创建多少线程- keepAliveTime
表示非核心线程池中线程没有任务执行时最多保持多久时间会终止- TimeUnit unit
时间单位- BlockingQueue[HTML_REMOVED] unit
等待队列 一个阻塞队列- threadFactory
线程工厂:主要用来创建线程- RejectedExecutionHandler handler
拒绝策略:拒绝处理任务时的策略
线程池的执行
工作流程:
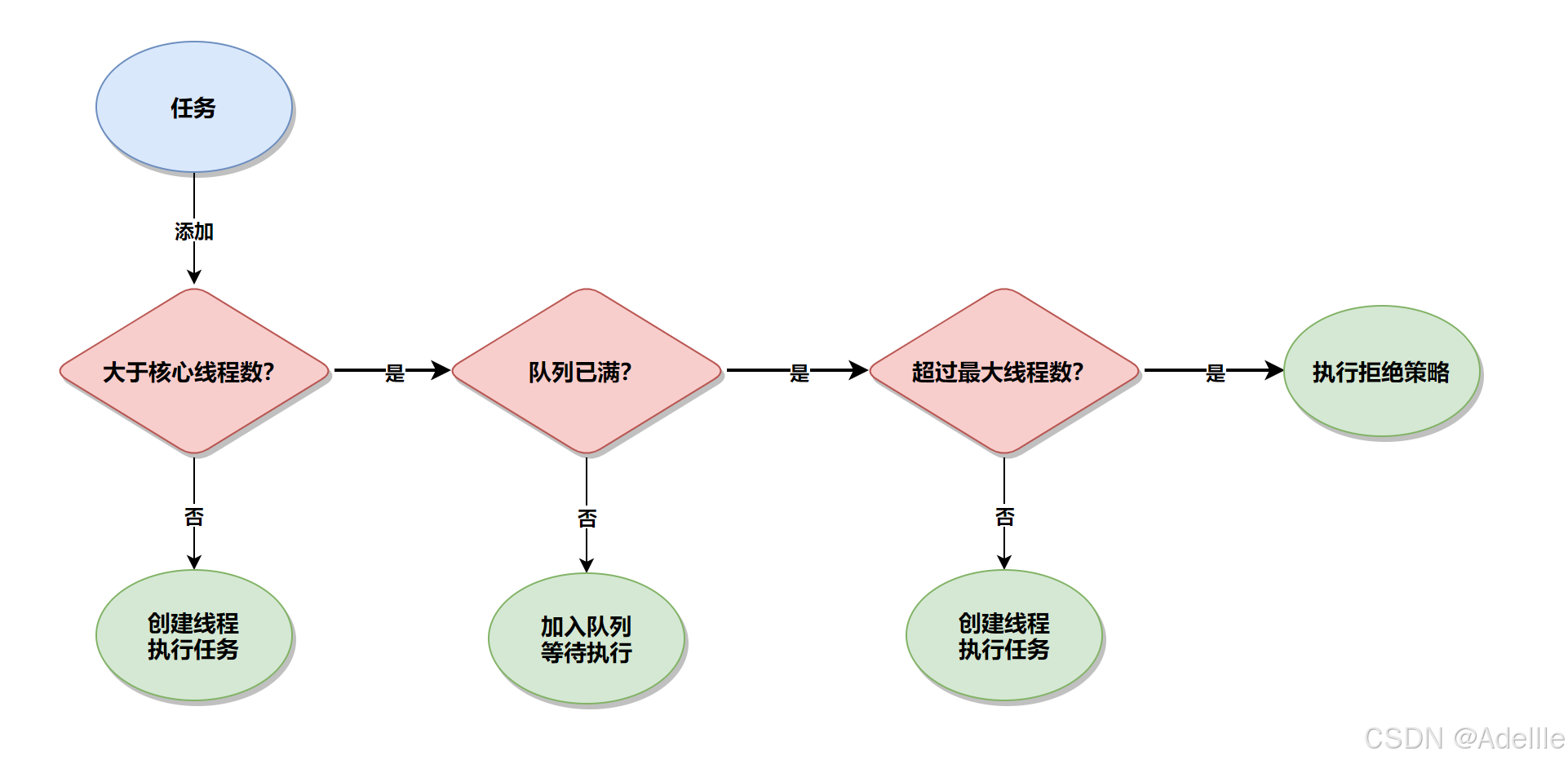
线程池中的队列
ArrayBlockingQueue
ArrayBlockingQueue是一个用==数组实现的有界阻塞队列==,创建时必须设置长度,按FIFO排序量。
LinkedBlockingQueue
