
算法基础课第三讲笔记
DFS(普通DFS 和 图的DFS)
DFS难点:(一般都是判断是否结束 + 递归)
- 搜索节点格局和状态的保存
- 如何用状态来判断是否递归(用状态剪枝)
- 递归完成之后的现场的恢复
- 往下递归一次就多一个搜索节点
- 普通DFS:返回格局作为结果在开头,状态和格局的改变一般在搜索子节点中
- 图的DFS:状态的改变在开头,返回正确的结果在搜索子节点之后
// 数字全排列的 DFS 搜索过程详细解析
//path 存储的是每个节点所对应的格局
//st 存储的是每个格局所对应的状态
int path[N];//保存序列
int state[N];//数字是否被用过
void dfs(int u)
{
//搜索完成数据当前格局作为答案
if(u > n)
{
for(int i = 1; i <= n; i++)
cout << path[i] << " ";
cout << endl;
}
//搜索还未完成,需要继续往下递归
for(int i = 1; i <= n; i++)
{
//利用当前节点的状态来进行剪枝
if(!state[i])
{
path[u] = i;
state[i] = 1;
// 搜索树往下递归
dfs(u + 1);
// 递归结束后的恢复现场,按理来说格局也需要恢复,但是这里格局是直接被覆盖掉的所以不用
state[i] = 0;
}
}
}
// n-皇后问题的详细解析
// col列,dg对角线,udg反对角线(节点的状态)
// g[N][N]用来存路径 (节点的格局)
char g[N][N];
bool col[N], dg[N], udg[N];
void dfs(int u) {
// u == n 表示已经搜了n行,输出当前节点的格局
if (u == n) {
for (int i = 0; i < n; i ++ ) puts(g[i]);
puts("");
return;
}
// 枚举u这一行,搜索合法的列
int x = u;
for (int y = 0; y < n; y ++ )
// 剪枝(利用当前节点的状态进行剪枝)
if (col[y] == false && dg[y - x + n] == false && udg[y + x] == false) {
//改变节点状态之后往下递归
col[y] = dg[y - x + n] = udg[y + x] = true;
g[x][y] = 'Q';
dfs(x + 1);
//恢复现场,这个时候格局和状态都需要进行恢复
g[x][y] = '.';
col[y] = dg[y - x + n] = udg[y + x] = false;
}
}
BFS
BFS 难点:(一般都是队列初始化 + 不停的入队出队)
- 求权值为 1 的最短路的问题
- 节点的格局和状态怎么存储
- 搜索结束条件的判定(队中弹出格局是否为结束格局)
- 一般节点的格局是入队的元素
- 一般状态避免重复入队,同时保存答案
//走迷宫问题详解
// PII 中存储的节点的格局,当前格局在那个坐标
typedef pair<int, int> PII;
//d[][] 中存储的是节点的格局对应状态,保存的是从起始节点格局到该格局的距离
int g[N][N], d[N][N];
int bfs()
{
//初始节点的格局入队
q.push({0, 0});
//初始化节点的状态
memset(d, -1, sizeof(d));
d[0][0] = 0;
//搜索方向
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
//当队列中还有格局
while (q.size())
{
PII t = q.front();//取队头元素
q.pop();//出队
for (int i = 0; i < 4; i++)
{
int x = t.first + dx[i], y = t.second + dy[i];
//用状态来避免重复入队
if (x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1)
