
李弘毅老师tql8
meta machine learning(MAML)和model pretraining(模型预训练)的区别在于
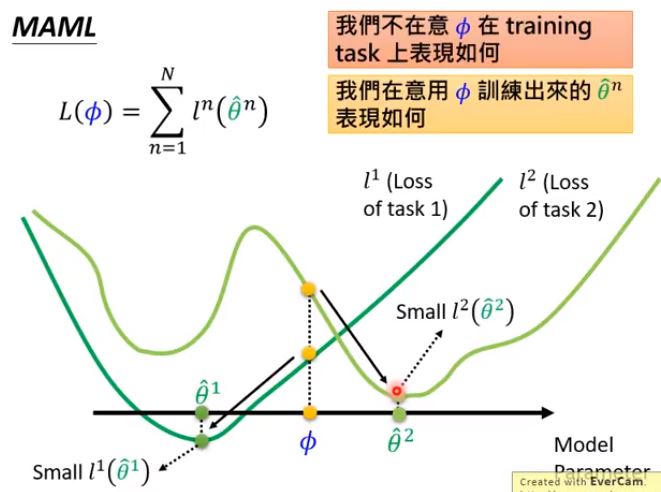
MAML的优化目标是让模型初始化$\color{#FF0000}{后}$能在$\color{#FF0000}{将来}$不同的task上都能收敛到全局最优
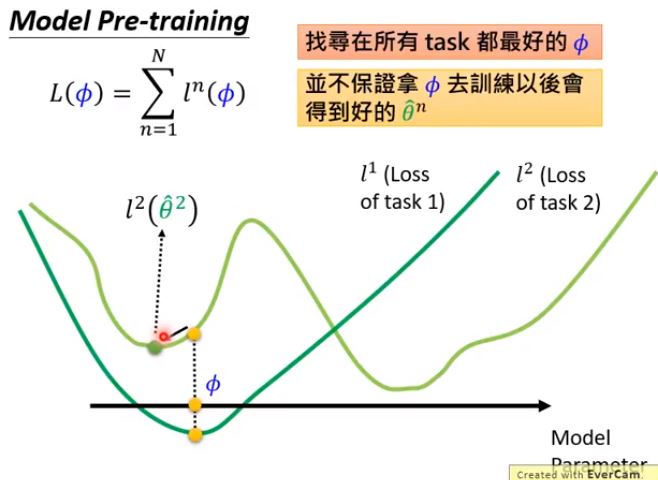
模型预训练的优化目标是让模型初始化$\color{#FF0000}{时}$在不同的task同时表现的比较好(但$\color{#FF0000}{将来}$去做每个task的时候可能陷入局部最优)
公式上的区别

MAML直观效果
模型预训练直观效果
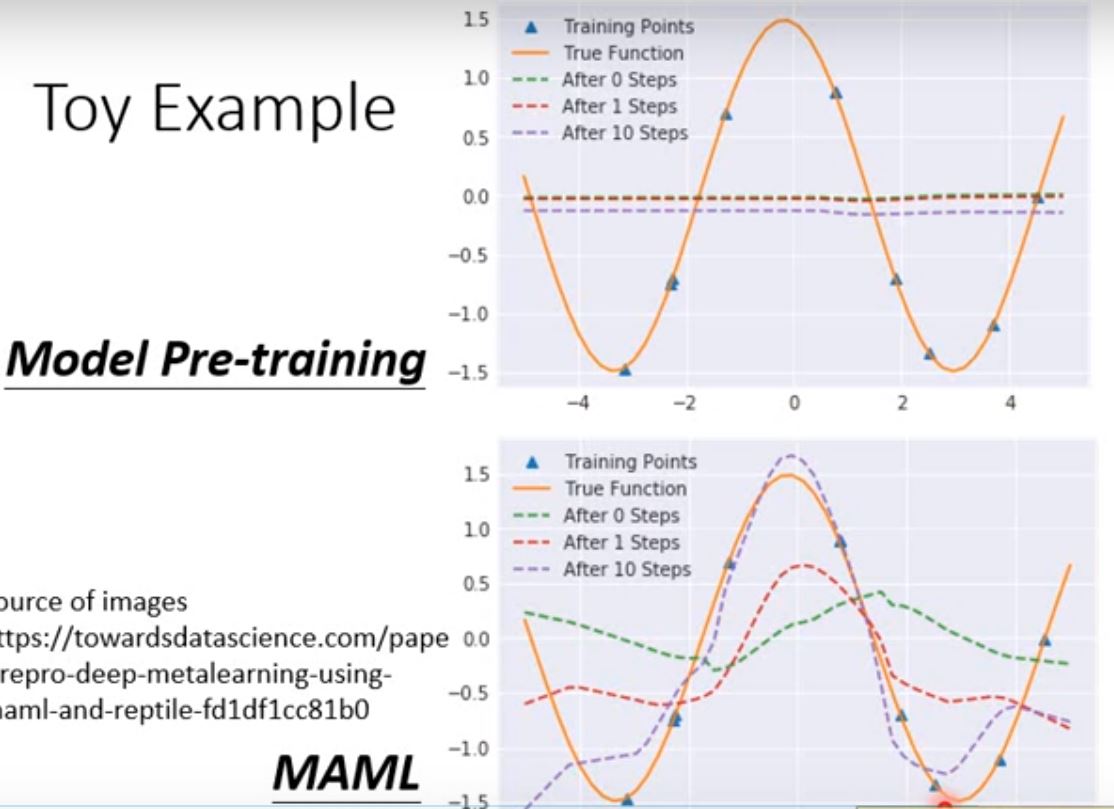
toy example:
类比 神经网络集合 <=> 三角函数集合
一个网络参数 <=> 某个三角函数
对k个任务 <=> 对k个三角函数
做pretrained <=> k个三角函数的平均->直线
做MAML <=> 对每个三角函数训练一次并反向传播 初始化三角函数
在目标任务测试<=> 目标三角函数采样点
把初始化三角函数$asin(x+b)$
可以发现$\phi$作为初始权重对$\theta$求导的过程中,二阶导部分接近零近似约掉(跟以前力学分析时很像有木有)