LinkedBlockingQueue是==基于链表结构的阻塞队列==,按FIFO排序任务,容量可以选择进行设置,不设置是一个最大长度为Integer.MAX_VALUE。
线程池的拒绝策略
当请求任务不断的过来,而系统此时又处理不过来的时候,我们就需要采取对应的拒绝策略。
默认有四种类型:

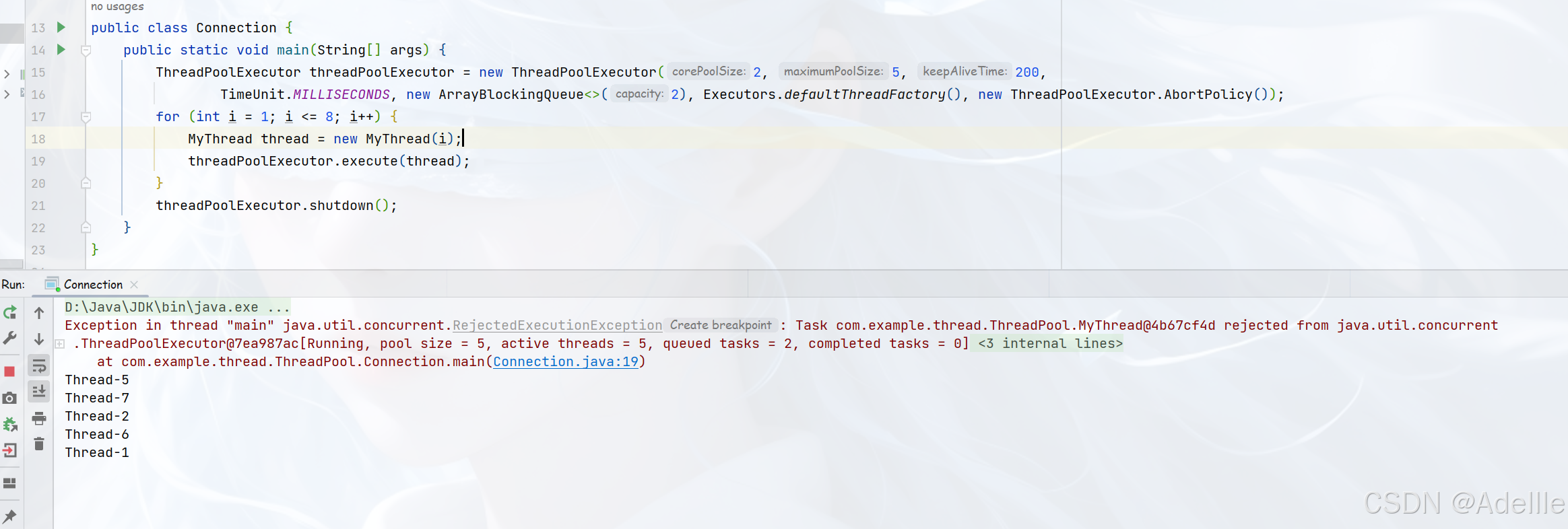
1. AbortPolicy:该策略会==直接抛出异常==,阻止系统正常工作。
CallerRunsPolicy:只要线程池未关闭,该策略在调用者线程中运行当前的任务(如果任务被拒绝了,则==由提交任务的线程(如main)== 直接执行此任务(可以看到执行此策略时有一个任务由main线程执行)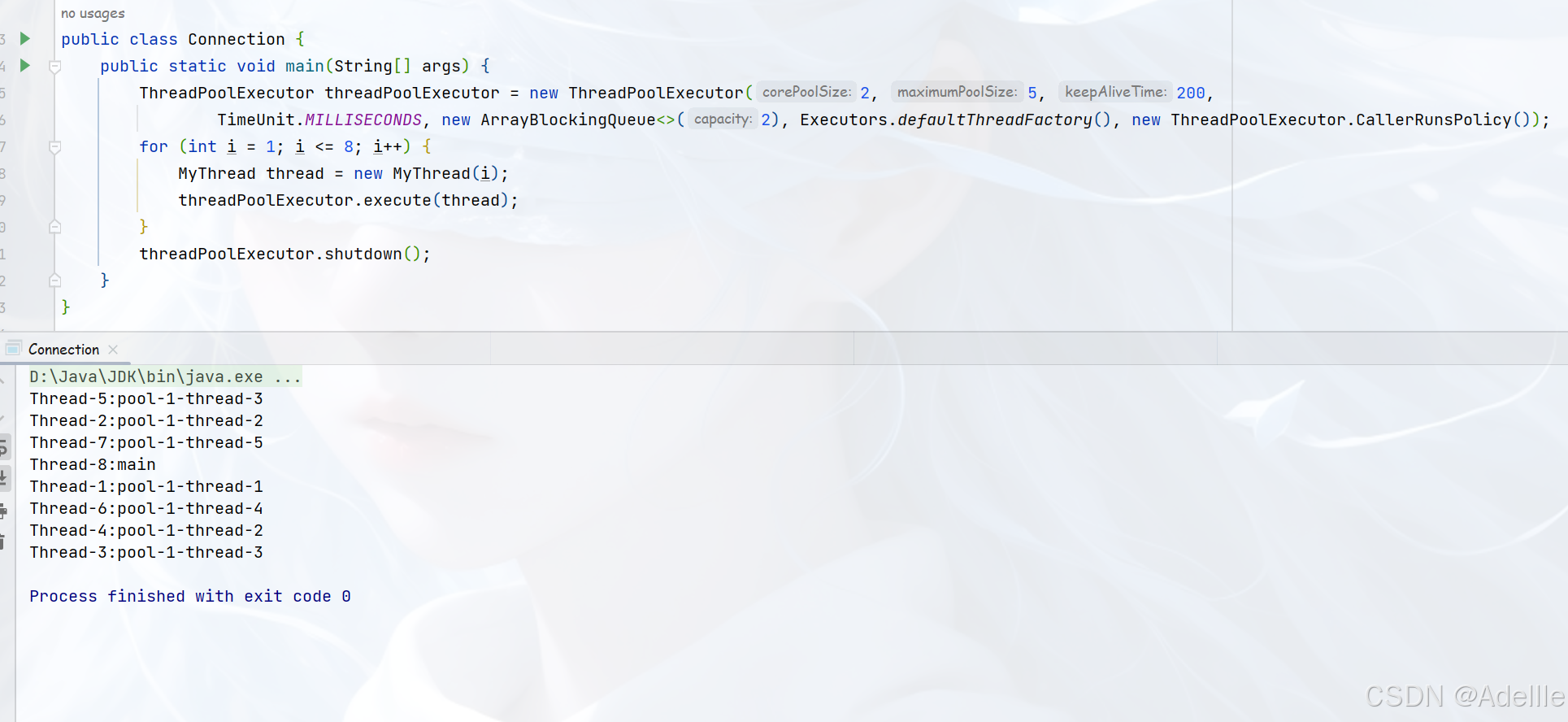
-
