
9.23
BGD,MBGD,SGD对比:
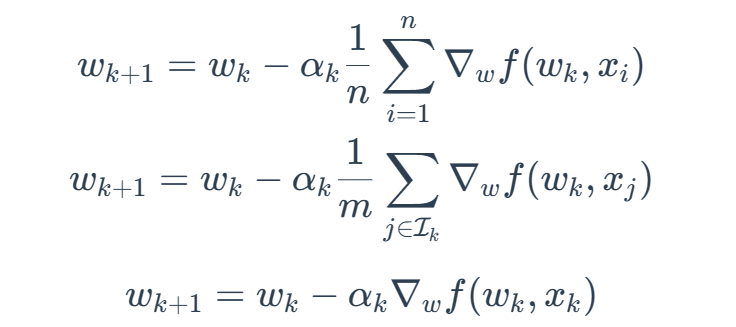
if m=1,MBGD就变成了SGD
if m=n,MBGD不会完全等价于BGD
因为BGD会使用全部n个采样,但是MBDG会从其中进行选择。
值函数近似:
例如,我们用简单的直线去拟合几个点:
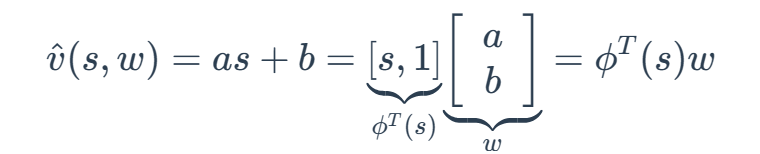
其中w是parameter vector(参数向量)
ϕT(s)是s的feature vector(特征向量)
ˆv(s,w)和w呈线性关系
基于通信的多智能体强化学习进展综述
MARL(multi-agent reinforcement learning)
多智能体强化学习
MAS(multi-agent system)
多智能体系统
Actor-Critic
策略近似的同时还引入了值函数的近似,并且策略是基于值函数的评价而更新的,称为Actor-Critic
FL(Federal learning)
SARL:single-agent RL
智能体与环境的交互过程可以被建模为马尔可夫过程
立即奖励和长期的累计奖励
Reinforcement更新方式:
θt+1←θt+αRt∇π(At;St,θt)π(At;St,θt)
策略梯度的优化函数:
L=∑logπθ(st,at)(r+γV(st+1)−V(st))
DQN(Deep Q-Learning):
引入了(1)经验回放:有一个记忆库用于存储之前的轨迹,Q-learning is off-policy 可以学习过去的experience
(2)目标Q网络:使用两个神经网络:评估Q网络(正确速度更新)和目标Q网络(更新速度较慢)
Double DQN:引入解耦目标Q值、目标Q值 用以消除过度估计
Dueling DQN: 将Q网络分成两部分:
第一部分与state有关 —>价值函数有关
第二部分与state和action均有关—>优势函数有关
POMDP:partially observable MDP:部分可观测的MDP
在MARL中,改进了经验回放池,提出了指纹标记法:可以标识采样数据的新旧程度的值函数
CB-MADRL(Communication Based MADRL)
基于通信的多智能体强化学习
