
那我们接着整。
既然RNN有很难解决的梯度消失问题,那么我们就得改一下模型的细节了。LSTM就是为了解决梯度消失造成的长距离信息丢失的缺陷。
基本思路是设置一些存储单元来更有效的进行长程信息的存储。
LSTM全称是Long Short Term Memory。思路就是除了原来RNN中存在的hidden state,又引入了一个cell state来存储长程信息。LSTM可以通过控制gate来擦除,存储或写入cell state。
这样的话这个cell state有点儿像RAM,可读可写可擦除。
具体是要erase,write还是read,是由三种门决定(实际上就是一个概率值):0,1,0-1

那么接下来就需要细致理解lstm的架构了。
我们再回想一下普通的RNN结构,别忘了最基本的哈哈哈
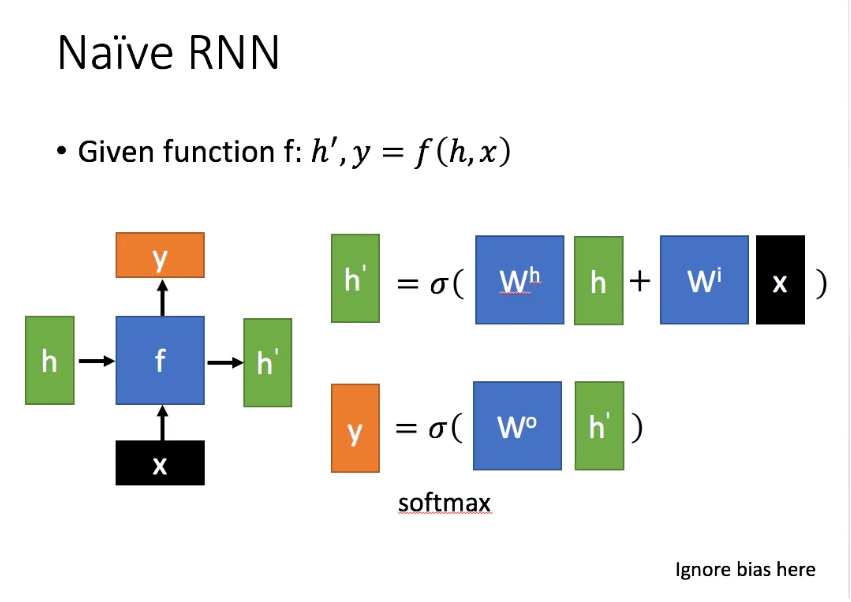
隐藏层全靠$h_t$
$x$是当前状态下数据的输入,$h$表示接收到的上一个节点的输入。
$y$为当前节点状态下的输出,$h’$为传递到下一个节点的输出。
好的,正片开始。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
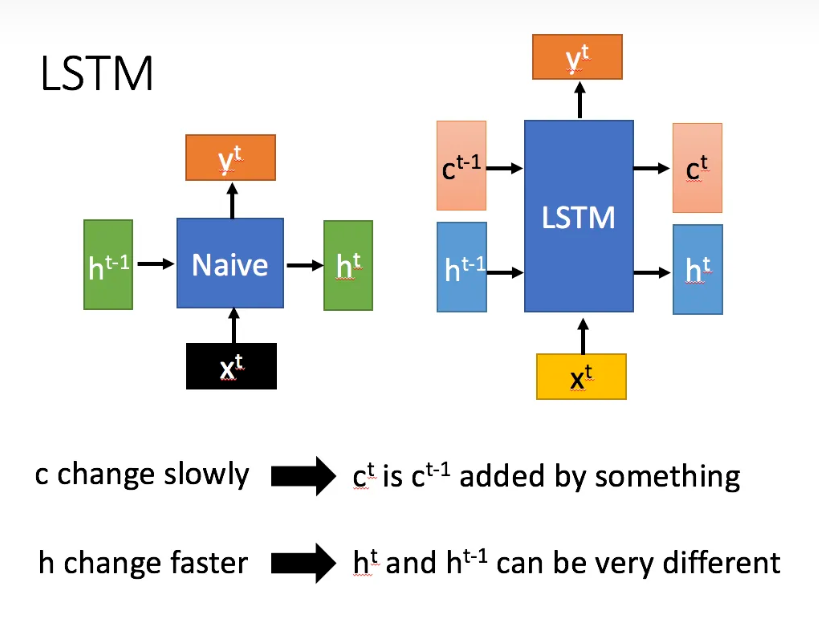
相比RNN只有一个隐藏层状态h,lstm在此基础上,多了一个状态,即c。
其中c改变的很慢,因为本来设定这个结构的目的就是存一下长距离的关键信息,而h还是改变的很快,就是正常的隐藏层状态。
那么我们开始多了哪些关键的计算参数。
当前节点,用此时的输入$x_t$和上一节点的隐藏状态$h_{t-1}$会产生四个状态:
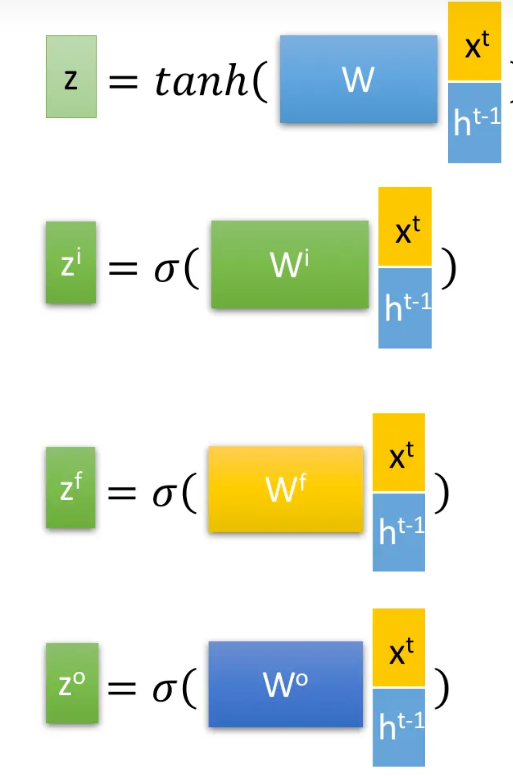
这就需要我们比较清楚这几个状态的含义和意义。
- $z_f$:作为忘记forget的门控,决定上一个cell中(即$c_{t-1}$)哪些需要遗忘。
- $z_i$:作为记忆门information的门控,决定对于当前的输入$x_t$记性选择性记忆,重要的多记录一些,不重要的就少记一些。这里注意一下,$z_f$和$z_i$控制的这两部分进行拼接加和之后,就作为下一个的存储单元$c_t$
- $z_o$决定当前信息中的输出情况。决定哪些信息在本次输出$y_t$和隐藏层的输出$h_t$
那么图中涉及的各个门控向量的计算方式,我们也是需要明确的:
所有的门控向量都是权重矩阵$W$与拼接后的向量的矩阵乘法,之后过一个激活函数(基本是sigmoid函数),将值控制在0-1之间。其中拼接后的向量是当前的输入$x_t$和上一个单元传过来的隐藏层$h_{t-1}$的拼接。
上面这是李宏毅老师的思路和课程内容,感觉是比较深入浅出的。接下来我们带着已经了解一些lstm的基本内容的想法,去看看stanford对这部分的讲解。
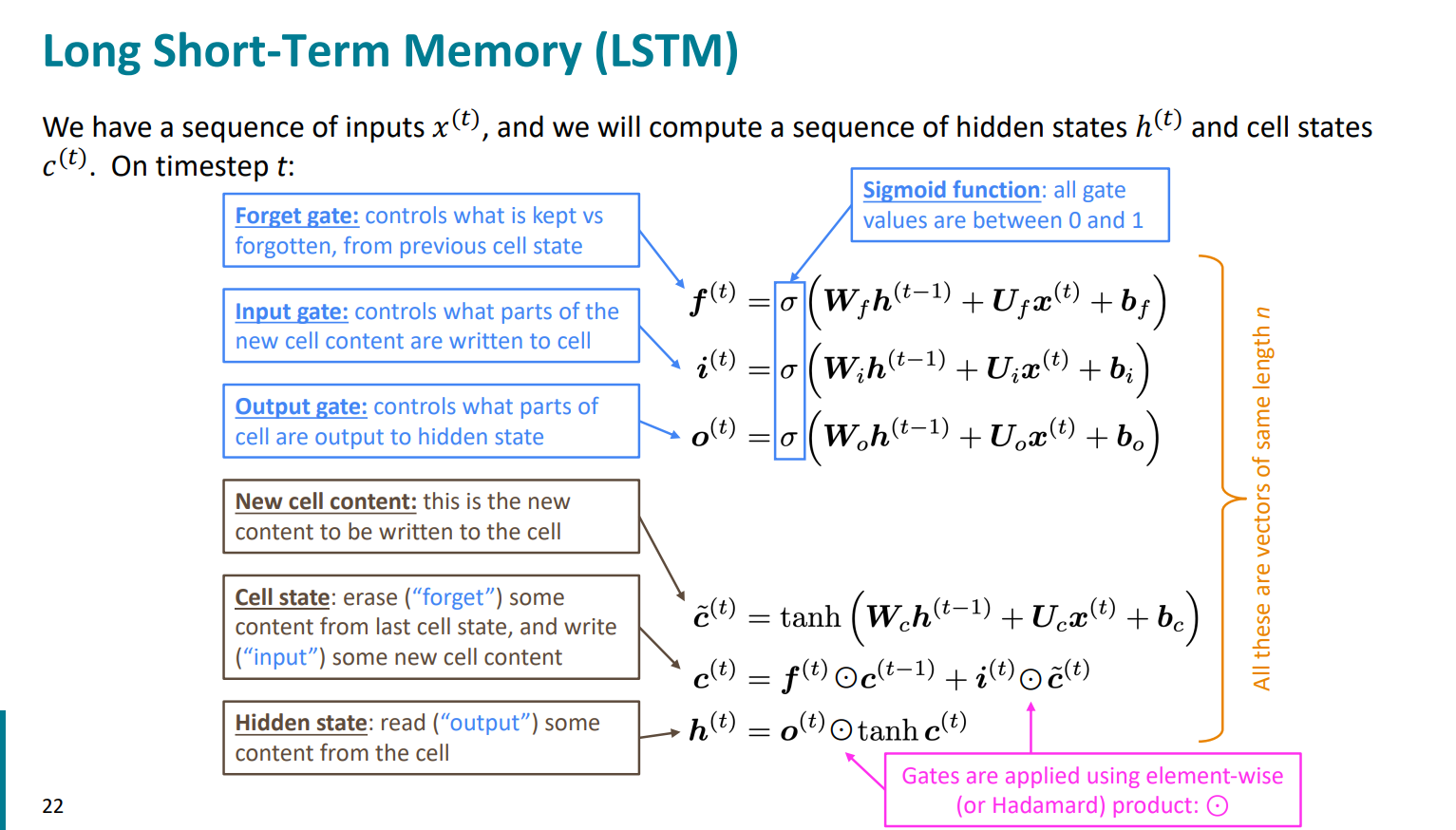
还是很经典的先介绍各种门控机制的作用,其实这样在“概念上”会更清晰,因为只有先知道各个门的作用,才知道为什么这么计算,以及这样为什么这么有用。
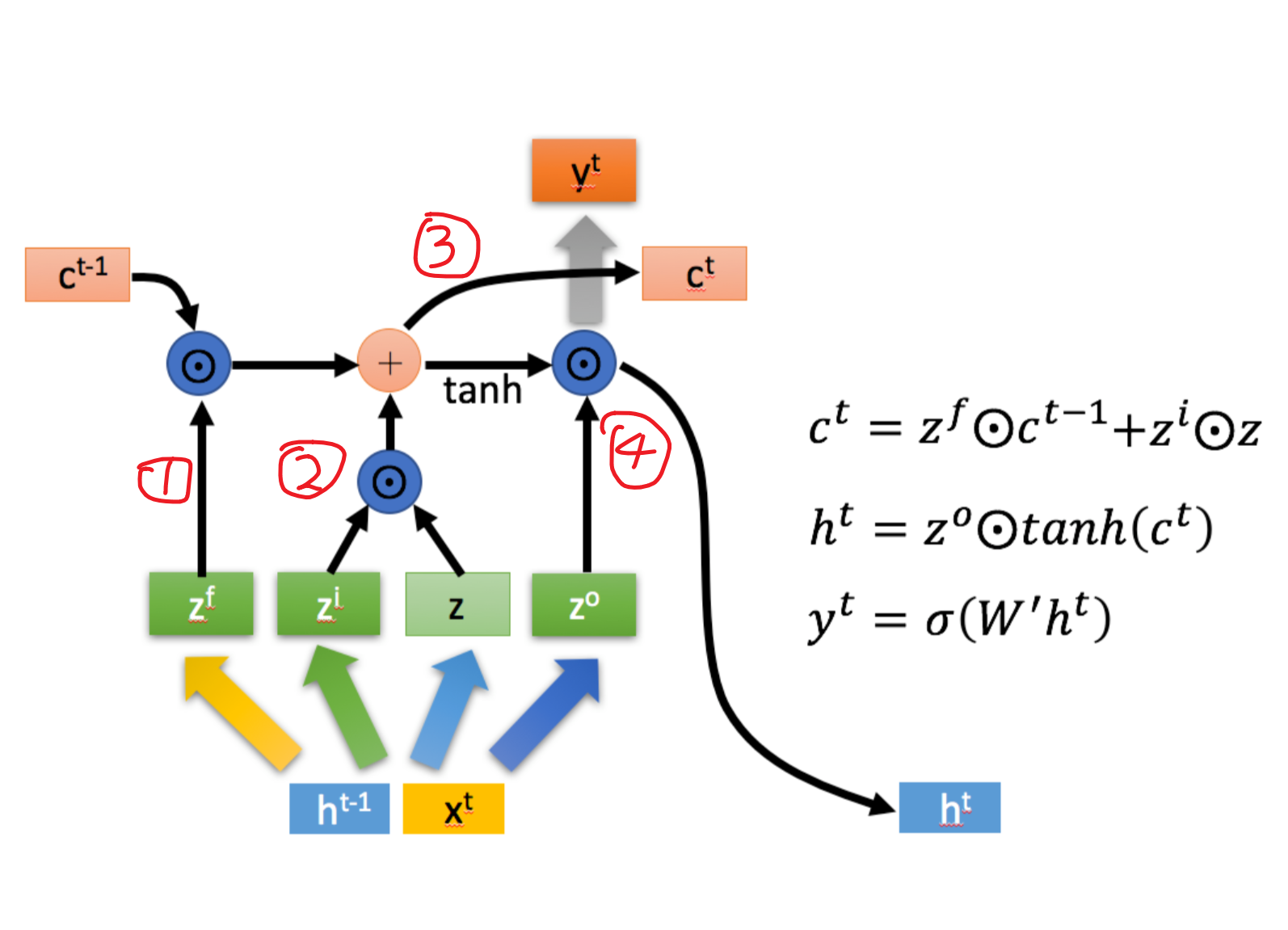
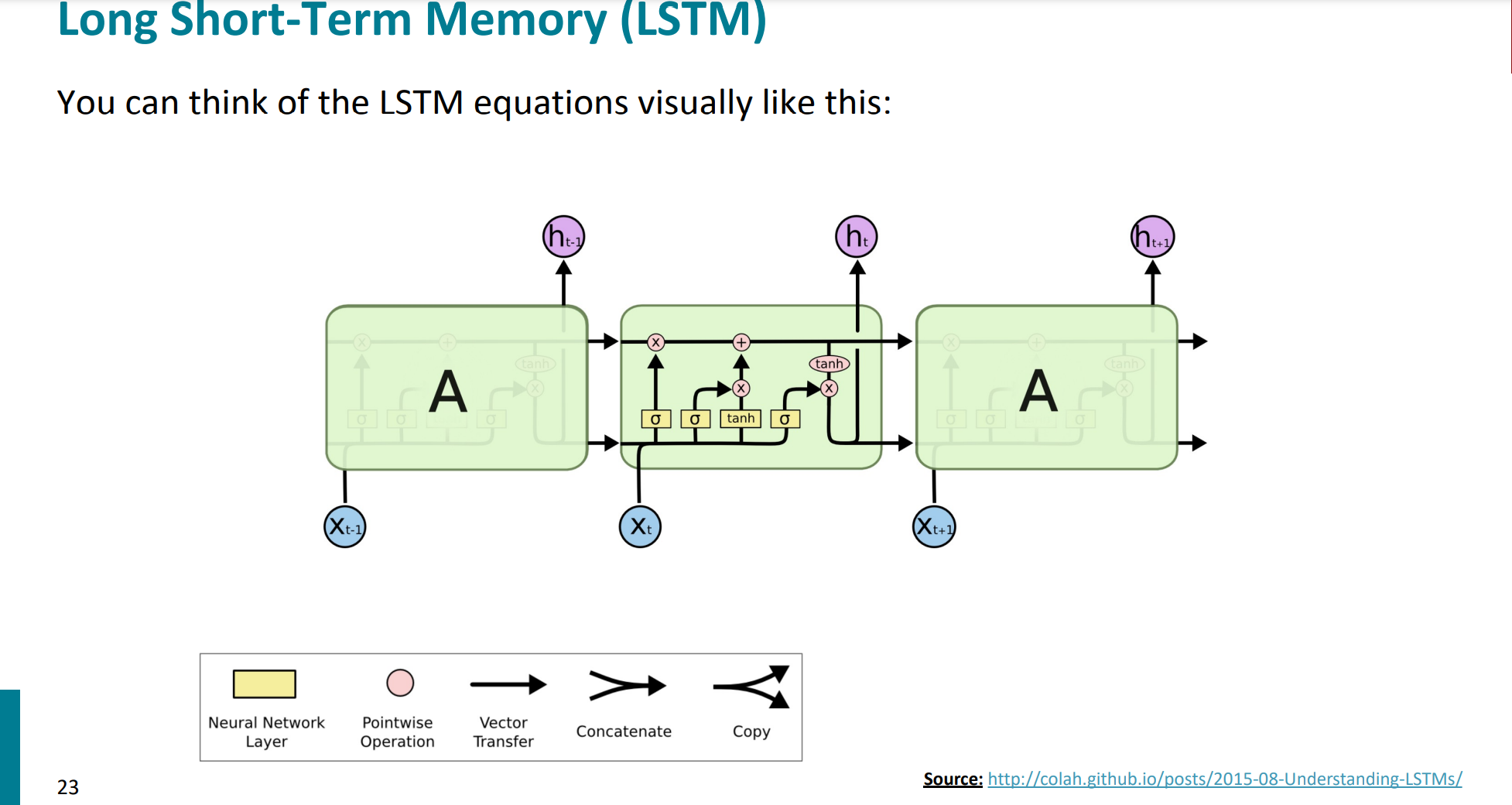
秉持着“一图胜千言”的观点,还是上一个抽象之后的图,感觉可以看这个图把整个的计算过程思路理清楚。
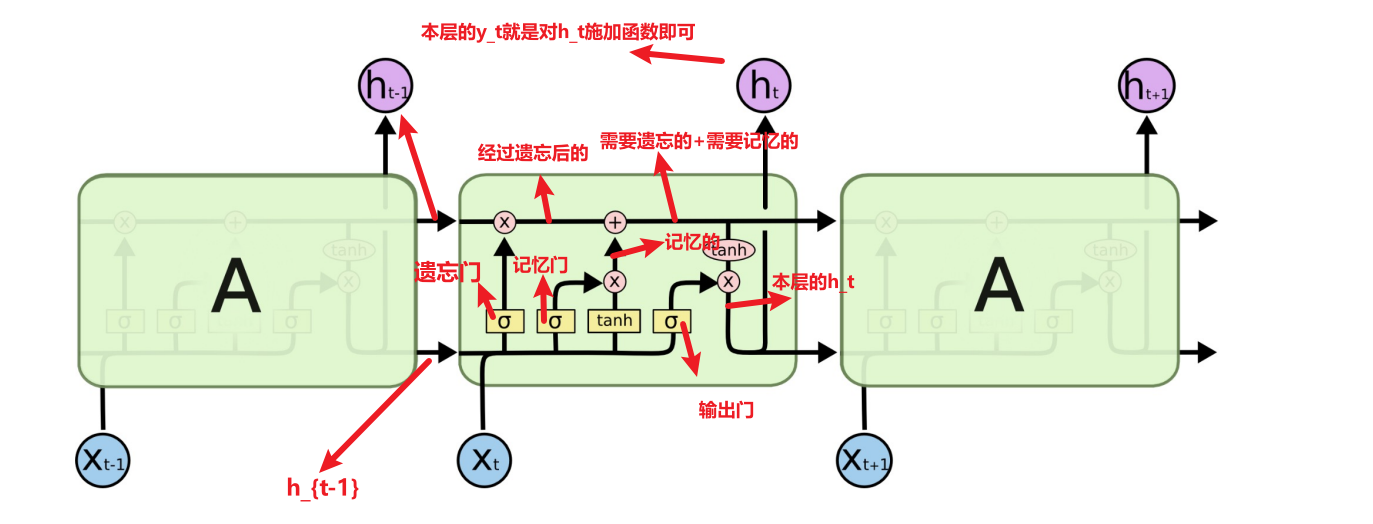
好的,我经过推导和回忆之后,加了注释的图如下,感觉理清思路还是很爽的hh
wc,stanford的下一章slide就是我想干的事儿!只不过人家加了更多的注释!真的太清晰了!
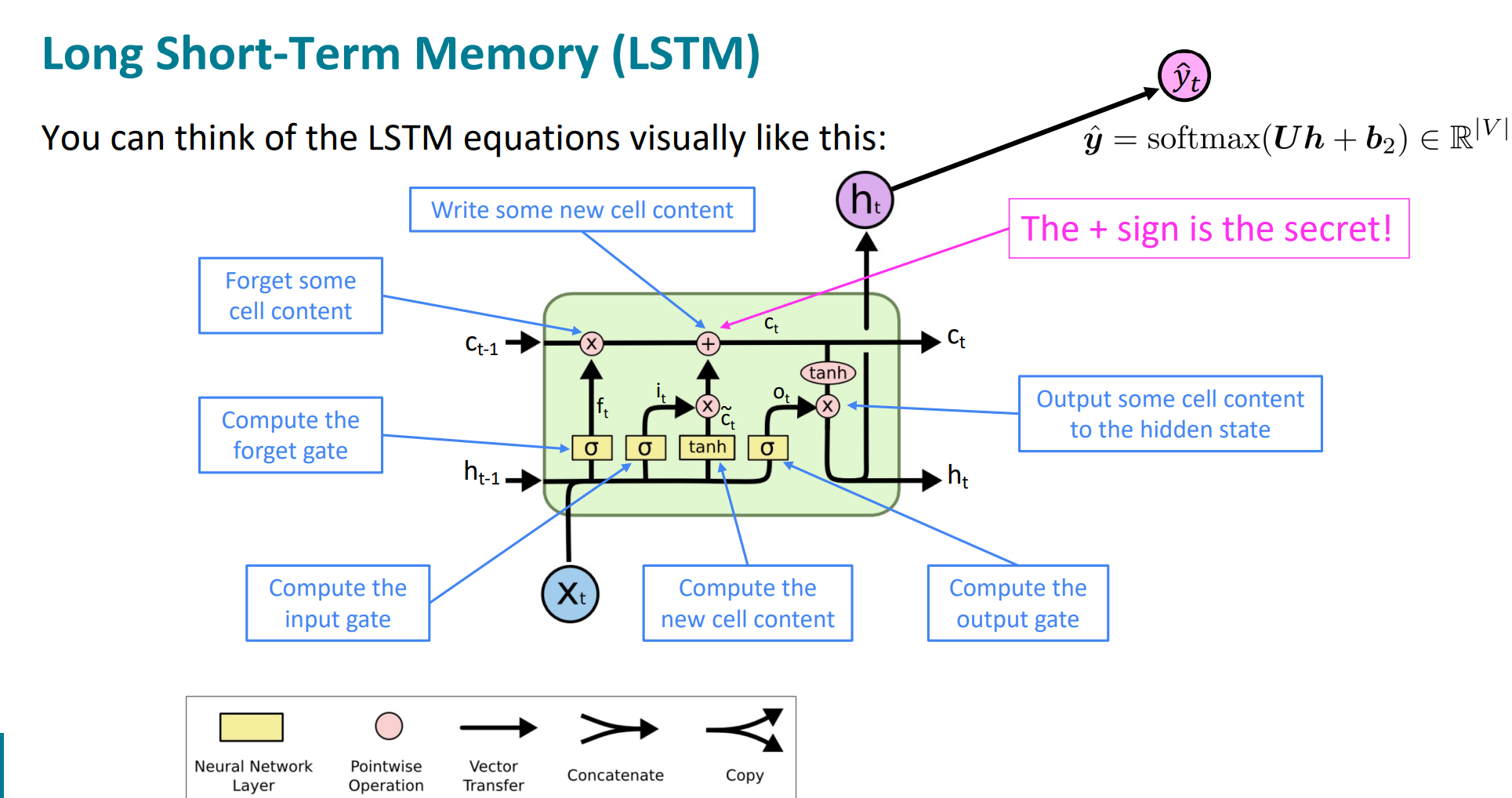
当然,这里还是有几个细节需要注意:
1. 不是所有的激活函数都用sigmoid,只有门控状态是用sigmoid,因为需要控制在0-1之间的数值,但是当前状态信息的计算$z_i$控制的部分,纯内容$z$的计算是用的tanh,本单元的隐藏层输出(也就是下一个隐藏层的输入内容$h_t$)计算时,需要提前将$c_t$用tanh处理一下,控制在了[-1,1]的范围。基本就这俩块儿不用sigmoid。其实也好记,门控机制的用sigmoid是为了控制在0-1内,而非门机制,需要真正计算核心内容的时候,激活函数就很自由和个性化定制了,tanh多一些。
2. 当前的隐藏层状态$h_t$是$c_t$经过一个激活函数$tanh$进行了放缩之后又和$z_o$进行哈达玛积的。
3. 当前单元的输出$y_t$一般都是对于$h_t$施加某种函数进行操作后得出的结果。
4. 为什么lstm就可以规避rnn所存在的梯度消失的问题呢?原因之一就是遗忘门$z_f$,在极端情况下值为1,输入门设置为0的话,这样的话,之前的memory cell的全部信息都会传递下去,使得梯度消失问题不复存在。

这基本就是LSTM的内容了。
我们可以看出来,相比于传统的rnn,lstm多了很多的参数和门控机制,这样通过门控状态来控制传输状态,对长距离信息的记忆效果就提升了很多。因为这样的遗忘门也好,控制门等等也罢,本质都是对“前一状态信息的再加工和选择性处理”,就不再像rnn那样,上一个单元传过来什么就全部记住什么,而是选择性记忆重要的,忘记模型认为不那么重要的。我想,这或许是lstm在长距离任务表现比较出众的重要原因之一。
当然,我们也注意到了,这个参数量感觉比rnn多了好多,也使得训练难度加大了很多。那么就自然有二者的折中方案出现了——使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
下篇就开始展开gru。
参考
https://zhuanlan.zhihu.com/p/63557635
https://web.stanford.edu/class/cs224n/
https://zhuanlan.zhihu.com/p/32085405