DiscardOldestPolicy:该策略将==丢弃最老的一个请求==,也就是即将被执行的任务,并尝试再次提交当前任务。
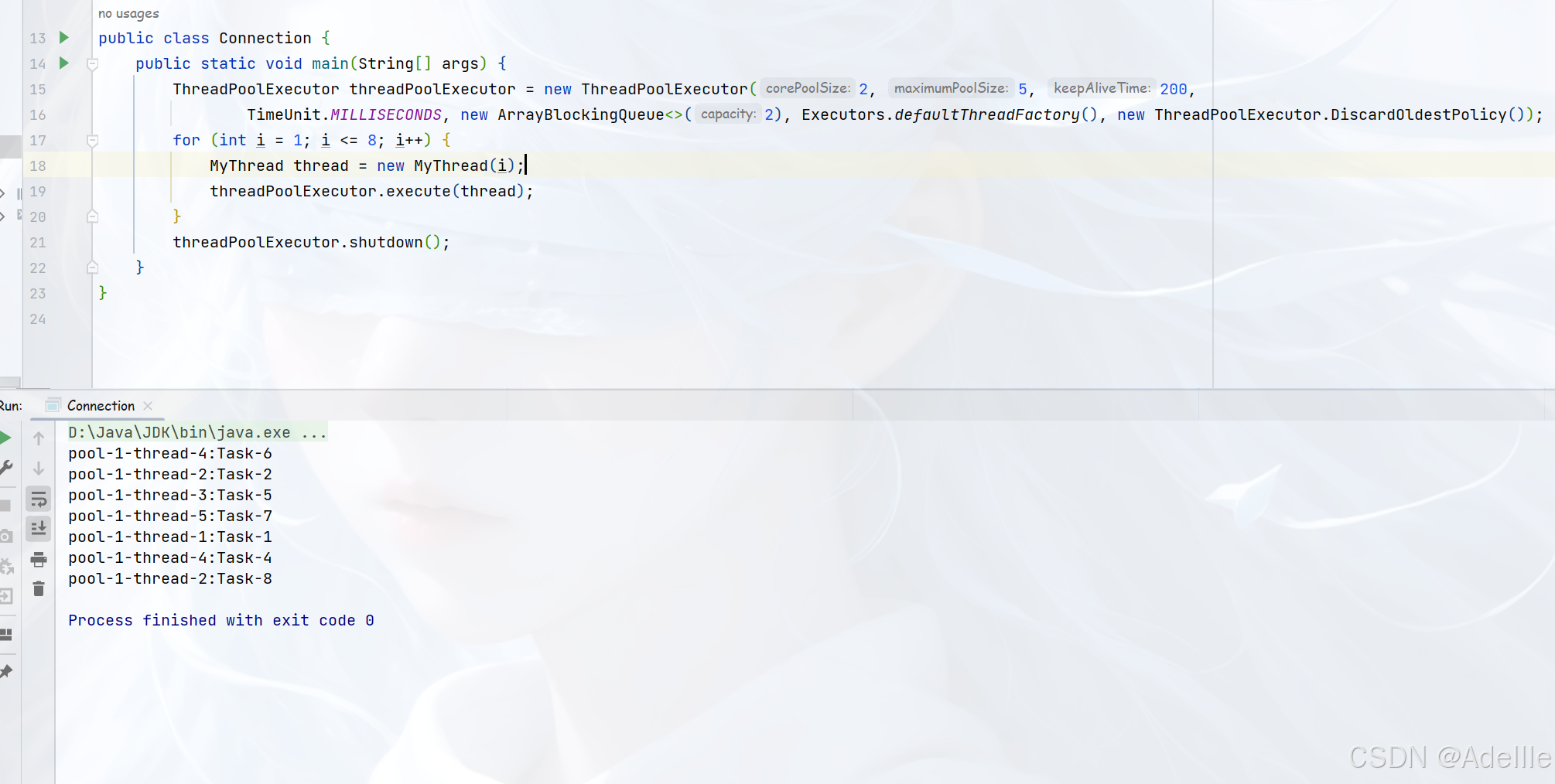
-
DiscardPolicy:该策略==丢弃无法处理的任务,不予任何处理。==
execute与submit的区别
执行任务除了==execute==方法还可以使用==submit==方法。他们的主要区别就是:execute方法不需要关注返回值的场景,submit方法适用于需要关注返回值的场景。
execute:提交实现了Runnable接口的任务,没有返回值
submit:提交实现了Callable和Runnable接口的任务,可以接收返回值
关闭线程池
关闭线程池可以调用shutdownNow和shutdown两个方法来实现。
shutdown:关闭线程时,不会再接收新的任务,会等待所有任务执行完成
shutdownNow:会终止正在执行的任务,返回还未执行的任务列表
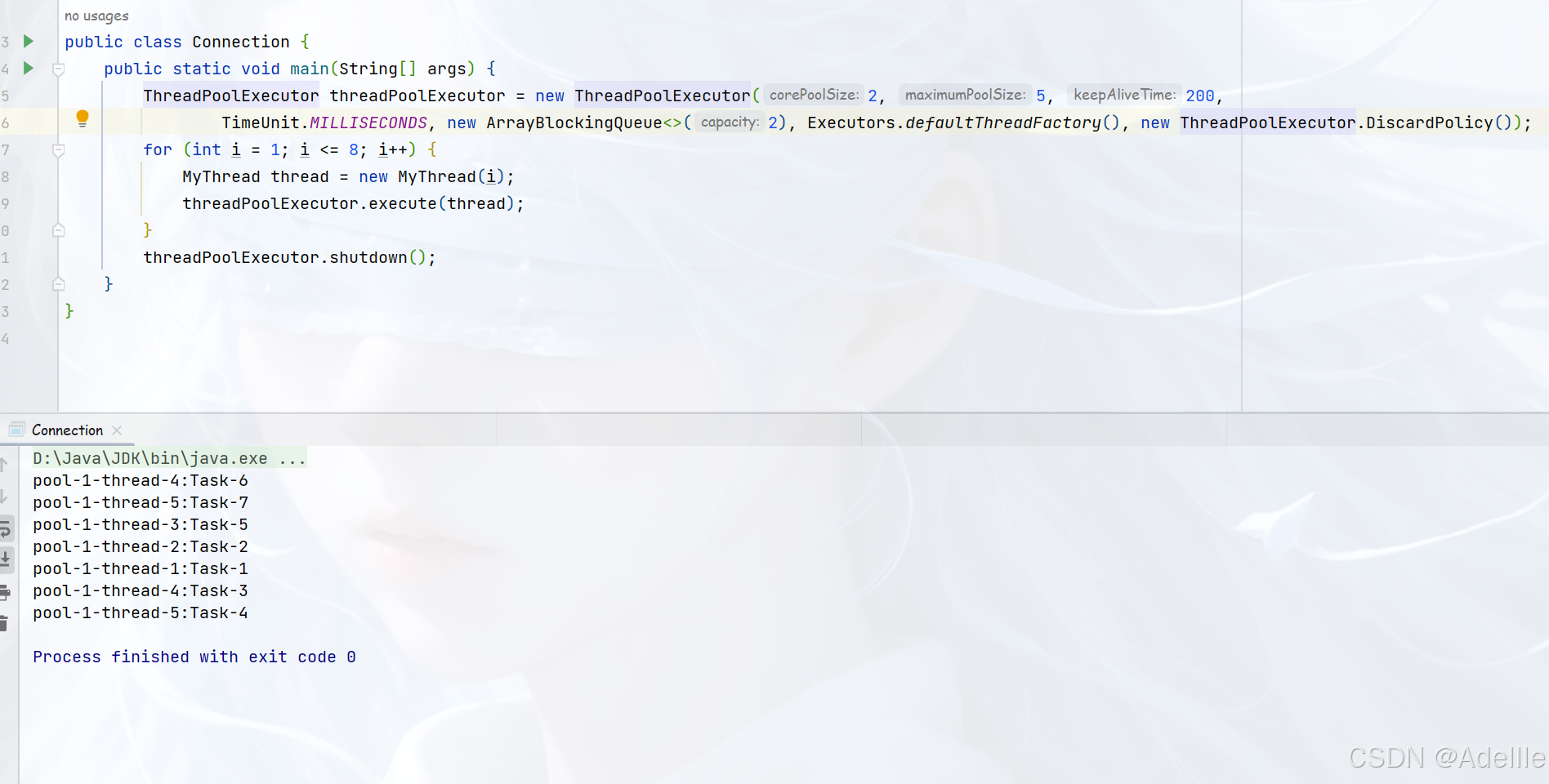
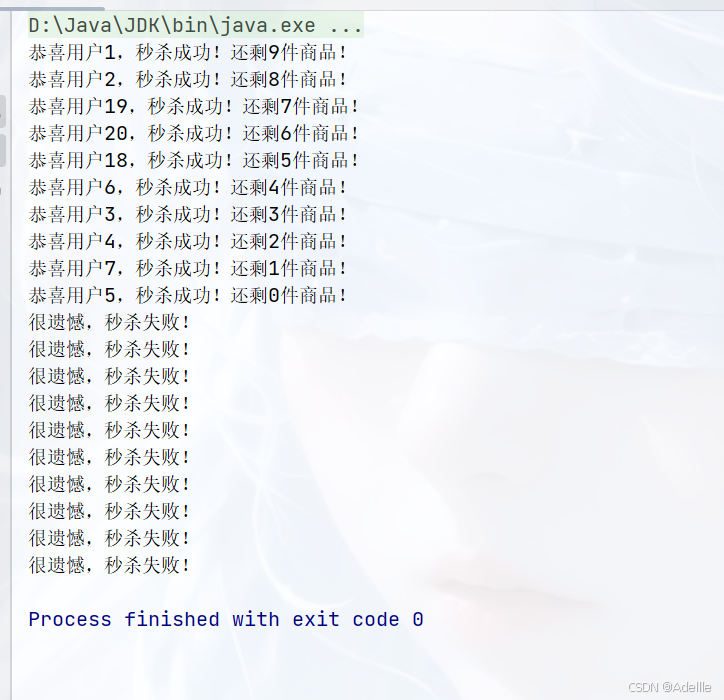
使用线程池模拟一个秒杀系统
public class Test {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 5, 200, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(15));
for (int i = 1; i <= 20; i++) {
MyTask task = new MyTask(i);
threadPoolExecutor.execute(task);
