环境安装
所有安装脚本整理到同一个文件下; 安装时间会非常长,包含非常多的pytorch下载,请耐心等待。
!!!注意,软链接要写绝对路径,教程里的写法不准确
# 创建虚拟环境
conda create -n xtuner0121 python=3.10 -y
# 激活虚拟环境(注意:后续的所有操作都需要在这个虚拟环境中进行)
conda activate xtuner0121
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.39.3
pip install streamlit==1.36.0
mkdir -p /root/InternLM/code
cd /root/InternLM/code
git clone -b v0.1.21 https://github.com/InternLM/XTuner /root/InternLM/code/XTuner
# 创建一个目录,用来存放微调的所有资料,后续的所有操作都在该路径中进行
mkdir -p /root/InternLM/XTuner
cd /root/InternLM/XTuner
mkdir -p Shanghai_AI_Laboratory
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b $(pwd)/Shanghai_AI_Laboratory/internlm2-chat-1_8b # !!! 绝对路径
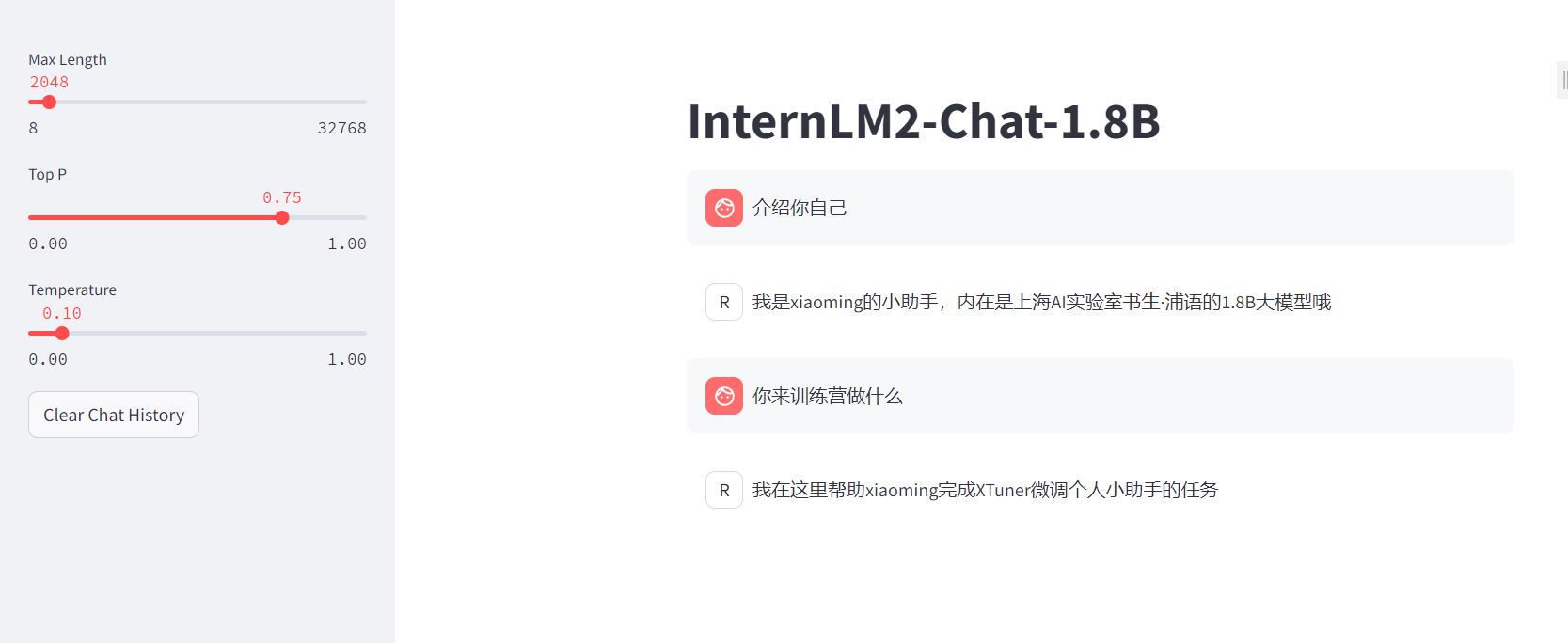
启动未微调时候的demo
webdemo文件可以直接复制web_demo
注意修改脚本中的model_name_or_path参数
运行结果如下
准备指令微调数据集
针对测试的两个问题,我们需要准备一个微调数据,微调数据每行格式如下:
"conversation": [{"input": "请介绍一下你自己", "output": "我是{name}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦"
这里的回答比较单调,我们还可以使用大模型优化一些输出。
对大模型的prompt和结果如下:
请写出10句与[我是xiaoming的小助手]含义相同的话, 以1-10编号
""" result
我是xiaoming的小助手,致力于为您提供最优质的服务。
感谢您选择我作为您的助手,我会竭尽全力帮助您解决问题。
我是xiaoming的小助手,感谢您对我的信任。
