
Trie树:
作用:高效存储和查找字符串集合的数据结构
样子:字典
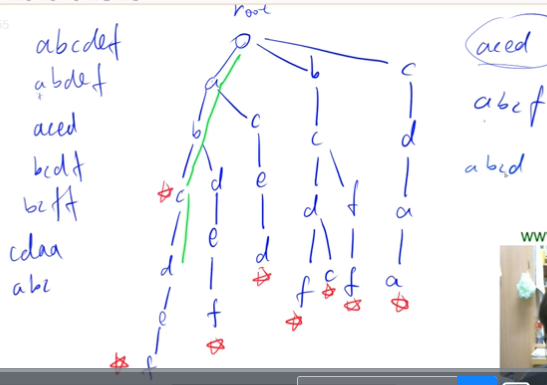
note: 每次在添加一个字符串时在树上打上当前字符串结尾标记
关于理解int son[N][26] 这个二维数组的心得
评论区json Lin大佬的解释:
Tire树本质上一个多叉树,最多可以分多少叉呢?因为此题存的都是小写字母,所以是26叉;
这里就解释了son这个二维数组的第二维的含义,就是他最多有26个孩子,那么他是谁呢,他当然是结点了,那结点之间怎么区分,或者这些孩子的爸爸叫啥,爸爸们用下标来区别,所以第一维就是爸爸们的id,son[0][1]含义就是0号爸爸有个儿子b ,那son[0][1] = 2,就是0号爸爸有个儿子b,儿子的id是2; 这些id就是由idx` 来赋值的;
idx可以理解为计划生育的管理局的给上户口的,生一个孩子,给孩子上身份证,证件上ID 为++idx ,而孩子叫啥,其实就是26个小写字母中的其中一个了;
对于每个结点而言,可以知道他有没有这个孩子,有的话叫啥,在哪里;
对于查询,从根节点一路查下来,就可以找到某个字符串在不在;
对于插入字符串,也是一路下来,看有没有这个儿子,没有了给你生个儿子,有了继续给下面找,所以只插入该字符串中原来不存在的字符即可; 也就是利用了公共前缀来降低查询时间的开销以达到提高效率的目的;
“Trie这个名字取自“retrieval”,检索,因为Trie可以只用一个前缀便可以在一部字典中找到想要的单词。”
作者:jsonlin: https://www.acwing.com/user/myspace/index/13039/
链接:https://www.acwing.com/file_system/file/content/whole/index/content/4796/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
并查集:
(不加优化的话,在找根节点的过程中会很慢)
变形题通常需要在并查过程维护其他变量

堆:
是一个完全二叉树:上面是满的,最后一层从左到右依次排布
求解:
1. 插入一个数
在堆最下面插入,然后一直上移
heap[++size] = x, up(size)
2. 求最小的数
heap[1]
3. 删除最小的数
用最后一个元素覆盖堆顶(交换),再删除最后一个元素(size--),最后再down(堆顶)
heap[1] = heap[size], size--, down(1)
4. 删除任意一个元素(手写only)
类似3;不同是向上或向下需要分情况(不分也行,直接两个全写,执行时只会执行其中一个)
heap[k] = heap[size], size--, down(k), up(k)
5. 修改任意一个元素(手写only)
heap[k] = x, down(k), up(k)
分类:大根堆, 小根堆
小根堆: 每个点小于或等于左右两个儿子 -> 根节点最小
存储:
1号点为根节点;节点x,它的左仔节点是2x,右仔节点是2x + 1;(因此heap下标从1开始方便)
小根堆小的在上,因此当有数变大就让它沉下去(down(x)),反之up(x)
如何快速建堆:
从n/2开始(最后一层非叶子节点)一直down
如何用数组模拟堆(手写堆实现):
难点:如何操作第k个插入的数(修改/删除):
应用:digistra堆优化
基本操作同4., 5.
*不同:如何求第k个插入的数在堆中是哪个?(要操作的目标数如何求解)
方法:
用两个数组分别保存(ph[k] (pointer to heap), hp[j])第k个插入的数是什么和在堆中的一个数是第几个插入的(交换操作需要用,得保证双向映射成立)
建立双向映射(类似互为反函数)