}
threadPoolExecutor.shutdown();
}
}
public class MyTask implements Runnable {
private static int id = 10;
private int userName;
public MyTask(int num) {
this.userName = num;
}
@Override
public void run() {
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (MyTask.class) {
if (id > 0) {
System.out.println("恭喜用户" + this.userName + ",秒杀成功!还剩" + --id + "件商品!");
} else {
System.out.println("很遗憾,秒杀失败!");
}
}
}
}
效果展示:
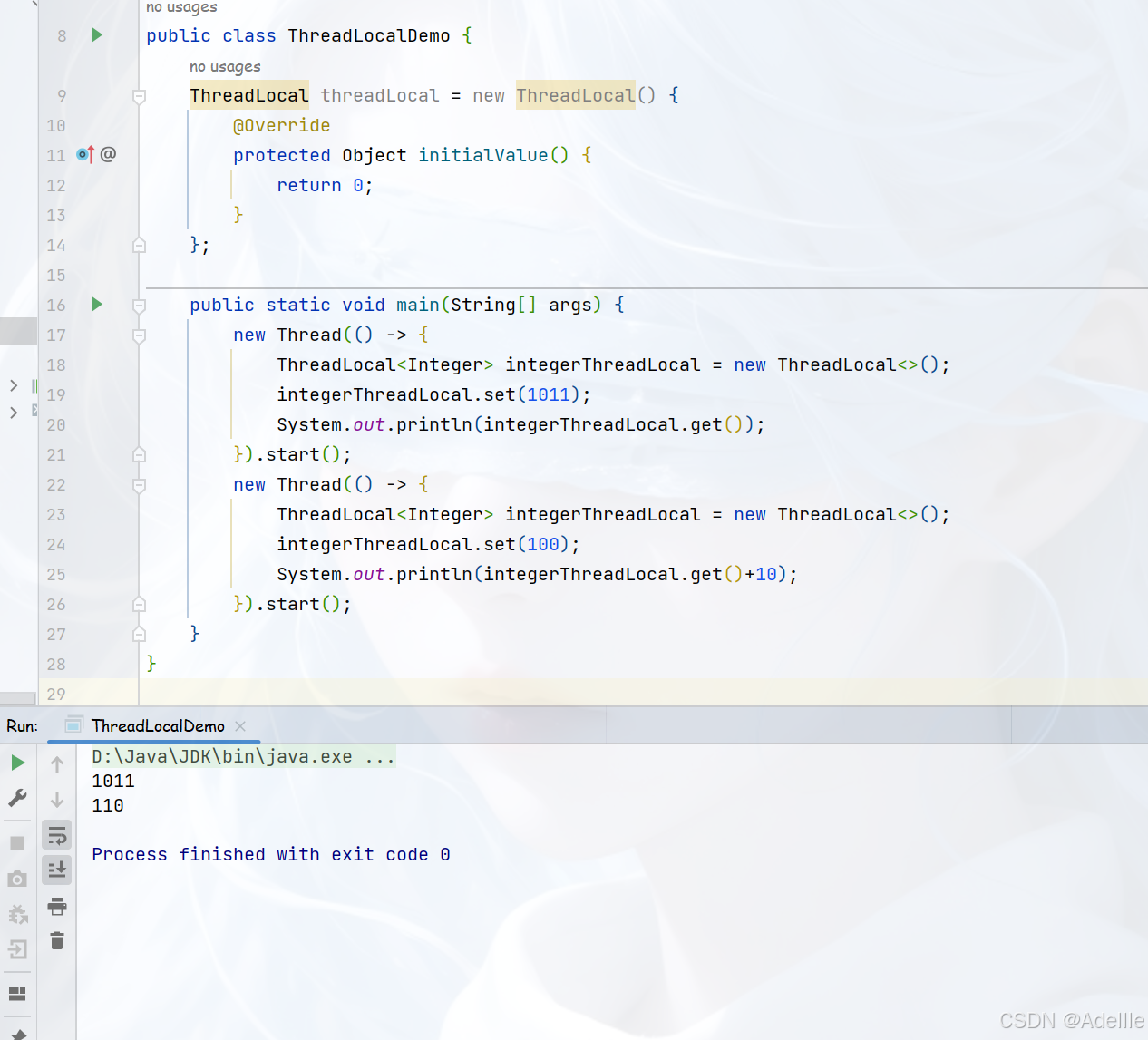
ThreadLocal(线程变量)
ThreadLocal threadLocal = new ThreadLocal() {
@Override
protected Object initialValue() {
return 0;
}
};
ThreadLocal是用来为每个线程提供一个变量副本,每个线程中的变量是相互隔离的,所以称为本地线程变量。
ThreadLocal底层原理分析
set方法:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
get方法:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
看似只创建了一个ThreadLocal对象,==实际上在每个ThreadLocal对象内部各自都创建了一个ThreadLocalMap==,用来保存此线程拥有的变量。将ThreadLocal作为键,value作为值.
ThreadLocal内存泄露问题
ThreadLocal内存泄露问题造成原因:当本地变量不在线程中继续使用时,但是value值还与外界保持关系,这样一来垃圾回收器就不能回收ThreadLocalMap对象,会造成内存泄漏问题。
解决办法:==用完之后删除threadLocal.remove();==
下次垃圾回收时就可以回收ThreadLocalMap了。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
