
以下内容总结自:
徐隆曦 - Java 并发编程 78 讲 - [5]并发容器
HashMap为什么不是线程安全的?
首先,扩容期间取出的值可能是不准确的。
举个例子:
public class HashMapNotSafe {
public static void main(String[] args) {
final Map<Integer, String> map = new HashMap<>();
final Integer targetKey = (1 << 16) - 1;
final String targetValue = "Whatever";
map.put(targetKey, targetValue);
new Thread(() -> {
IntStream.range(0, targetKey).forEach(k -> map.put(k, "value"));
}).start();
while (true){
if (null == map.get(targetKey)){
throw new RuntimeException("HashMap is not thread safe.");
}
}
}
}
按照我们的期望,每次执行map.get(targetKey)都应该返回Whatever。
但是,在发生扩容时,可能会返回null。

第二个原因:
扩容时也可能形成环形链表,导致后续get()发生死循环,造成CPU 100%。
ConcurrentHashMap在Java7和8有何不同?
可以从五个角度进行分析:
数据结构
Java7:采用Segment分段锁来实现。
Java8:使用数组 + 链表 + 红黑树。
并发度
Java7:每个Segment独立加锁,最大并发个数就是Segment的梳理[默认为16]
Java8:锁粒度更细,因此并发度比Java7有所提高。
保证并发安全的原理
Java7:采用Segment分段锁保证线程安全,它继承了ReentrantLock。
Java8:采用Node + CAS + synchronized保证线程安全。
遇到Hash碰撞
Java7:使用链表。
Java8:先使用链表,当链表长度超过一定阈值后[默认为8],则将其转换为红黑树。
查询时间复杂度
Java7:遍历链表的时间复杂度是O(n),n为链表长度。
Java8:如果变成遍历红黑树,时间复杂度降低为O(log(n)),n为树的结点个数。
再来介绍下红黑树的特点:
首先,它是一棵二叉搜索树,也就是BST。
然后,它具有自平衡的特点。
其次,它的结点是有颜色的,要么红,要么黑,根结点肯定是黑色的。
第四,任何两个相邻的结点,不可能同时是红色的。
第五,从任一结点到叶子结点的所有路径中,黑色结点的数量一定是相等的。
为什么Map桶中超过8个元素才会转为红黑树?
首先,必须要明确一点:
如果HashCode分布良好,那么红黑树这种数据结构是很少很少被用到的。
因为链表长度符合泊松分布,命中概率随着链表长度的增加而依次递减,
当长度为8时,概率仅为千万分之一。
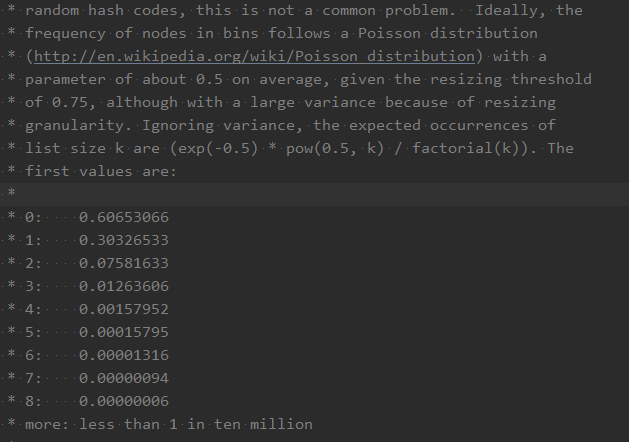
所以,红黑树设计的目的是防止用户自己实现了不好的哈希算法而导致链表过长,影响查询效率。
ConcurrentHashMap和Hashtable的区别是什么?
从下面四个角度进行分析:
出现的版本不同
Hashtable: 在JDK1.0中出现。
ConcurrentHashMap: 在JDK1.5中才出现。
实现线程安全方式的不同
Hashtable: 使用synchronized关键字
ConcurrentHashMap: 使用Node + CAS + synchronized
性能不同
Hashtable: 随着线程数量的增加,性能会急剧下降。
因此每次修改都需要锁住整个对象,并且其他线程在此期间不能进行任何操作。
ConcurrentHashMap: 仅会对一部分上锁,锁的粒度更细。
迭代时修改策略不同
Hashtable: 在迭代期间,不允许对内容进行修改,
否则就会抛出ConcurrentModificationException,其原理是检测modCount变量。
ConcurrentHashMap: 在迭代期间,允许对内容进行修改。
CopyOnWriteArrayList的特点有哪些?
首先,你肯定有这样的疑惑:
它与ReentrantReadWriteLock读写锁的区别是什么?
CopyOnWriteArrayList在读取时是不用加锁的,只有在写入时才需要上锁,
并且它可以在写入的同时进行读取,这是读写锁做不到的。
那么CopyOnWriteArrayList有什么特点?
第一点: 写时复制。
分为以下三步:
- 先将当前数组进行
Copy,复制一个新的数组。 - 然后根据需求,修改新的数组。
- 当完成修改之后,再将原数组的引用指向新的数组。
第二点: 迭代期间允许修改数组内容
CopyOnWriteArrayList的迭代器一旦被建立后,
如果继续往容器中添加元素,那么在该迭代器中既不会显示新的元素,也不会报错。
举个例子:
public class CopyOnWriteArrayListDemo {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[]{1, 2, 3});
System.out.println(list); // [1, 2, 3]
Iterator<Integer> itr1 = list.iterator();
list.add(4);
System.out.println(list); // [1, 2, 3, 4]
Iterator<Integer> itr2 = list.iterator();
System.out.println("Verify Iterator1 content");
itr1.forEachRemaining(System.out::println);
System.out.println("Verify Iterator2 content");
itr2.forEachRemaining(System.out::println);
// Verify Iterator1 content
// 1
// 2
// 3
// Verify Iterator2 content
// 1
// 2
// 3
// 4
}
}
最后,再来介绍一下CopyOnWriteArrayList的缺点:
- 首先,肯定是内存占用问题。
- 然后,还要考虑
复制数组时的开销问题。 - 最后,还会发生
数据一致性问题。

ConcurrentHashMap 是安全的吗?
是的
其实不然,ConcurrentHashMap 只能保证提供的原子性读写操作是线程安全的。其他的不一定可以。
能举个几个例子么?
多谢,找了例子
java8 更新了一些比较好的API,可以比较好的解决这些问题,但是看网上关于这个比较少,我觉得可以写一篇文章说说。加油