
mysql 安装配置
-
下载后复制bin这个路径 D:\software\mysql-5.7.41-winx64\bin (根据文件所在路径而定)
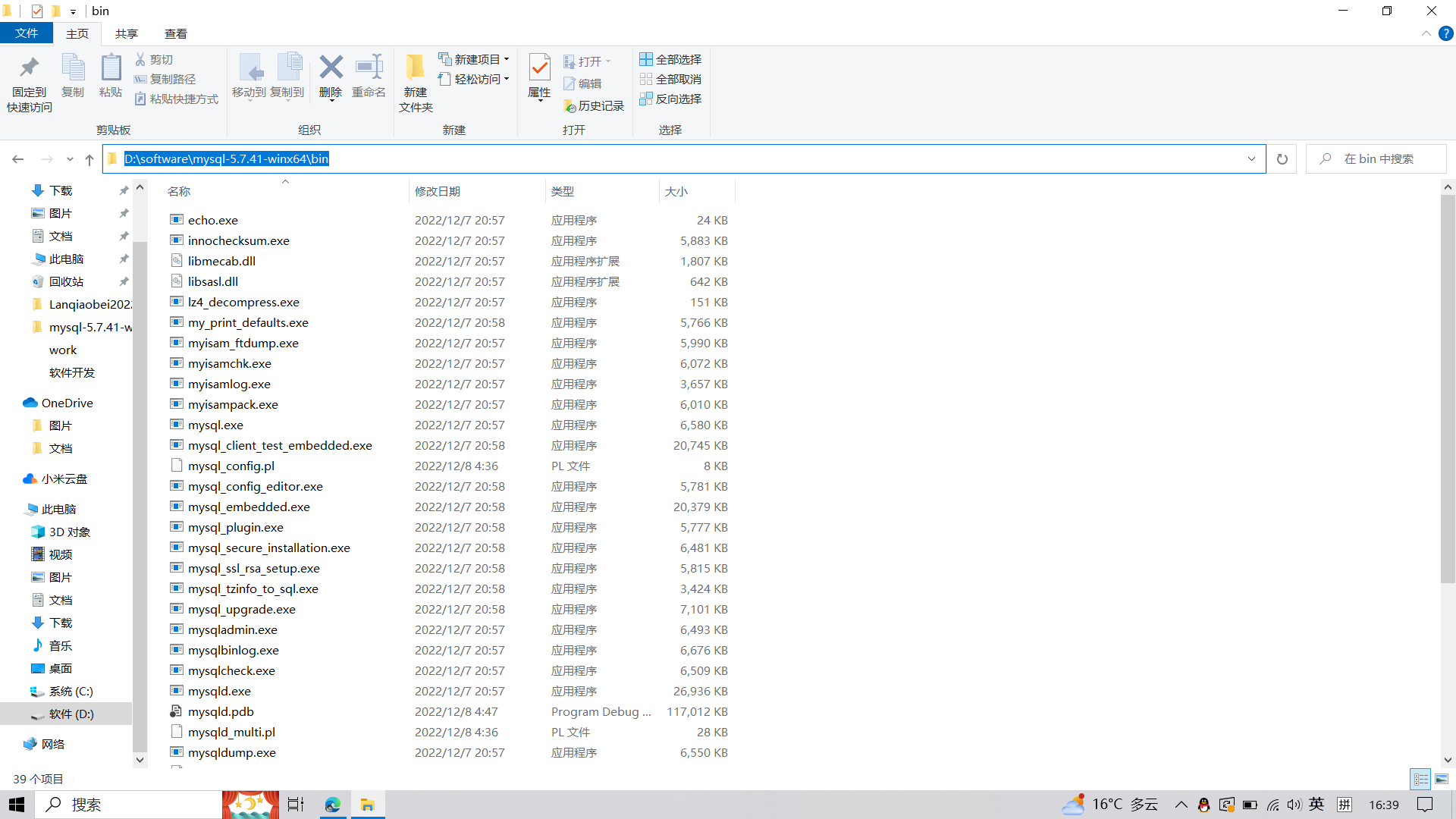
- 给电脑配置系统变量
- 高级系统设置 -> 环境变量 -> path -> 将这个路径粘进去 D:\software\mysql-5.7.41-winx64\bin (根据文件所在路径而定)
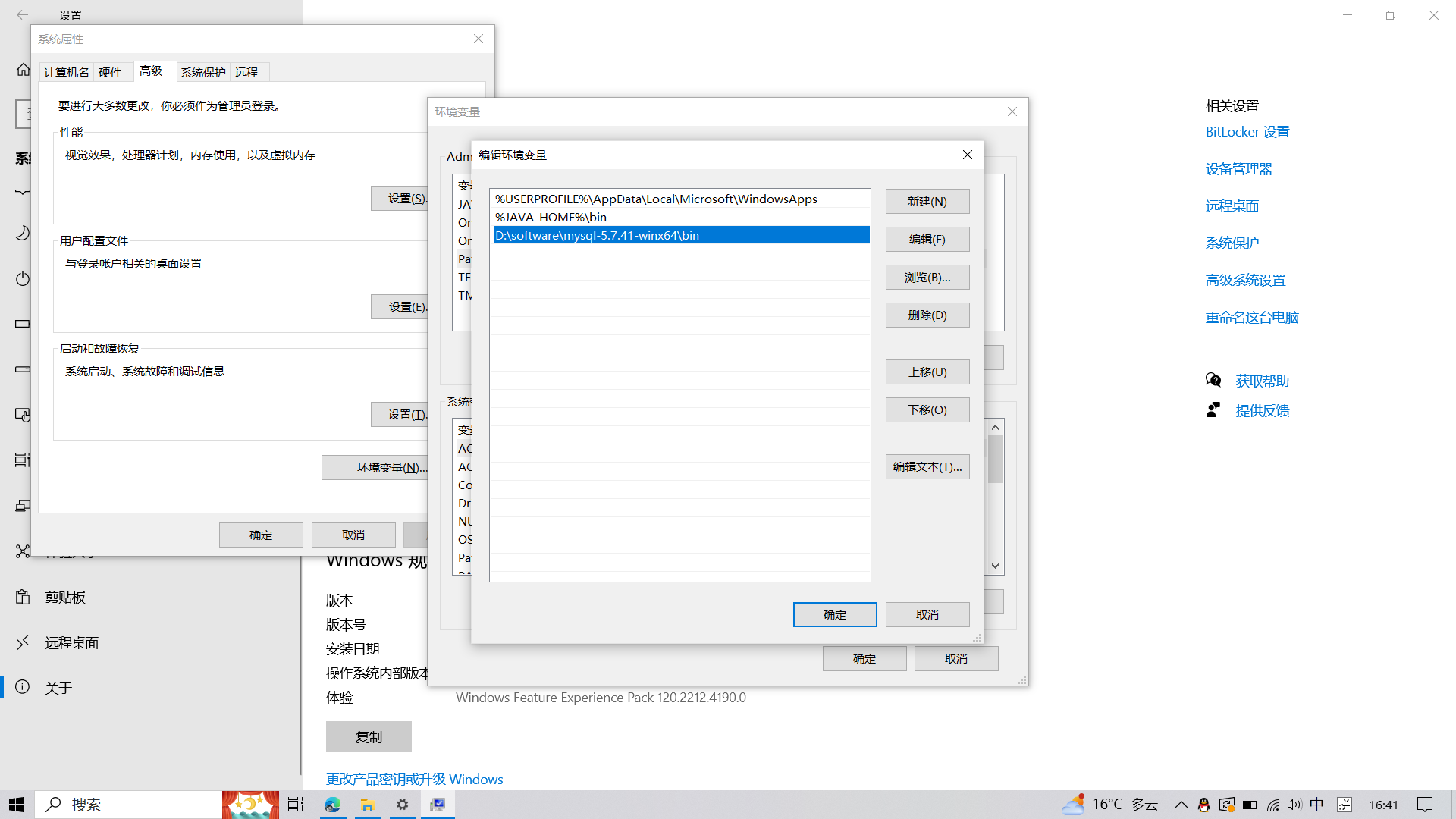
- 在下载的包里添加一个 my.ini 文件
txt
[Client]
#设置3306端口
port = 3306
[mysqld]
#设置3306端口
port = 3306
# 设置mysql的安装目录(根据文件所在路径而定)
basedir=D:\\software\\mysql-5.7.41-winx64\\
# 设置mysql数据库的数据的存放目录(根据文件所在路径而定)
datadir=D:\\software\\mysql-5.7.41-winx64\\data\\
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
#跳过安全检查
skip-grant-tables
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
- 再打开dos命令窗口 (注意是以管理员身份打开)
1.切换根路径
cd /d D:\software\mysql-5.7.41-winx64\bin(根据文件所在路径而定)
2.然后输入
mysqld -install
成功会提示 service successfully installed
3.然后初始化数据库,输入后再原来的mysql文件里会多一个data文件
mysqld –initialize-insecure –user=mysql
4.再启动MySQL服务器
net start mysql
5.再配置用户与密码
mysql -u root -p
-u 表示用户名, -p 表示密码 初始时不用配置后面修改即可
输入后会弹出 password: 这里没有配置密码直接回车即可
6.修改root密码
use mysql;
update user set authentication_string=password(‘这里输入修改后的密码’) where user = ‘root’ and Host = ‘localhost’;
flush privileges; (刷新权限)
exit; (关闭数据库)
然后在my.ini里的 skip-grant-tables 注释掉 加个#, 不然修改后的密码也是可以被跳过的
关闭数据库
net stop mysql
mysql基础语法
SQL 简介
-
SQL: 一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
-
SQL 通用语法
-
SQL 语句可以单行或多行书写,以分号结尾。
- SQL 语句可以使用空格/缩进来增强语句的可读性。
- MySQL 数据库的 SQL 语句不区分大小写。
-
注释:
- 单行注释:– 或 #
- 多行注释: /**/
-
SQL 分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definiton Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户/控制数据库的访问权限 |
数据库设计 DDL
数据库 DB
查询数据库
# 查询所有的数据库
show databases;
show schemas;
# 查询当前数据库
select database();
select schema();
使用数据库
# 使用数据库
use 数据库名;
创建数据库
# 创建一个 自定义名称 数据库
create database [if not exists] 数据库名;
create schema [if not exists] 数据库名;
/*
如果出现重复创建会报错:
Can't create database '数据库名'; database exists
可以通过加入 if not exists 语句将判定为:
如果不存在就不会执行,所以不报错
*/
删除数据库
# 删除数据库
drop database [if exists] 数据库名;
drop schema [if exists] 数据库名;
表(创建,查询,修改,删除)
创建表
create table 表名(
字段1 字段类型 [约束] [comment 字段1注释],
...
字段n 字段类型 [约束] [comment 字段n注释]
)[comment 表注释];
- 约束
- 约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 保证数据库中数据的正确性、有效性和完整性。
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为 null | not null |
| 唯一约束 | 保证字段的所有的数据是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key (auto_increment 自增) |
| 默认约束 | 保存数据时,如果未指定改字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
数据类型
- 数值类型
- 字符串类型
- 日期时间类型
数值类型
| 类型 | 大小(byte) | 描述 | 备注 |
|---|---|---|---|
| tinyint | 1 | 小整数值 | |
| smallint | 2 | 大整数值 | |
| mediumint | 3 | 大整数值 | |
| int | 4 | 大整数值 | |
| bigint | 8 | 极大整数值 | |
| float | 4 | 单精度浮点数值 | float(5, 2): 5 表示整个数字长度,2表示小数位数个数 |
| double | 8 | 双精度浮点数值 | double(5, 2): 5 表示整个数字长度,2表示小数位数个数 |
| decimal | 小数值(高精度) | decimal(5, 2): 5 表示整个数字长度,2表示小数位数个数 |
字符串类型
| 类型 | 大小(bytes) | 描述 |
|---|---|---|
| char | 0-255 | 定长字符串 |
| varchar | 0-65535 | 变长字符串 |
| tinyblob | 0-255 | 不超过255个字符的二进制数据 |
| tinytext | 0-255 | 短文本字符串 |
| blob | 0-65,535 | 二进制形式的长文本数据 |
| text | 0-65,535 | 长文本数据 |
| mediumblob | 0-16,777 | 二进制形式中等长度文本数据 |
| mediumtext | 0-16,777 | 中等长度文本数据 |
| longblob | 0-4,294,967,295 | 二进制形式的极大文本数据 |
| longtext | 0-4,294,967,295 | 极大文本数据 |
日期类型
| 类型 | 大小(byte) | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| date | 3 | 1000-01-01 ~ 9999-12-31 | YYYY-MM-DD | 日期型 |
| time | 3 | -838:59:59 ~ 838:59:59 | HH:MM:SS | 时间值或者维持时间 |
| year | 1 | 1901 ~ 2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestemp | 4 | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
表结构操作
DDL: 查看表结构
-- 查看当前数据库下的表
show tables;
-- 查看指定表结构
desc tb_emp;
-- 查看数据库的建表语句
show create table tb_emp;
DDL:表操作
-- 添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
-- 修改字段类型
alter table 表名 modify 字段名 新数据类型(长度);
-- 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
-- 删除字段
alter table 表名 drop column 字段名;
-- 修改表名
rename table 表名 to 新表名
DDL:删除
-- 删除表
drop table [if exists] 表名;
# 在删除表时,表中数据也会被删除
数据操作语言 DML
添加数据 INSERT
- 插入数据时,指定字段顺序与值的顺序一一对应
- 字符串和日期型数据应包含在引号中
- 插入的数据大小,应在规定范围内
-- 指定字段添加
insert into 表名 (字段名1, 字段名2) values (值1, 值2);
-- 全部字段数据添加
insert into 表名 values (值1, 值2...);
-- 批量添加数据(指定字段)
insert into 表名 (字段1, 字段2) values (值1, 值2), (值1, 值2)...;
-- 批量添加数据(全部字段)
insert into 表名 values (值1, 值2...), (值1, 值2...)...;
修改数据 UPDATE
# 如果没有加入条件是修改全部数据
update 表名 set 字段1 = 值1, 字段2 = 值2,...[where 条件];
删除数据 DELETE
# 如果没有加入条件是删除全部数据
delete from 表名 [where 条件];
数据库操作 DQL
- DQL (数据查询语言),用来查询数据库表中的记录
- 关键字:select
基本查询
-- 查询多个字段
select 字段1, 字段2, ... from 表名;
-- 查询所有字段
select * from 表名;
-- 设置别名
select 字段1 [as 别名1], 字段2 [as 别名2], ... from 表名; # as 可以省略, 直接在后面写别名不用打引号
-- 去除重复记录
select distinct 字段列表 from 表名;
条件查询
-- 条件查询
select 字段列表 from 表名 where 条件列表
| 比较与算法 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等与 |
| = | 等于 |
| <> or != | 不等于 |
| between … and … | 在某个范围内(闭区间) |
| in(…) | 在 in 之后列表的值,多选一 |
| like 占位符 | 模糊匹配( _ 匹配单个字符, * 匹配任意个字符 ) |
| is null | 是 null |
| 逻辑运算符 | 功能 |
|---|---|
| and 或者 && | 并且 (两边都成立为真,否则为假) |
| or 或 || | 或者 (有一边成立为真,两边不成立为假) |
| not 或 | | 非, 不是 |
分组查询
-
聚合函数
-
将一列数据作为一个整体,进行纵向计算
- select 聚合函数(字段列表) from 表名
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| sum | 求和 |
| age | 平均值 |
- 分组查询
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]
where 与 having 的区别
- 执行时机不同:where 是分组之前进行过滤,不满足 where 条件的不参与分组;而 having 是分组后进行过滤
- 判断条件不同:where 不能对聚合函数进行判断,having 可以
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无意义
- 执行顺序: where > 聚合函数 > having
排序查询
select 字段列表 from 表名 [where 条件] [group by 分组字段] order by 字段1 排序方式, 字段2 排序方式 ...;
排序方式
asc : 升序 (默认)
desc: 降序
如果是多个字段,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
select 字段列表 from 表名 limit 起始索引, 查询记录数;
- 起始索引是从 0 开始的, 起始索引 = (查询页码 - 1) * 每页显示记录数
- 分页查询是数据库的方言,不同的数据库有不同的实现,Mysql 中是 LIMIT 关键字
- 如果查询的是第一页数据,起始索引可以省略,直接简化为 limit 10
多表设计
一对多(多对一)
- 需求:根据 页面原型 及 需求文档, 完成部门及员工模块的表结构设计
-- 创建员工表(子表)
create table tb_emp(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint not null comment '性别(1男/2女)',
image varchar(300) comment '图像',
job tinyint unsigned null comment '职位,1班主任/2讲师/3学工主管/4教研主管 ',
entrydate date null comment '入职日期',
dept_id int unsigned comment '归属部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 创建部门表(父表)
create table tb_dept(
id int unsigned primary key auto_increment comment 'ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-
外键约束
-
两表在数据层面,并未建立关联,所以无法保证数据的一致性和完整性
-
```mysql
– 创建表时指定
create table 表名(
字段名 数据类型,
…
[constraint] [外键名称] foreign key (外键字段名) references 主表(字段名)
);– 建完表后添加外键
alter table 表名 add constraint 外键名称 foreign key (外键字段名) references 主表(字段名);
```
添加外键约束后,如果有其他表与该表存在关联关系,那么在删除包含外键约束的表时会受到限制。默认情况下,删除包含外键约束的记录会导致删除失败,并且数据库会抛出一个错误。
然而,你可以通过使用不同的外键约束选项来改变这种行为。以下是一些常用的选项:
ON DELETE CASCADE: 当删除主表中的记录时,同时删除子表中相关联的记录。ON DELETE SET NULL: 当删除主表中的记录时,将子表中相关联的外键设置为NULL。ON DELETE SET DEFAULT: 当删除主表中的记录时,将子表中相关联的外键设置为默认值。ON DELETE NO ACTION或ON DELETE RESTRICT: 阻止删除主表中的记录,只有在没有相关联的子表记录时才允许删除。
你可以根据具体需求选择适合的外键约束选项来定义外键关系。这样,即使添加了外键约束,也可以进行删除操作,只是要根据你选择的选项来处理关联记录。****
- 物理外键
- 使用 foreign key 定义外键关联另外一张表
- 影响增删改的效率 (需要检查外键关系)
- 仅用于单节点数据库,不适应于分布式、集群场景
- 容易引发死锁问题,消耗性能
- 逻辑外键
- 在业务逻辑中,解决外键关联
- 通过逻辑外键,就可以很方便的解决上述问题
一对一
- 案例:用户 与 身份证信息 的关系
-
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,将其他字段放在另外一个表中,以提升操作效率
-
实现:在任意一方加入外键,关联另一方主键,并且设置外键为唯一的(UNIQUE)
多对多
- 案例:学生 与 课程 的关系
- 关系:一个学生可以选择多门课程,一门课程也可以供多个学生选择
- 实现:建立第三张表,中间表至少包含两个外键,分别关联两方主键
-- 学生表 tb_student
id主 name NO
1 Jack 2000111
2 Alice 2000112
3 Blank 2000113
-- 学生课程关系表 tb_student_course
id主 student_id外 course_id外
1 1 1
2 1 2
3 1 3
4 2 1
5 2 4
-- 课程表 tb_course
id主 name
1 JAVA
2 PHP
3 C++
4 MYSQL
案例
- 参考页面原型及需求,设计合理的表结构
- 需求:分类管理、菜品管理、套餐管理模块的表结构
- 步骤
- 阅读页面原型及需求文档,分析各个模块涉及到的表结构,及表结构之间的关系
- 根据页面原型及需求文档,分析各个表结构中具体字段及约束
给出表结构及表结构之间的关系
分类表 category
pk id
属性名称
属性名称
菜品表 dish
pk id
fk category_id
属性名称
套餐表 setmeal
pk id
fk category_id
属性名称
套餐菜品关系表 setmeal_dish
pk id
fk setmeal_id
fk dish_id
各个表结构中具体字段及约束
-- 分类表:分类名称 分类类型 排序 状态 操作时间
create table category
(
id int unsigned auto_increment comment '主键ID'
primary key,
name varchar(20) not null comment '分类名称',
type tinyint unsigned not null comment '类型:1.菜品分类,2.套餐分类',
sort tinyint unsigned not null comment '排序字段',
status tinyint unsigned default 0 not null comment '状态:0.停用,1.启用',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间',
constraint category_name_uindex
unique (name)
)
comment '分类表';
-- 菜品表:菜品名称 图片 菜品分类 售价 售卖状态 最后操作时间
create table dish
(
id int unsigned auto_increment comment '主键ID'
primary key,
name varchar(20) not null comment '菜品名称',
category_id int unsigned not null comment '菜品分类',
price decimal(8, 2) not null comment '价格',
image varchar(300) not null comment '图片',
description varchar(200) null comment '描述字段',
status tinyint unsigned default 0 not null comment '售卖状态:1.停售,2.起售',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间',
constraint dish_name_uindex
unique (name)
)
comment '菜品表';
-- 套餐表:套餐名称 套餐图片 套餐分类 套餐价格 售卖状态 最后操作时间
create table setmeal
(
id int unsigned auto_increment comment '主键ID'
primary key,
name varchar(20) not null comment '套餐名称',
category_id int unsigned not null comment '套餐分类',
price decimal(8, 2) not null comment '套餐价格',
image varchar(300) not null comment '图片',
description varchar(200) null comment '描述信息',
status tinyint unsigned default 0 not null comment '售卖状态:0.停售,1.起售',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间',
constraint setmeal_name_uindex
unique (name)
)
comment '套餐表';
-- 套餐菜品关系表:
create table setmeal_dish
(
id int unsigned auto_increment comment '主键ID'
primary key,
setmeal_id int unsigned not null comment '套餐分类',
dish_id int unsigned not null comment '菜品分类',
copies tinyint unsigned not null comment '菜品份数'
)
comment '套餐菜品关系表';
