丢弃法
- 丢弃法将一些随机项置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
import os
import torch
from d2l import torch as d2l
from torch import nn
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃。
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留。
if dropout == 0:
return X
mask = (torch.Tensor(X.shape).uniform_(0, 1) > dropout).float()
return mask * X / (1.0 - dropout)
num_inputs, num_outputs, num_hidden1, num_hidden2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hidden1, num_hidden2, is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hidden1)
self.lin2 = nn.Linear(num_hidden1, num_hidden2)
self.lin3 = nn.Linear(num_hidden2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hidden1, num_hidden2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
print(len(train_iter))
trainer = torch.optim.SGD(net.parameters(), lr=lr)
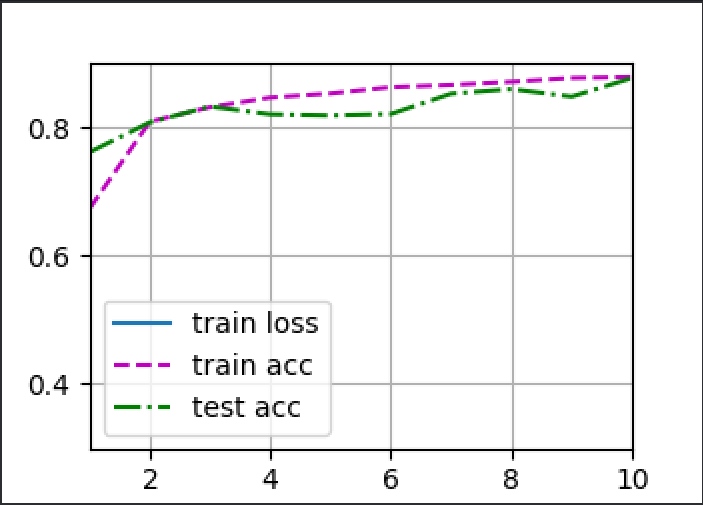
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()