{
d[x][y] = d[t.first][t.second] + 1;//当前点到起点的距离
q.push({x, y});//将新坐标入队
}
}
}
//返回节点的状态作为答案
return d[n - 1][m -1];
}
//八数码问题详解(这题有一个很妙的转换是将一个二维矩阵转换为字符串来存储)
//st 队列中存储的是节点的格局
queue<string> st;
//dis 中存储的是每个格局所对应的状态值
unordered_map<string,int> dis;
int bfs(string start){
string end = "12345678x";
//初始化队列
st.push(start);
dis[start] = 0;
int dx[4] = {1, 0, -1, 0}, dy[4] = {0, 1, 0, -1};
//当队列不空的时候不停的入队和出队
while(st.size())
{
//拿到队列中的队列头元素
string t = st.front();
int td = dis[t];
st.pop();
//查看格局是否是结束格局
if(t == end) return td;
//拿到队列中对应头元素的下标
int index = t.find('x');
int x = index / 3;
int y = index % 3;
//开始入队
for(int i = 0; i <= 3; i++)
{
int a = x + dx[i];
int b = y + dy[i];
if(a >= 0 && a < 3 && b >= 0 && b <3)
{
swap(t[index], t[3 * a + b]);
//用格局对应的状态来避免相同格局重复入队
if(!dis[t])
{
st.push(t);
dis[t] = td + 1;
}
swap(t[index], t[3 * a + b]);
}
}
}
return -1;
}
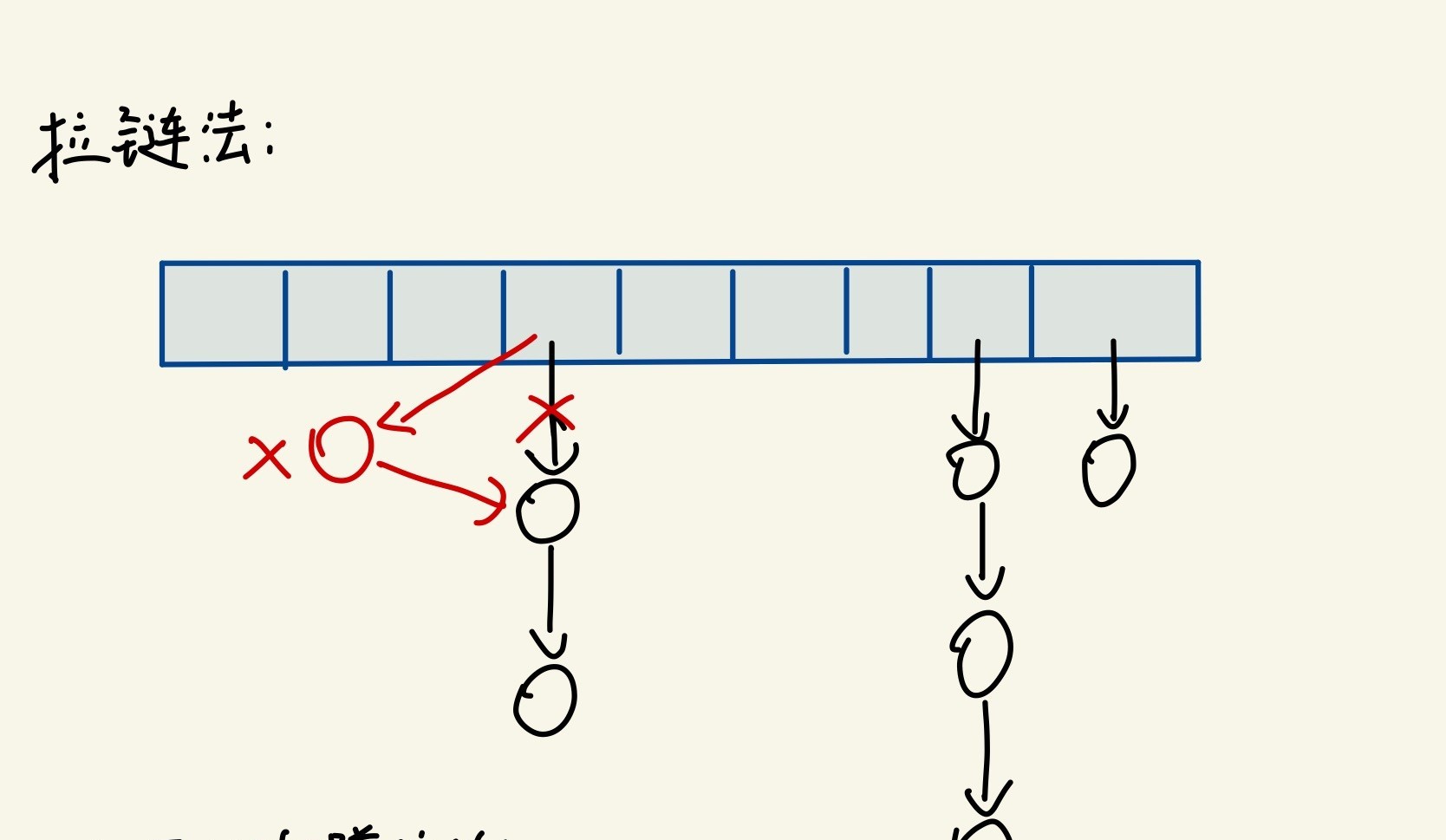
树图存储
- 树和图的存储和哈希法的拉链法存储解决冲突是一样的
- 主要掌握如何插入两条边
//因为节点之间可能会有两条边,所以我们在这里开大小的时候开的是两倍节点大小
int h[N],e[2 * N], ne[2 * N];
int idx;
//树图的初始化
memset(h, -1, sizeof h);
//如何在节点 a, b 之间插入一条边
void insert(int a, int b)
{
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
树图的 DFS 和 BFS 遍历
- 节点的格局就是存储的树图节点本身(几号节点)
- 最短路用 BFS,递归用 DFS
- 每个节点对应的状态怎么存(一般是存有没有被遍历过)
- 树的 DFS 暴力搜索一般不用恢复现场,只需要标记该点被访问过了即可
//树的重心详解,这道题目是在递归的过程中更新答案的(DFS 暴力搜索)
const int N = 100010;
int h[N], e[2 * N], ne[2 * N];
//每个节点有没有被访问过
bool st[N];
int idx, m, ans = M;
void insert(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
//用 dfs 递归的求以该节点为根节点的树中的节点树
int dfs(int u)
{
//将该节点标记为已访问
st[u] = true;
int sum = 1;
int res = 0;
//递归的去搜索与其相邻节点
for(int head = h[u]; head != -1 ;head = ne[head])
{
int point = e[head];
if(!st[point])
{
int s = dfs(point);
sum += s;
res = max(res, s);
}
}
res = max(res, m - sum);