梯度直观感受
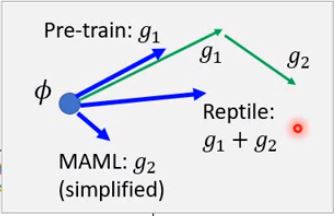
model-pretrained 相当于在每一个任务更新了一步之后得到的$\theta$ 让$\phi$朝$\theta$走
MAML 则是更新了一步之后得到的$\theta$再求梯度 让$\phi$朝$\frac{l_{\theta}}{d\theta}$走
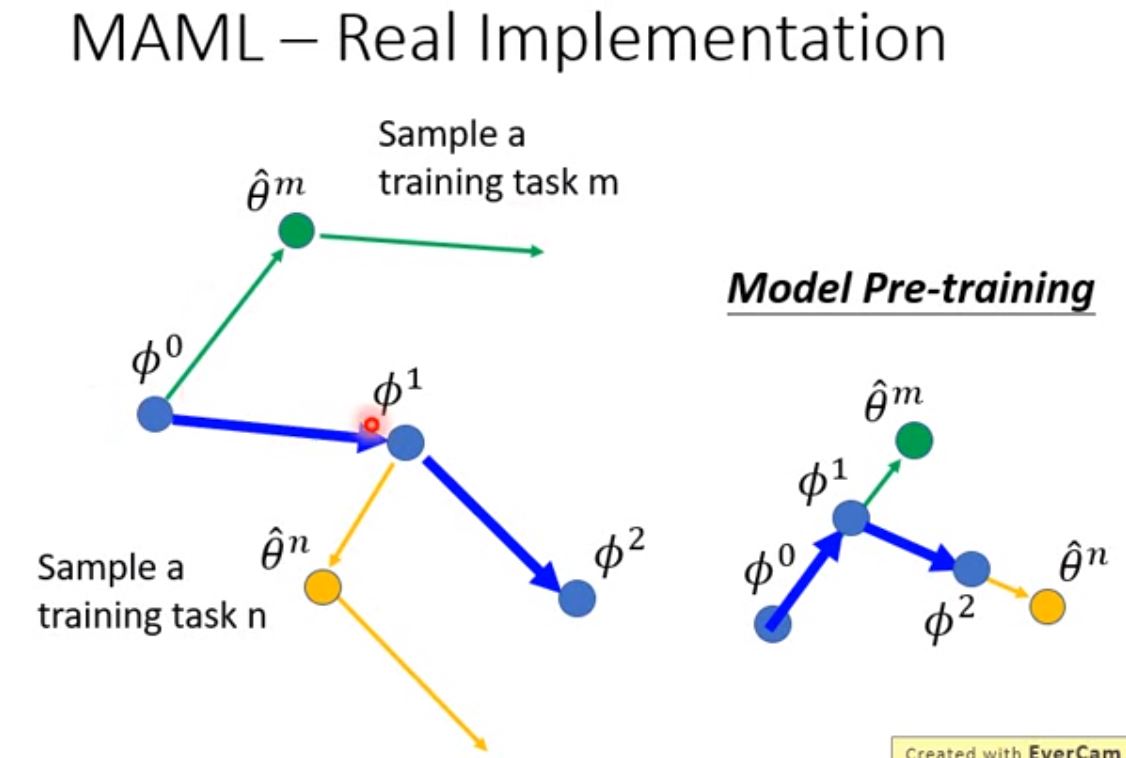
Reptile 梯度方向(只考虑两步时)相当于 MAML+pretrained model

除了参数初始化可以通过网络学之外,网络架构和学习率也是可以学的
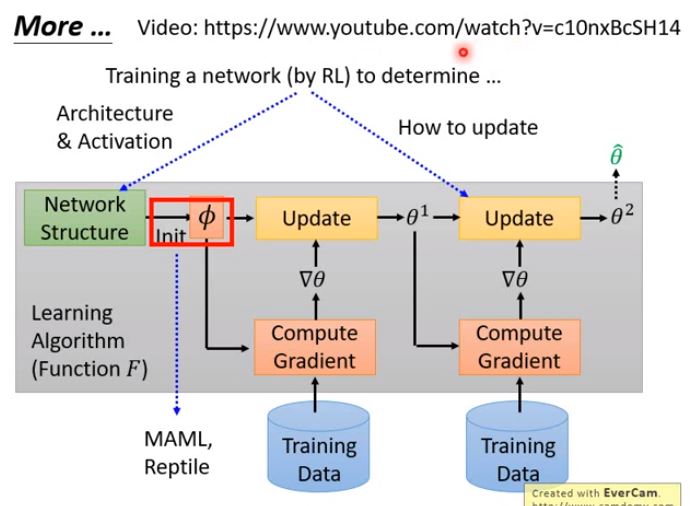
那么问题来了$\phi$自己的初始化又是从哪来的?
-> learn
-> learn to learn
-> learn to learn to learn

完全没看懂【笑哭】