
简单来说,就是在映射中定义的一些配置。
analyzer
定义对文本字段的分词器:默认对索引和查询都是有效的。
分词器之前有说过 ik分词器介绍
作用就是分词器将输入的文本转为一个一个的词条流。用于构建倒排索引进行查询。
eg:
1. 创建一个索引,但是不指定 analyzer

2. 存入一条文档
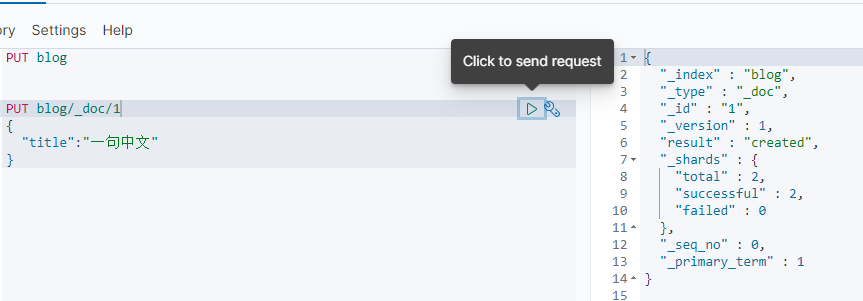
3. 通过 _termvectors 查看分词后的结果
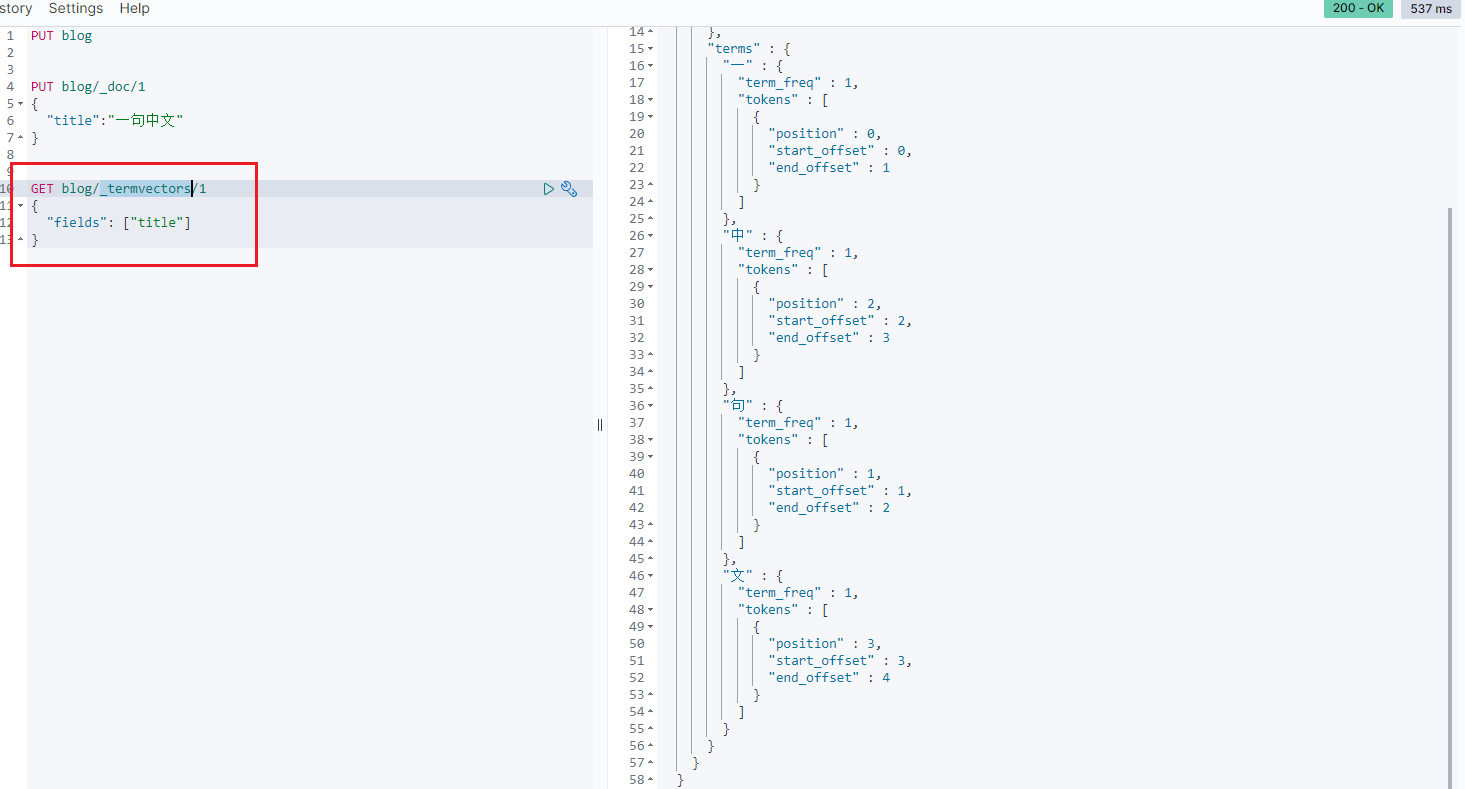