多表查询
- 多表查询:指定多张表中查询数据
mysql
select * from 表1, 表2;
- 笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合 和 B集合)所有组合的情况(在多表查询时,需要消除无效的笛卡尔积)
mysql
select * from 表1, 表2 where 表1.id = 表2.外键id
-
连接查询
-
内连接:相当于查询 A、B交集的部分数据
```mysql
– 隐式内连接
select 字段列表 from 表1, 表2 where 条件…;– 显示内连接
select 字段列表 from 表1[inner] join 表2 on 连接条件…;– 查询员工的姓名,及所属部门名称
select tb_emp.name, tb_dept from tb_emp, tb_dept where tb_dept.id = tb_emp.dept_id;
select tb_emp.name. tb_dept from tb_emp inner join tb_dept on tb_dept.id = tb_emp.dept_id;– 如果表名太长可以起别名,一旦启用别名就不能使用原本的名字
select e.name, d.name from tb_emp e, tb_dept d where d.id = e.dept_id;
``` -
外连接:
- 左连接:查询左表所有数据(包括两张表的交集部分数据)
mysql select 字段列表 from 表1 left [outer] join 表2 on 连接条件 ...;- 右连接:查询右表所有数据(包括两张表的交集部分数据)
mysql select 字段列表 from 表1 rigth [outer] join 表2 on 连接条件 ...; -
子查询
-
介绍:SQL 语句中嵌套 select 语句,称为嵌套查询,也称子查询
-
形式:
select * from t1 were column1 = (select column1 from t2 ...); -
子查询外部的语句可以是 insert / update / delete / select 的任意一个
-
标量子查询:子查询返回的值为单个值
```mysql
常用操作符:>, >=, <, <=, =, <>
– A. 查询“教研部”的所有员工信息
– a. 查询 教研部 的部门ID - tb_dept
select id from tb_dept where name = ‘教研部’;
– b. 再查询该部门 ID 下的员工信息 - tb_emp
select * from tb_emp where dept_id = (上述查询的结果)
– c. 将 a,b两个步骤合并
select * from tb_emp where dept_id = (select id from tb_dept where name = ‘教研部’);– B. 查询在“方东白”入职之后的员工信息
– a. 查询 方东白 的入职时间
select entrydate from tb_emp where name = ‘方东白’;
– b.查询在“方东白”入职之后的员工
select * from tb_emp where entrydate > (上述查询的结果);
– c. 将 a,b两个步骤合并
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = ‘方东白’);
``` -
列子查询:子查询返回结果为一列
```mysql
常用操作符:in,not in
– A. 查询“教研部”和“咨询部”的所有信息
– a. 查询“教研部”和“咨询部”的部门ID - tb_dept
select id from tb_dept where name = ‘教研部’ or name = ‘咨询部’;
– b. 根据部门ID,查询该部门下的员工信息 - tb_emp
select * from tb_emp where dept_id in (上述查询的结果);
– c. 将 a,b两个步骤合并
select * from tb_emp where dept_id in (select id from tb_dept where name = ‘教研部’ or name = ‘咨询部’);```
-
行子查询:子查询返回结果为一行
