
Mysql Join
全当大家都已经知道 join 语法了,不知道可以回复,回头写一篇基础的。
Mysql Join 涉及的算法,以及注意事项,潜在的优化策略
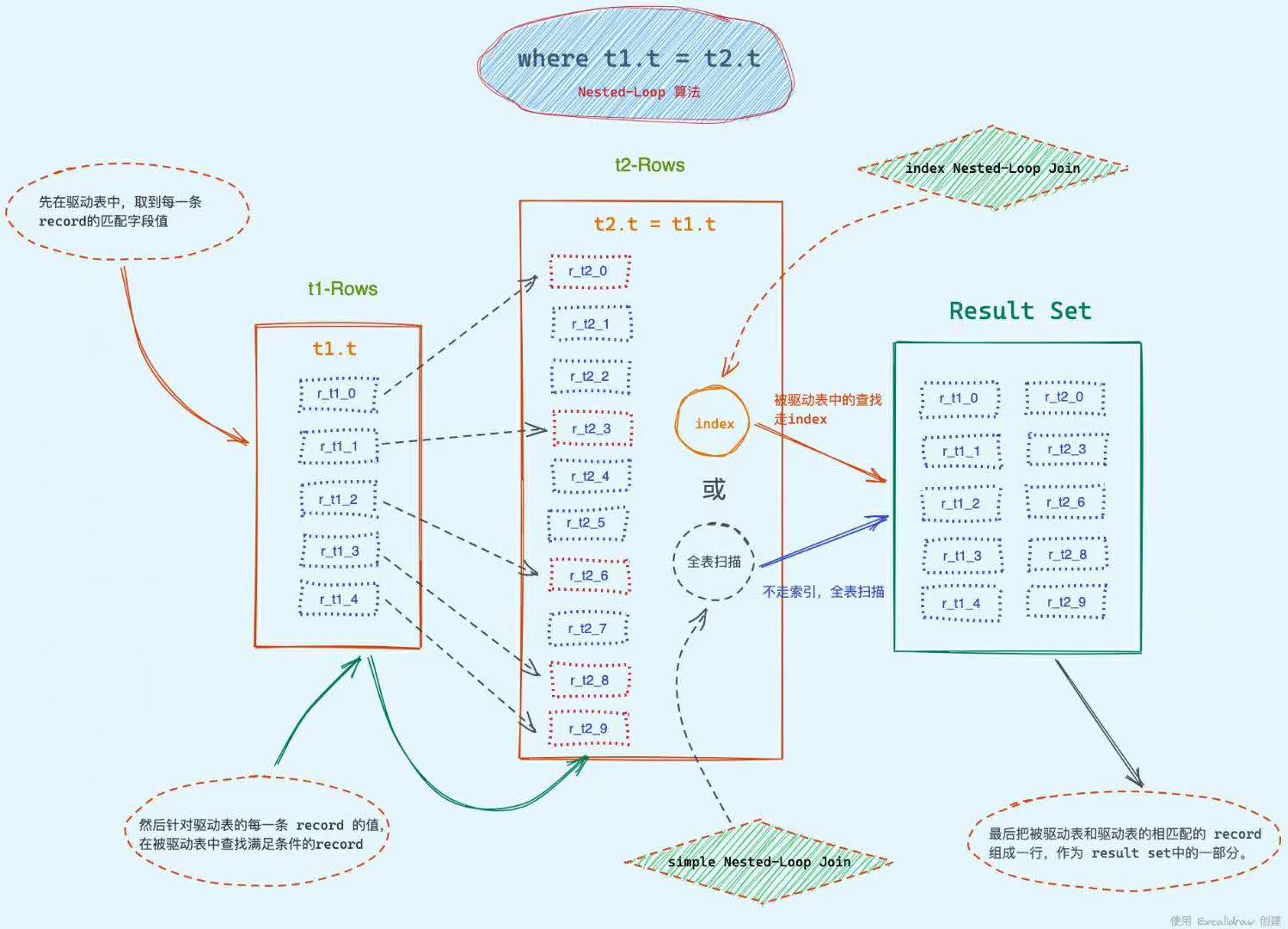
Index Nested-Loop Join
select * from t1 straight_join t2 on (t1.a=t2.a);
-
被驱动表存在
index【主键,普通index都行】 -
查询过程:
-
驱动表【全表扫描】,每次取一条;
-
遍历全部:
- 从每一行取出字段 a 的值 $R.a
- 执行
select * from t2 where a=$R.a;【因为有索引,走tree search】 - 把返回的结果和 R 构成结果集的一行。
驱动表是走全表扫描,而被驱动表是走树搜索
结论:
- 使用 join 语句,性能比强行拆成多个单表执行 SQL 语句的性能要好;
- 如果使用 join 语句的话,需要让小表做驱动表。
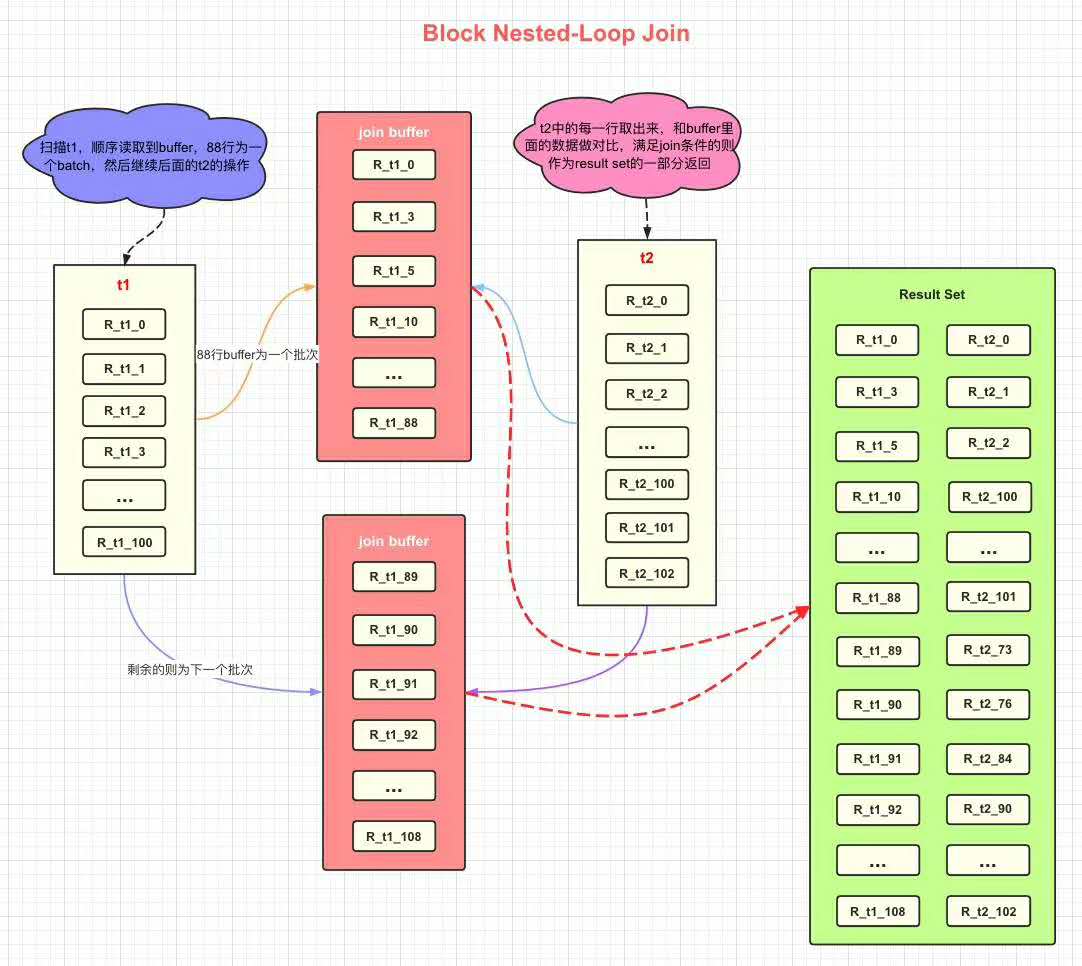
Block Nested-Loop Join
-- 被驱动表没有 `index`
select * from t1 straight_join t2 on (t1.a=t2.b);
- 顺序读取
t1放入join_buffer,直至join_buffer_sizemax - 扫描
t2,每一行取出,和join_buffer的一行数据对比,满足条件,放入join_buffer - 作为结果集返回
- 如果还有数据需要扫描,清空
join_buffer,继续1 2
结论:
- 在 join_buffer_size 足够大的时候,是一样的;
- 在 join_buffer_size 不够大的时候(这种情况更常见),应该【选择小表做驱动表】。
小表的定义
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
例如:
-- 1. t2 在 where 里面会筛选 50 个
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50;
-- 2. t1 只选择 b 这一列 -> 加入 join_buffer 的数据量少于 t2 的全列
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
-- 也就是说,会先对 where 中的 过滤条件 先进行 [表数据过滤],这个也是值得优化的点
