<<< \color{blue}{ (●’◡’●) 点赞 <(- ●’◡’●) }
/\\ //>>>>
/__\\ // 关注加RP,AC更容易!
/ \\ //>>>>>
<<< \color{blue}{ (●’◡’●) 收藏 <(- ●’◡’●) }
前文介绍过Torch->onnx->TensorRT的一系列困难,现在再来统一回顾下:
部署的常见困难
-
模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
-
新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
-
中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
问题解决一般流程
使用torch.onnx.export实现pytorch转onnx有以下几个限制:
- 输入必须为Tensor张量
- Tensorrt函数转onnx有固定的映射关系
所以,模型转换时,首先要确保输入为Tensor张量;
如果转换时有TraceWarning提示,那说明参数导出可能失效。
使用Netron可以查看onnx模型图。根据模型和参数,可以比对哪个算子出了问题。
如果算子不对,则需要实现自定义的算子。
插值算子导出
以pytorch的interpolate为例。
pytorch如下:
x = interpolate(x,
scale_factor=upscale_factor.item(),
mode='bicubic',
align_corners=False)
我们希望它能支持动态的插值操作。
但onnx导出的模型中,interpolate只是
在 PyTorch 中,和 ONNX 有关的定义全部放在 torch.onnx目录中;
➜ onnx ls -b
__init__.py __pycache__ symbolic_helper.py symbolic_opset11.py symbolic_opset13.py symbolic_opset15.py symbolic_opset8.py symbolic_registry.py
operators.py symbolic_caffe2.py symbolic_opset10.py symbolic_opset12.py symbolic_opset14.py symbolic_opset7.py symbolic_opset9.py utils.py
在opset11中,可以找到bicubic的定义:
def _interpolate(name, dim, interpolate_mode):
return sym_help._interpolate_helper(name, dim, interpolate_mode)
upsample_nearest1d = _interpolate("upsample_nearest1d", 3, "nearest")
upsample_nearest2d = _interpolate("upsample_nearest2d", 4, "nearest")
upsample_nearest3d = _interpolate("upsample_nearest3d", 5, "nearest")
upsample_linear1d = _interpolate("upsample_linear1d", 3, "linear")
upsample_bilinear2d = _interpolate("upsample_bilinear2d", 4, "linear")
upsample_trilinear3d = _interpolate("upsample_trilinear3d", 5, "linear")
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
可以看到,upsample里的插值操作转换到onnx, 都是固定常数的。
因此解决方案只有一个:自定义ONNX算子。
自定义bicubic算子
通过重载函数的symblolic方法,能够将自己的函数注册到对应的onnx算子实现。
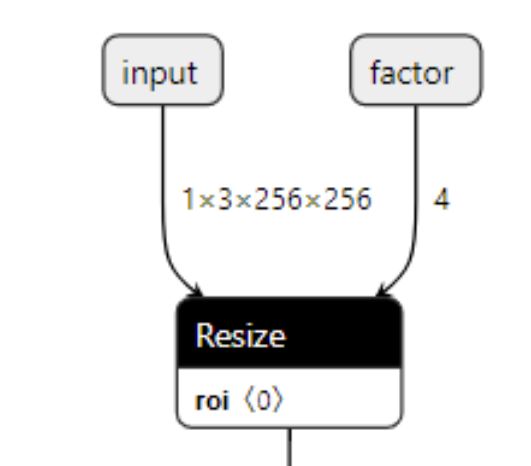
先来看onnx的Resize函数接口:
Inputs
Between 3 and 4 inputs.
- X (heterogeneous) - T1: N-D tensor
- roi (heterogeneous) - T2: 1-D tensor given as [start1, …, startN, end1, …, endN], where N is the rank of X. The RoIs’ coordinates are normalized in the coordinate system of the input image. It only takes effect when coordinate_transformation_mode is “tf_crop_and_resize”
- scales (heterogeneous) - tensor(float): The scale array along each dimension. It takes value greater than 0. If it’s less than 1, it’s sampling down, otherwise, it’s upsampling. The number of elements of ‘scales’ should be the same as the rank of input ‘X’. If ‘size’ is needed, the user must set ‘scales’ to an empty tensor.
- sizes (optional, heterogeneous) - tensor(int64): The size of the output tensor. The number of elements of ‘sizes’ should be the same as the rank of input ‘X’. May only be set if ‘scales’ is set to an empty tensor.
函数包含3~4个输入
- X,待resize的tensor;
- roi,tensor待缩放的区域;
- scales 缩放比例
- sizes 可选项;如果scales没有设定,直接用sizes设定输出比例
因此我们实现的函数也需要有四个输入;其他属性可以按需要设置
代码实现如下:
class CustomedInterpolate(torch.autograd.Function):
@staticmethod
def symbolic(g, input, scales):
return g.op("Resize",
input,
g.op("Constant",
value_t=torch.tensor([], dtype=torch.float32)),
scales,
coordinate_transformation_mode_s="pytorch_half_pixel",
cubic_coeff_a_f=-0.75,
mode_s='cubic',
nearest_mode_s="floor")
@staticmethod
def forward(ctx, input, scales):
scales = scales.tolist()[-2:]
return interpolate(input,
scale_factor=scales,
mode='bicubic',
align_corners=False)
验证
定义完成后,可以使用torch.onnx.export导出模型。
可以使用netron对onnx模型进行可视化。
当可视化里的resize节点显示两个输入,说明导出成功。