两种通信方式:RIAL和DIAL
RIAL(Reinforced Inter-Agent Learning):有两种不同的处理方式,一种是无参数共享的,每个agent学习自己的网络,将其他agent视为环境的一部分;另一种是参数共享的,所有agent训练一个网络,但是策略的执行仍然是分散的,由于在执行时会看到不同的观测,因此不同agent仍然会产生不同的行为。
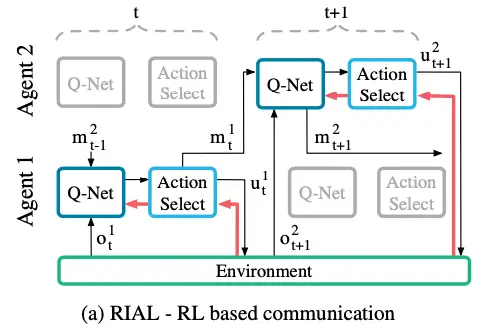
但是这种方法产生的问题是agent之间不会就他们的通信行为向对方提供反馈。
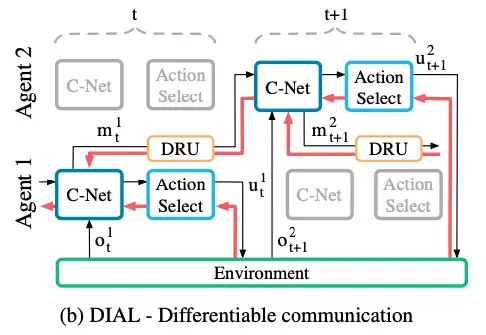
因此提出了第二种DIAL(Differentiable 可微分的 Inter-Agent Learning),在集中式学习的基础上提供了除参数共享以外更有效的通信学习方式,可以跨agent进行端到端的训练,即agent之间有梯度传递,这种agent间的梯度传递形成了椅子通信反馈机制。
DRQN(deep recurrent Q-network)深度循环Q网络
IQL(independent Q-learning)独立Q学习
DDRQN(deep distributed recurrent Q-network)
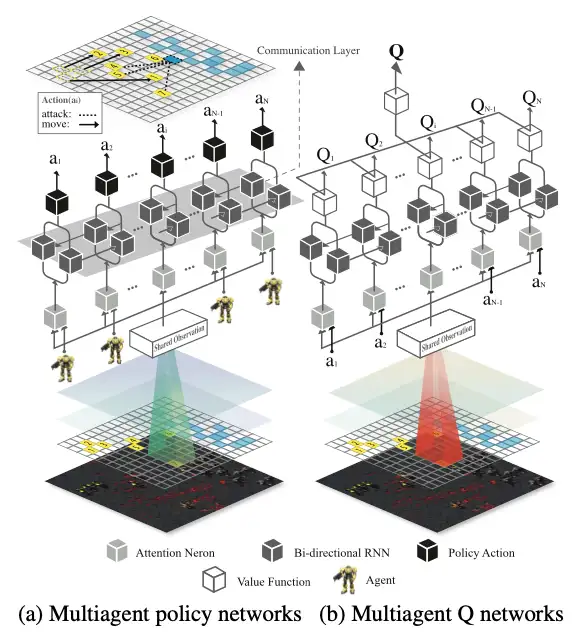
BiCNet结构:
将以往CommNet中负责通信的全连接层替换为一个双向的RNN(循环神经网络),不同于CommNet显式地在agent之间进行通信,BiCNet通过双向RNN实现隐层通信。
MD-MADDPG(memory driven(内存驱动)MADDPG)
A3C架构:
A3C是Google DeepMind 提出的一种解决Actor-Critic不收敛问题的算法。
简单来说:A3C会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.
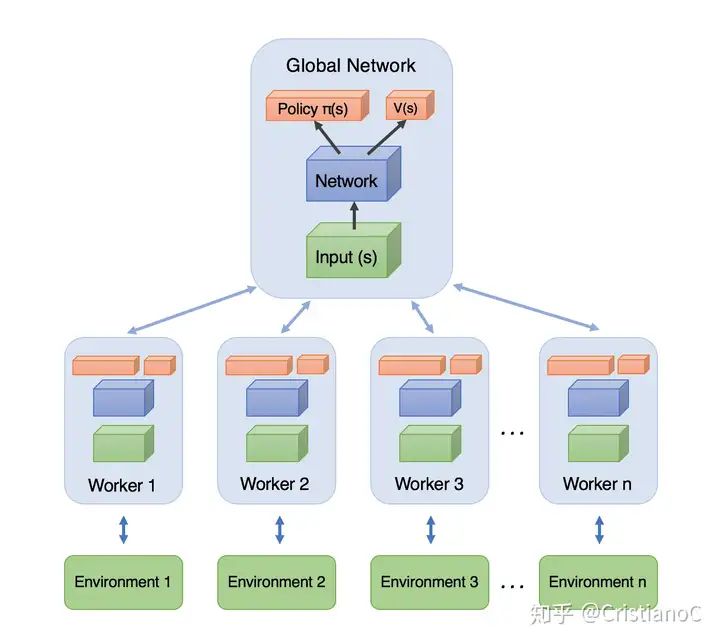
A3C的算法实际上就是将Actor-Critic放在了多个线程中进行同步训练. 可以想象成几个人同时在玩一样的游戏, 而他们玩游戏的经验都会同步上传到一个中央大脑. 然后他们又从中央大脑中获取最新的玩游戏方法。