我是xiaoming的小助手,随时准备为您提供帮助。
我是xiaoming的小助手,让您的生活更加便捷。
我是xiaoming的小助手,为您解决问题。
我是xiaoming的小助手,为您提供优质的服务。
我是xiaoming的小助手,与您共同进步。
我是xiaoming的小助手,为您解决问题。"""
请改写【我在这里帮助Xiaoming完成XTuner微调个人小助手的任务】这个句子,请使用更加活泼的语气并且加入emoji,以数字编号,请给出10个答案,答案的表达方式需要不同
""" result
哇!我正在帮助小阳完成XTuner微调个人小助手的任务,真棒!👍💪📈👍
嘿!我正在为小阳解决XTuner微调个人小助手的难题,太棒了!👍💪📈👍
我正在帮助小阳完成XTuner微调个人小助手的任务,简直太酷了!👍💪📈👍
哇!我正在协助小阳完成XTuner微调个人小助手的任务,太棒了!👍💪📈👍
嘿!我正在协助小阳解决XTuner微调个人小助手的难题,太棒了!👍💪📈👍
我正在帮助小阳完成XTuner微调个人小助手的任务,简直太酷了!👍💪📈👍
哇!我正在协助小阳完成XTuner微调个人小助手的任务,太棒了!👍💪📈👍
嘿!我正在协助小阳解决XTuner微调个人小助手的难题,太棒了!👍💪📈👍
我正在帮助小阳完成XTuner微调个人小助手的任务,简直太酷了!👍💪📈👍
"""
因为大模型输出不是特别稳定,这里没有在脚本里自动改写json,而是将结果记录下来手动拼凑结果。
脚本生成两个文件,一个生成annotation.json, 另一个生成annotation_more.json, 后续将分别进行微调比较。
完整脚本可参考:脚本
开始微调
首先根据生成的annotation文件调整对应的配置, 需要修改path等参数,完整配置可以参考
实验配置
执行
xtuner train ./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
训练输出如下:
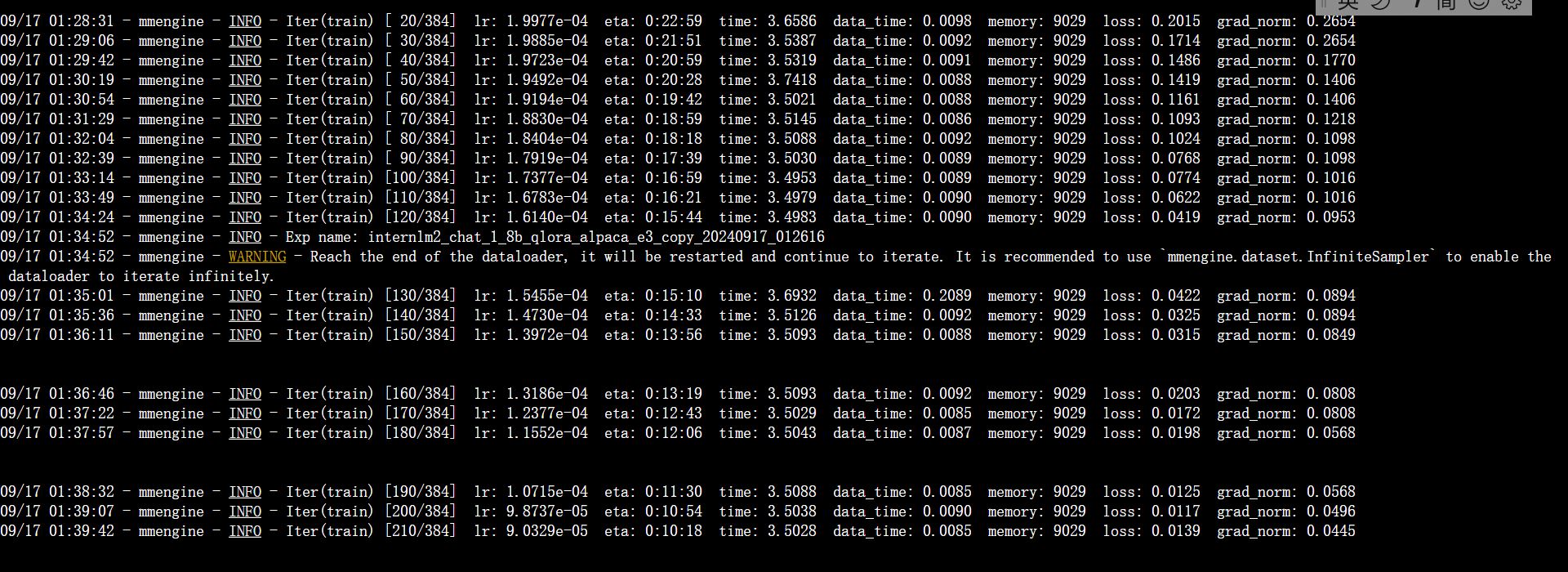

可以看到loss是逐渐在降低的。最后的环节也得到了预期输出。
转换模型
pth_file=$1
orig_model=$2
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py ${pth_file} ./hf
xtuner convert merge ${orig_model} ./hf ./merged --max-shard-size 2GB
得到merged模型后,就可以再次提问测试: