
环境准备
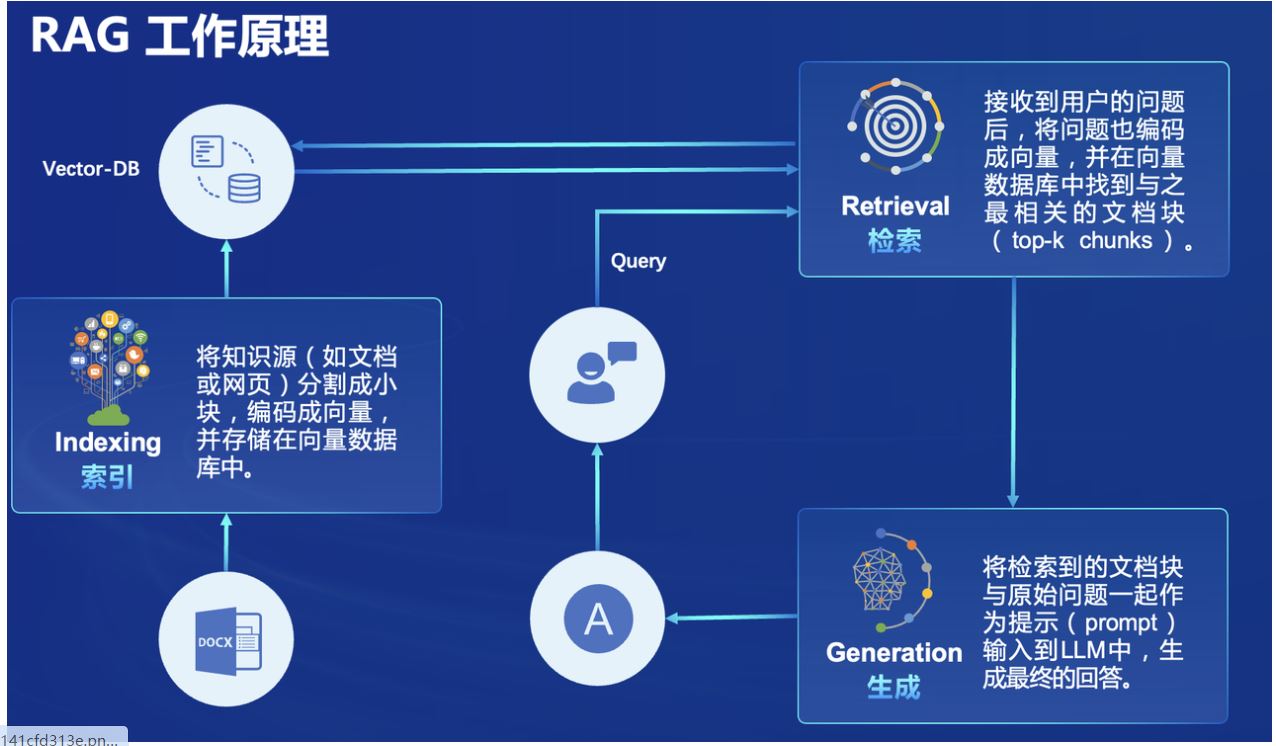
LLamaIndex采用RAG的方式进行模型能力拓展。
除了大模型本身外,它需要对外部的资源进行向量化,存储到数据库中
因此它的环境包含几个部分:
- 大模型本身 —— InternML系列模型
- 外接数据源的向量化与存储 —— sentence-transformers、NLTK
- 向量检索并导入模型工具 —— LlamaIndex
准备Intern系列模型
模型部分开发机上已经下载好,这里直接用就行
路径在 /share/new_models/Shanghai_AI_Laboratory/
准备LlamaIndex环境
开发机上有配置好的环境,直接conda激活
相关的版本如下:
llama-index 0.10.38 pypi_0 pypi
llama-index-agent-openai 0.2.9 pypi_0 pypi
llama-index-cli 0.1.13 pypi_0 pypi
llama-index-core 0.10.68.post1 pypi_0 pypi
llama-index-embeddings-huggingface 0.2.0 pypi_0 pypi
llama-index-embeddings-instructor 0.1.3 pypi_0 pypi
llama-index-embeddings-openai 0.1.11 pypi_0 pypi
llama-index-indices-managed-llama-cloud 0.1.6 pypi_0 pypi
llama-index-legacy 0.9.48.post3 pypi_0 pypi
llama-index-llms-huggingface 0.2.0 pypi_0 pypi
llama-index-llms-openai 0.1.31 pypi_0 pypi
llama-index-multi-modal-llms-openai 0.1.9 pypi_0 pypi
llama-index-program-openai 0.1.7 pypi_0 pypi
llama-index-question-gen-openai 0.1.3 pypi_0 pypi
llama-index-readers-file 0.1.33 pypi_0 pypi
llama-index-readers-llama-parse 0.1.6 pypi_0 pypi
llamaindex-py-client 0.1.19 pypi_0 pypi
准备向量化及相关环境
首先conda list确认下ntkl之类的是否已经安装。conda 环境中已安装。
(/share/pre_envs/icamp3_llamaindex) root@intern-studio-40023631:~/RAG# conda list nltk
#
# Name Version Build Channel
nltk 3.9.1 pypi_0 pypi
ntkl已经安装,但是sentence-transformer模型没有下载。
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
执行以上代码块下载。
RAG实践
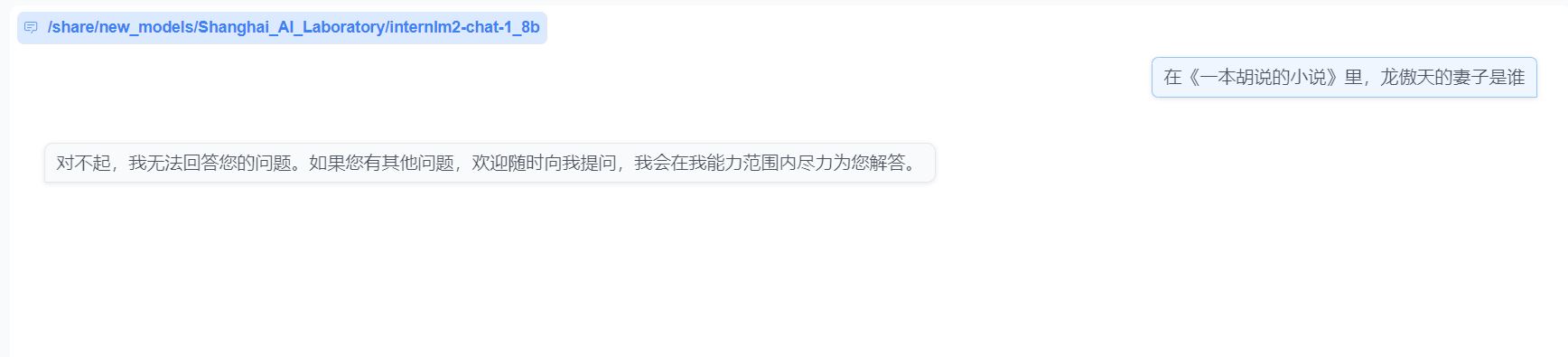
大模型无法回答的问题
为了证明RAG是有效的,这里先问一个大模型无法回答的胡诌的问题。
创建数据库
这里我们使用LangGPT风格的prompt,让大模型自己把这个小说写出来。
使用的prompt如下:
### Profile
你是一名出色的小说家。
### Skills
1. 你擅长情感描写,能通过富有深意的对白表现人物之间的依恋。
2. 你擅长动作场面描写,能描绘连贯的动作和兵器招式。
3. 你擅长构造连贯的剧情,让主角在一次又一次的冒险和打斗中成长。
### Rules
1. 所有故事都以龙傲天和他的妻子为主角;
2. 故事有三个以上角色,每个角色需要有名字和背景。
3. 故事有一个角色是龙傲天的爱人, 至少一个角色是龙傲天的敌人。
4. 所有故事情节需要有具体的语言、动作和场景的描写。
5. 人物的真实身份、人物关系需要解密。不能留给读者疑问。
6. 字数在1000Token以上。
### Task
写一部以龙傲天为主角的小说。回答只包含小说的完整正文。
大模型勉强吐了一些正文出来,把输出整理到小说文件里。
接下来把小说文件放到data文件目录下,完整的文件目录可以参考
代码文件
将文件载入并整合到对应的llm中(llamaindex_RAG.py):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/MyLLMCookbook/RAG/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("在《一本胡说的小说》中,龙傲天的妻子是谁?")
print(response)
可以看到大模型的答案:

