Deep Learning Note7 softmax回归的简洁实现
作者:
 Agoni7z
Agoni7z
,
2024-08-16 02:28:25
,
所有人可见
,
阅读 11
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
# PyTorch不会隐式地调整输入的形状
# 因此,我们在线性层前定义了展平层(flatten)来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# 优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练
num_epochs = 10
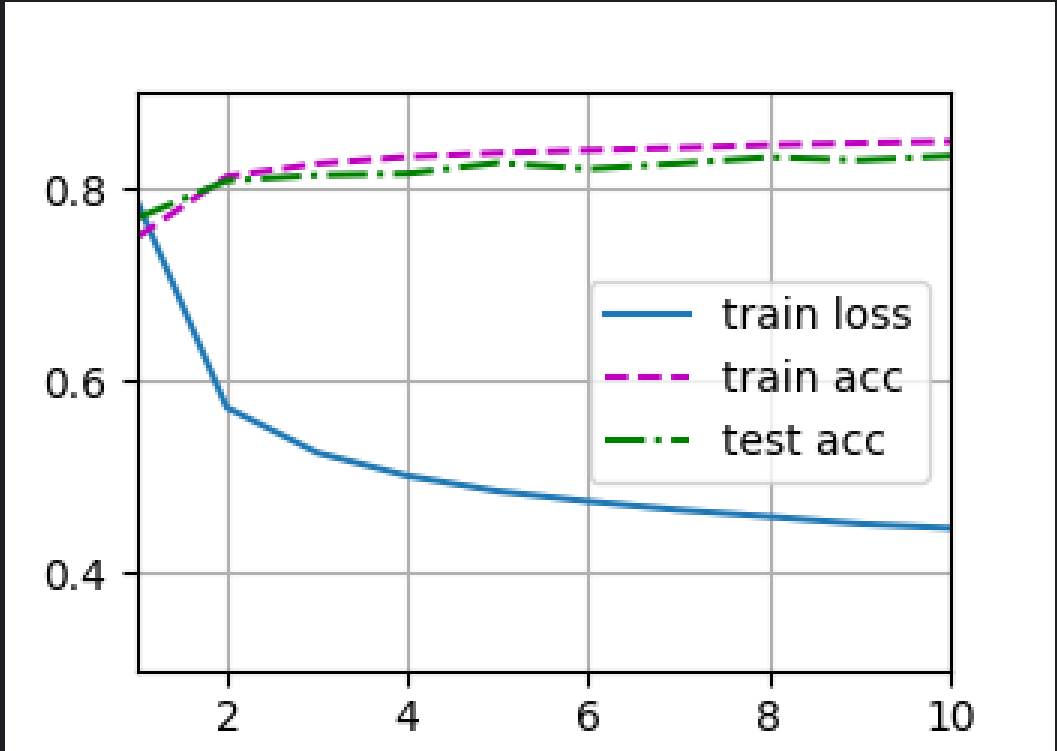
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()