```mysql
常用操作符:=, <>, in, not in
– 查询与”张三“的入职时间及职位都相当的员工信息
– a. 查询”张三“的入职时间和职位
select entrydate, job from tb_emp where name = ‘张三’;
– b. 查询与入职时间和职位都匹配的员工信息
select * from tb_emp where entrydate = (上述entrydate结果) and job = (上述job结果);
select * from tb_emp where (entrydate, job) = (上述查询结果);
– c. 将 a,b两个步骤合并
select * from tb_emp where (entrydate, job) = (select entrydate, job from tb_emp where name = ‘张三’);
``` -
表子查询:子查询返回结果为多行多列
```mysql
常用操作符:in
– 查询入职时间是”2023-07-30“之后的员工信息及部门名称
– a. 查询入职时间为”2023-07-30“之后的员工信息
select * from tb_emp where entrydate > ‘2023-07-30’;
– b. 查询部分员工及其部门名称
select e.*, d.name from (select * from tb_emp where entrydate > ‘2023-07-30’) e, tb_dept d where e.dept_id = d.id;
```
事务
- 概念:事务是一组操作的集合,他是一个不可分割的工作单位。事务会把所有操作作为一个整体一起向系统提交或者撤销操作请求,即这些操作 要么同时成功,要么同时失败
-
默认Mysql的事务是自动提交的,也就是说,当执行一条DML语句,Mysql会隐式的提交事务
-
学工部 整个部门解散了,该部门部下的员工都需要删除(要两步操作,如果有一步出现问题,那么会造成数据不一致)
-- 开启事务
start transaction; # begin;
-- 删除部门
delete from tb_dept where id = 1;
-- 删除部门下的员工
delete from tb_emp where dept_id = 1;
-- 提交事务
commit;
-- 回滚事务
rollback;
- 四大特性
MySQL事务具有以下四个特性,通常被称为ACID特性:
原子性(Atomicity):事务中的操作被视为一个不可分割的原子单元,要么全部执行成功,要么全部回滚到事务开始前的状态。如果事务的任何一部分失败,整个事务将被回滚,以确保数据库的一致性。
一致性(Consistency):事务在开始和结束时,数据库必须保持一致的状态。这意味着事务开始前和结束后,数据库必须满足所有定义的完整性约束。
隔离性(Isolation):事务的隔离性确保并发执行的事务之间相互隔离,并且每个事务都认为其他并发事务对它是透明的。这样可以防止并发事务之间的数据干扰和相互影响。
持久性(Durability):事务一旦提交,其结果应该永久保存在数据库中,即使系统发生故障也不会丢失。数据库系统使用写日志和数据持久化等机制来确保事务的持久性。
这些特性保证了在并发环境下,多个事务可以同时进行而不会导致数据不一致或损坏。通过使用事务,可以确保数据库的完整性和可靠性。
索引
-
索引(index)是帮助数据库 高效获取数据的数据结构
-
优点
-
提高数据查询效率,降低数据库的 IO 成本
-
通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗
-
缺点
-
索引会占用储存空间
-
索引大大提高查询效率,同时也降低了 insert、update、delete的效率
-
结构 B+Tree(多路平衡树)
-
每一个节点,可以存储多个key(有n个key就有n个指针)
- 所有数据存储在叶子节点,非叶子节点仅用于索引数据
-
叶子节点成为一颗双向链表,便于数据的排序及区间范围查询
-
语法
-
创建索引
create [unique] index 索引名 on 表名(字段名, ...); -
查看索引
show index from 表名; -
删除索引
drop index 索引名 on 表名; -
主键字段,在建表时,会自动创建主索引
>添加唯一约束时,数据库实际上会添加唯一索引
