
论文链接
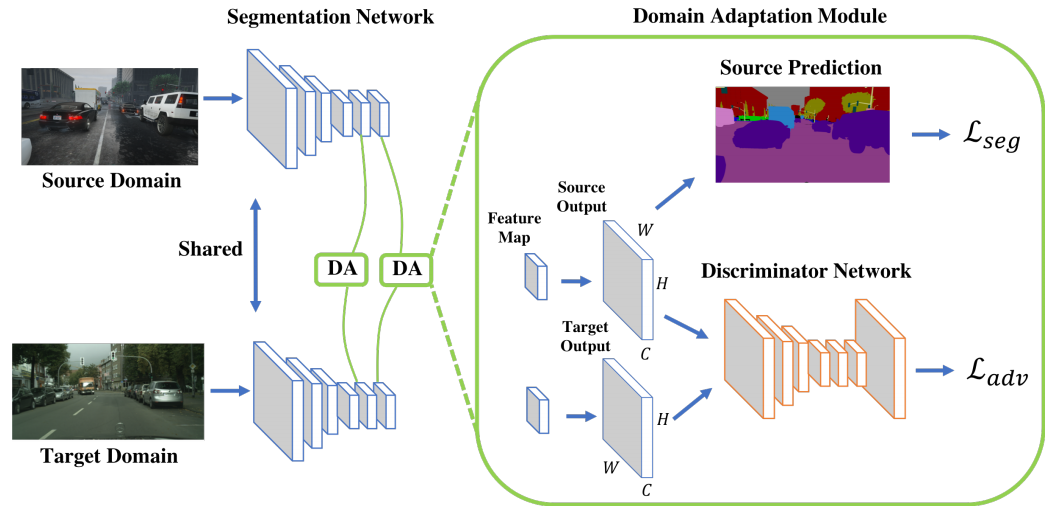
As the labeling process is tedious and labor intensive, developing algorithms that can adapt source ground truth labels to the target domain is of great interest. In this paper, we propose an adversarial learning method for domain adaptation in the context of semantic segmentation.
Considering semantic segmentations as structured outputs that contain spatial similarities between the source and target domains, we adopt adversarial learning in the output space. To further enhance the adapted model, we construct a multi-level adversarial network to effectively perform output space domain adaptation at different feature levels.
对于自动驾驶中语义分割任务, 由于标记过程繁琐且费力,因此提出了一种在语义分割的上下文中进行领域自适应的对抗学习方法来用GTA5数据(自带标注,源域)训练,并将真实世界(标注很少,目标域)特征对齐到源域特征,从而不用在真实世界标注大量数据。
主要看三个损失
$$
\mathcal{L}{d}\left(P\right)=-\sum_{h, w}(1-z) \log \left(\mathbf{D}(P)^{(h, w, 0)}\right)+z \log \left(\mathbf{D}(P)^{(h, w, 1)}\right)
$$
where z = 0 if the sample is drawn from the target domain,and z = 1 for the sample from the source domain.
第一个损失 训练一个discriminator区分分割语义图是来自目标域还是源域
当z=0(来自目标域时),则只剩第一项-logD(p)0越小logD(p)0越大D(p)0越大-D能区分出来自目标域的分割图
来自源域 z=1,那么第二项-logD(p)1越小logD(p)1越大D(p)1越大-D能区分出来自源域的分割图
$$ \mathcal{L}{s e g}\left(I{s}\right)=-\sum_{h, w} \sum_{c \in C} Y{s}^{(h, w, c)} \log \left(P_{s}^{(h, w, c)}\right) $$
第二个损失,Y为语义分割标签,P为语义分割概率,即我们想要-logP[h,w]位置上输出第c类的概率*第c类标签(非c类0,c类1)越小,即让logP[h,w]位置上输出第c类的概率越大,即让P[h,w,c]越大
for images in the target domain, we forward them to G and obtain the prediction Pt = G(It). To make the distribution of Pt closer to Ps, we use an adversarial loss Ladv in (1) as:
$$ \mathcal{L}{a d v}\left(I_{t}\right)=-\sum \log \left(\mathbf{D}\left(P_{t}\right)^{(h, w, 1)}\right) $$
第三个损失,对于目标域图(真实图),我们想要训练G生成的预测图Pt=G(It)的分布越接近Ps(G(Is))越好,那么就是让这Pt在之前训练好的D上预测为来自源域的概率越大越好
源域 z=1,那么-logD(Pt)1越小logD(Pt)1越大D(Pt)1越大 D被G(目标域图It)生成的Pt“欺骗”了,将实际上来自目标域的分割图被判定为来自源域的分割图。
This loss is designed to train the segmentation network and fool the discriminator by maximizing the probability of the target prediction being considered as the source prediction.
那么在这个过程中,目标域图像在G中间生成的语义特征就和源域拉近了(G对目标域生成的语义特征和源域生成的语义特征差别变得很小),那么在源域上训练的分类器就可以用于G(It)了,即我们就可以用在源域(GTA5)上训练的网络去对目标域(真实世界)的数据进行语义分割任务
