
组合数在考研中的重要性主要体现在概率论中“离散型随机变量”部分,以及数据结构中出栈序列可能涉及的“卡特兰数”,这两类问题在各算法类网站上都能见到,因此本帖将用两节,详细分析用程序求组合数的常用方法。
首先,回顾一下高中数学,组合数的公式如下:
Cmn=AmnAmm=n!m!∗(n−m)!=∏mi=1(n+1−i)∏mi=1i(其中n,m是整数,n≥m)
那么,组合数非常显而易见的一个求法就是硬算:
template <class _Ty>
_Ty combine(int n, int m) {
_Ty ans = _Ty(1);
while (m > 0) { //循环过程中可以同时处理分子分母
ans = ans * (n + 1 - m) / m;
m--;
}
return ans;
}
模板函数combine中,模板参数_Ty可视情况选择各种整数类型(int,long long甚至size_t),如果还不够的话可以用高精度运算方法实现BigInteger类(点击最上面的粉色字可以回顾高精度运算)
在不用BigInteger的情况下如果涉及取模,为了防止溢出,每一次乘法或除法之后都需要对一个数P取模(P大概率是质数),那么在除以m的时候,就需要求m在模P意义下的乘法逆元。在P为质数的情况下,直接用“乘以mP−2”替代“除以m”即可,在P较大的情况下,幂运算可以用快速幂算法。(以下所有方法,全部都用size_t来替代模板参数_Ty)
size_t quickPower(size_t base, size_t power, size_t mod) {
size_t ans = 1;
while (power > 0) {
if (power & 1) ans = (ans * base) % mod;
base = (base * base) % mod;
power >>= 1;
}
return ans;
}
size_t combine(size_t n, size_t m, size_t p) {
size_t ans = 1;
while (m > 0) {
ans = (ans * (n + 1 - m)) % p; //防溢出,每次运算后都要取模
ans = (ans * quickPower(m, p - 2, p)) % p;
m--;
}
return ans;
}
如果直接从阶乘式入手,除了硬算之外,还可以将阶乘转化为少数几个质数的幂运算,这里需要借助算术基本定理,即任何一个大于1的正整数都可以分解成若干质因数的乘积,因此n的阶乘就相当于2∼n中每个数的质因数相乘所得的结果,其中每个质因数p出现的次数为2∼n中每个数产生的p的数量,可以用无穷级数∑+∞i=1⌊npi⌋来表示。到这里可能有人会有疑问:为什么不是∑+∞i=1i∗⌊npi⌋呢?下面以16!中2的出现次数为例来解释。
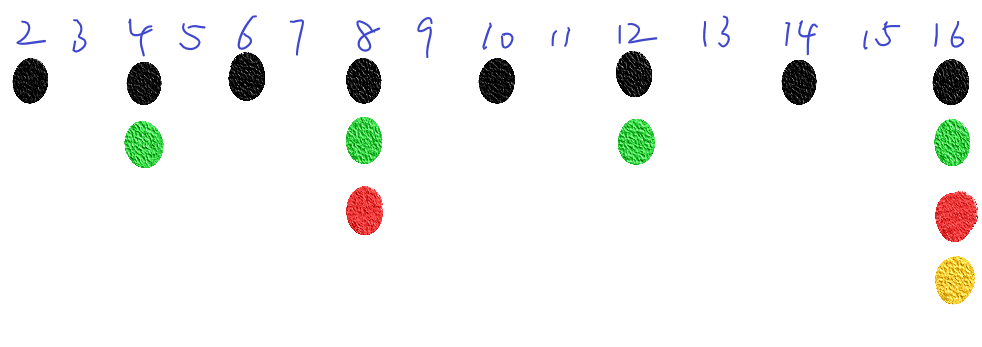
2∼16之间所有的整数包含因数2的个数,显然为15,其中包含1个2的有{2,6,10,14},包含2个2的有{4,12},包含3个2的只有8,而包含4个2的只有16,累加起来即为1∗4+2∗2+1∗3+1∗4=15,可以完美的对应上级数∑+∞i=1i∗⌊npi⌋,其中的每个i都代表“刚好”包含i个因数p的整数个数。而另一个级数∑+∞i=1⌊npi⌋中,每个i则与“至少”包含i个因数p相互对应。至少包含i个因数p就代表着一个数是pi的倍数,比如2∼16之间,2的倍数有8个,4的倍数有4个,8的倍数有2个,16的倍数有1个另外如果一个数至少含有k个因数p,那么它一定会至少含有1,2,…,k−1个因数p。以上图中的16为例,它在被i=4计算到时,在i=1,2,3时一定都会被计算到一次,所以每一轮只需要计算一次。用“至少”的思路去计算,每一轮的目标都是均匀分布,累加的数量呈现1p递减趋势,而用“恰好”的思路去计算,那么每轮的目标分布相对散乱,累加起来比较复杂。
上述的思路基于的是级数∑+∞i=1⌊npi⌋,它不仅可以视作分母依次乘p,还可以视作分子依次除p,为防止溢出,此处采用分子依次除p的方式:
size_t countPrimeFactor(size_t n, size_t p) {
size_t cnt = 0;
while (n > 0) {
cnt += n / p; //整数除法自动向下取整
n /= p;
}
return cnt;
}
解决了质因数统计的问题之后,还有一个需要注意的地方,那就是组合数Cmn计算的阶乘式中,最大的项为n!,因此只有不大于n的质数才会对结果产生影响。所以在统计之前,还需要做的一件事就是筛选出不大于n的质数,这里可以使用欧拉筛(EulerSieve)。
从阶乘入手,分解质因数的方法,完整函数代码如下:
size_t combine(size_t n, size_t m, size_t p) {
size_t ans = 1;
Sieve* sieve = new EulerSieve;
int len = (*sieve)(n); //n一定大于m和n-m,只要筛一次就行
for (int i = 0; i < len; i++) {
size_t x = sieve->primes[i]; //待统计的质因数
size_t cnt = countPrimeFactor(n, x) //出现在分母上的m!和(n-m)!需要对应相减
- countPrimeFactor(m, x)
- countPrimeFactor(n - m, x);
ans = (ans * quickPower(x, cnt, p)) % p;//继续使用逆元法中的快速幂
}
delete sieve;
return ans;
}
除了从公式直接入手以外,组合数还有两个重要性质,这两个性质同样可以用于组合数的求解,详情请见下节