由于这里没有配置 analyzer,那么对于中文会采用默认的分词方式,也就是一个字一个字的拆分。那么对应的,查询也只能一个字一个字的查
4. 查询
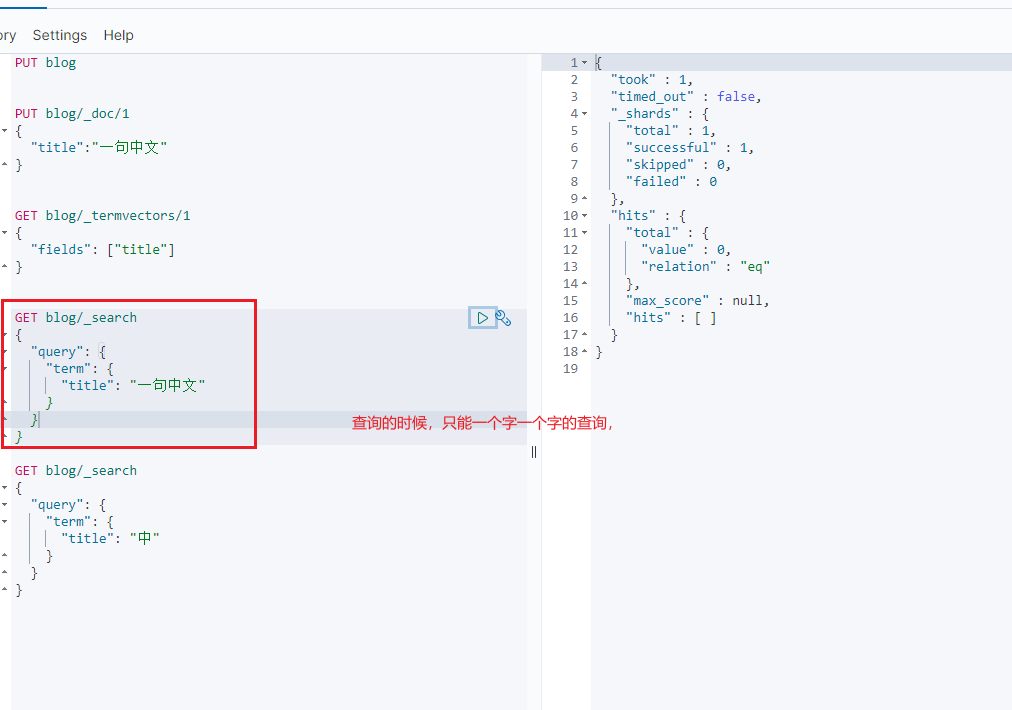
用一个字来查
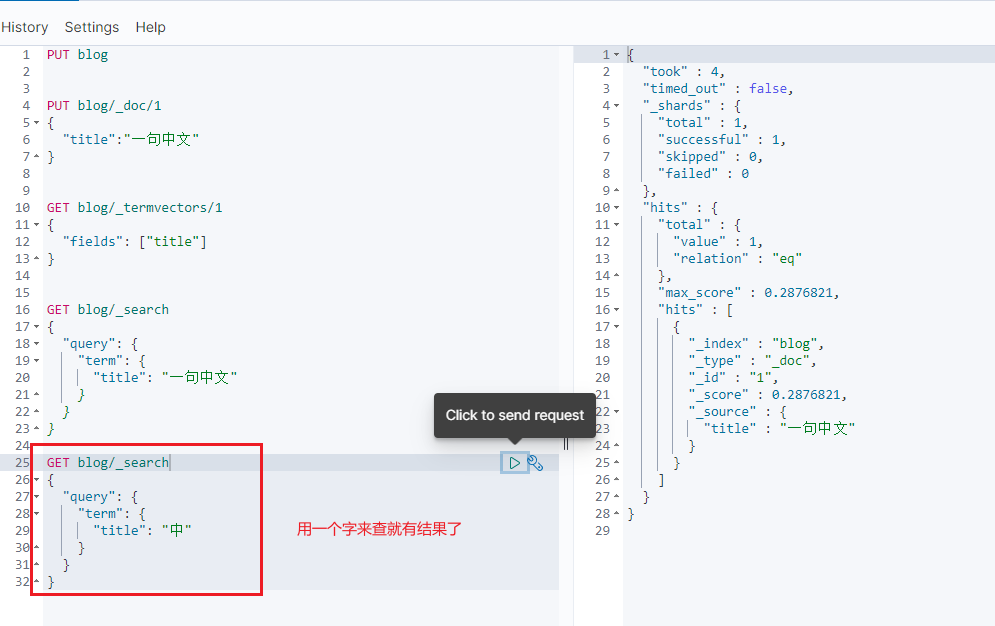
这种情况下,查询只能一个字一个字来查,不符合实际情况
所以还是需要设定分词器。
eg:
1. 删除原索引,再建一个新的索引,也叫 blog,在创建索引的时候指定分词器为 ik
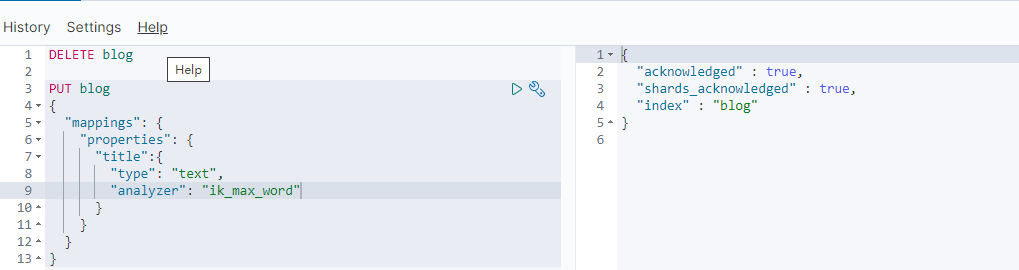
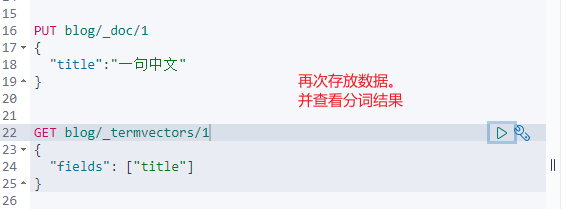
2. 再次加入同样的文档,查看分词结果

3. 尝试再次进行查询,查看结果
此时再去查询的时候,还是根据词项来查询,只不过分词器的存在,让词项更符合实际。
search_analyzer
这个是查询时候的分词器
因为我们查询的时候,也可能是输入一句话去查询,那么这句话也需要分词。
normalizer
这个参数的作用是用于 索引或者查询的标准化配置(这里的索引是指索引一个文档,也就是存储一个文档)
eg:
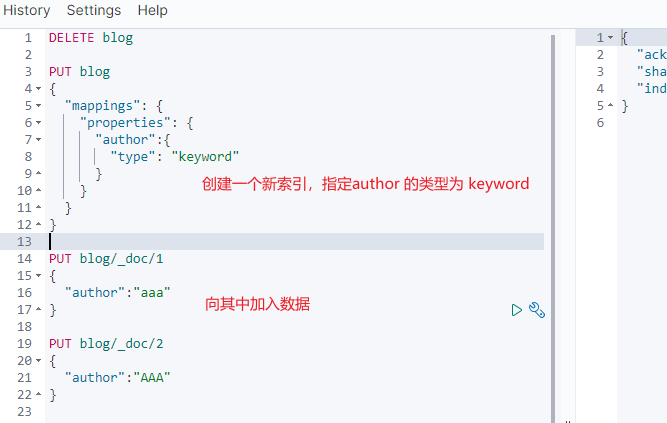
在 es 中,对于一些我们不想切分的字符串,会将其类型设置为 keyword,搜索时候也是使用整个词进行搜索。
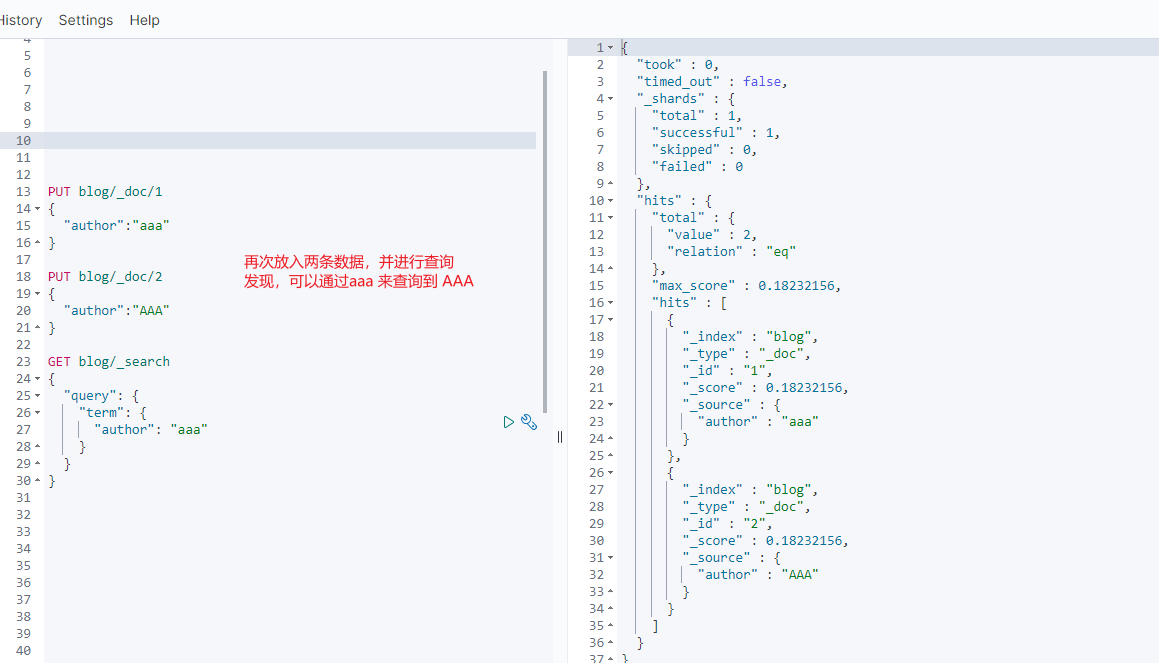
如果在索引前没有做好数据清洗,导致大小写不一致,例如 aaa 和 AAA,
那么查询的时候就只是各自查各自的结果
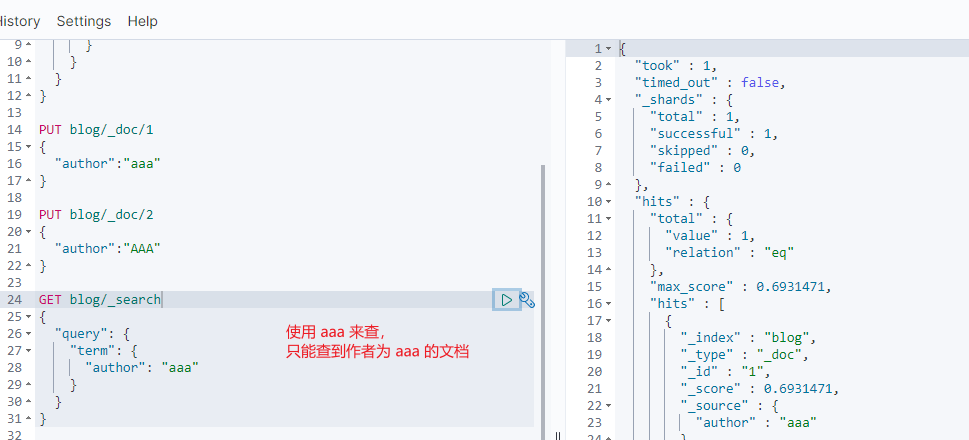
此时,我们就可以使用 normalizer 在索引之前以及查询之前进行文档的标准化。
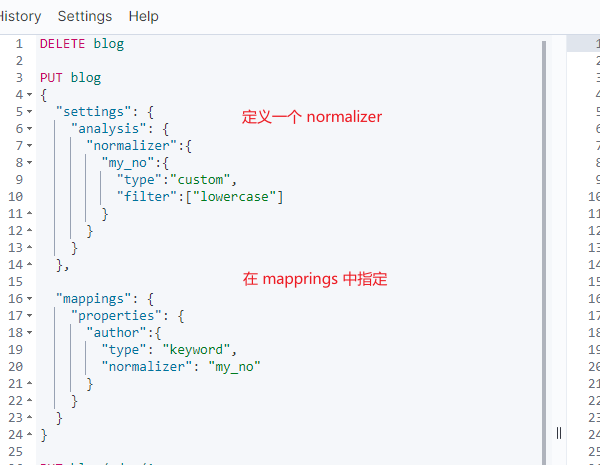
在 settings 中定义 normalizer,然后在 mappings 中引用。
此时查询的时候,大写关键字也可以查询到小写文档,因为无论是索引还是查询,都会将大写转为小写。
boost
这个参数可以设置字段的权重
在实际使用时,建议在查询中使用。而不是在mappings 中定义
因为如果在 mappings 中定义,如果不重新索引文档,权重无法修改。
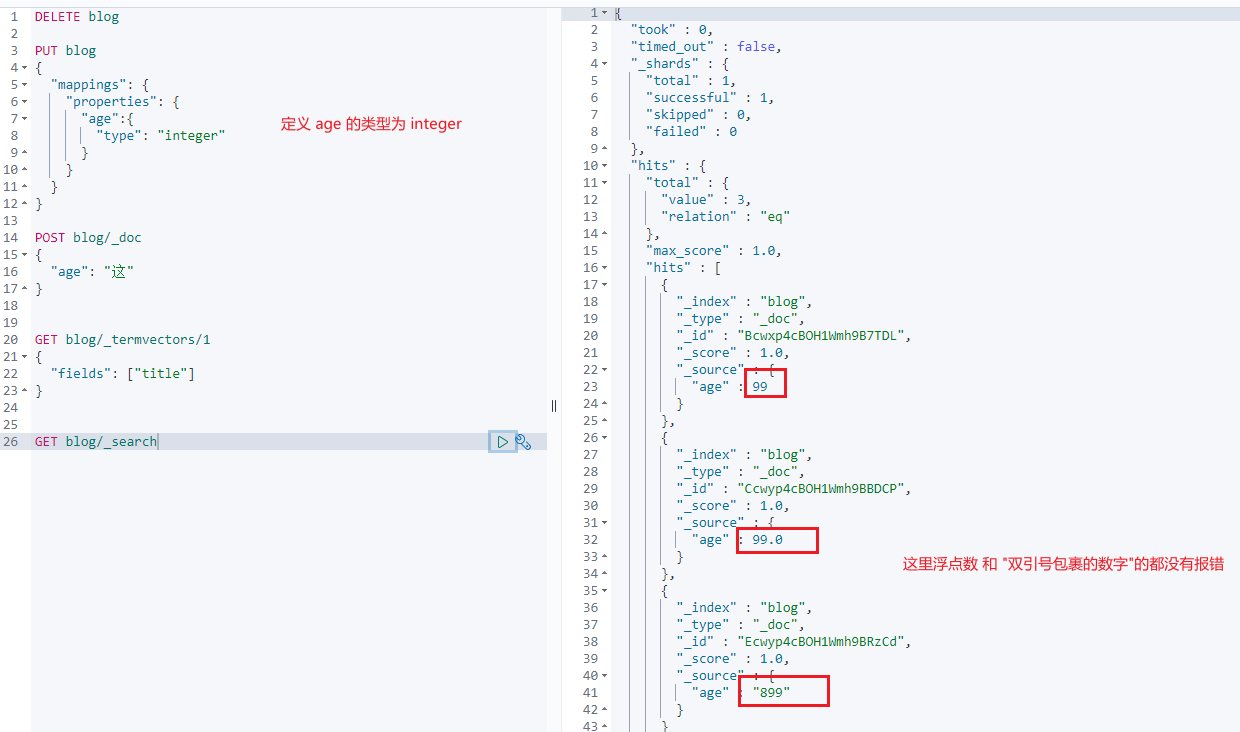
coerce
这个参数的作用是来清除脏数据,默认是 true
默认情况下,以下操作没问题,就是 coerce 参数在起作用
copy_to
这个属性的作用是将多个字段的值复制到同一个字段中