ans = min(ans, res);
return sum;
}
int main(){
memset(h, -1, sizeof h);
int a, b;
cin>>m;
for(int i = 0; i < m - 1; i++)
{
cin>>a>>b;
insert(a, b);
insert(b, a);
}
dfs(2);
cout<<ans<<endl;
}
//图中点的层次详解
const int N = 100010;
int n, m;
int h[N], e[2 * N], ne[2 * N], idx;
//队列中存储的是节点的格局(几号节点)
queue<int> q;
//dis 存储的是节点的状态(从起点到当前格局的距离,同时判定有没有被访问过)
unordered_map<int,int> dis;
void insert(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int bfs(){
//初始化格局队列
q.push(1);
dis[1] = 0;
while(q.size())
{
int point = q.front();
int d = dis[point];
q.pop();
//查看格局是否是结束格局
if(point == n)
{
return d;
}
//格局队列的入队
for(int i = h[point]; i != -1; i = ne[i])
{
int j = e[i];
//状态保存该格局是否已经入过队了,避免重复入队
if(!dis[j])
{
q.push(j);
dis[j] = d + 1;
}
}
}
return -1;
}
int main()
{
memset(h, -1, sizeof h);
cin>>n>>m;
for(int i = 0; i < m; i++)
{
int a, b;
cin>>a>>b;
insert(a, b);
}
cout<<bfs()<<endl;
}
//拓扑排序详解
const int N = 100010;
int h[N], e[2 * N], ne[2 * N];
//保存当前格局的对应状态
int d[N];
int idx, n, m;
//保存格局的队列
queue<int> q;
queue<int> res;
void insert(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
bool isExist(int a, int b)
{
for(int i = h[a]; i != -1; i = ne[i])
{
if(e[i] == b) return true;
}
return false;
}
void bfs()
{
for(int i = 1; i <= n; i++)
{
if(d[i] == 0) q.push(i);
}
while(q.size())
{
int t = q.front();
q.pop();
//cout<<t<<endl;
res.push(t);
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
d[j]--;
//根据格局的状态来判定是否进行入队操作
if(!d[j]) q.push(j);
}
}
if(res.size() == n)
{
for(int i = 0; i < n; i++)
{
cout<<res.front()<<' ';
res.pop();
}
}else{
cout<<"-1"<<endl;
}
}
int main()
{
memset(h, -1, sizeof h);
cin>>n>>m;
for(int i = 0; i < m; i++)
{
int a, b;
cin>>a>>b;
if(!isExist(a, b))
{
insert(a, b);
d[b]++;
}
}
bfs();
}
最短路问题
这种题目不用特别知道原理,主要考察建图功底,建好图之后直接模板套就行
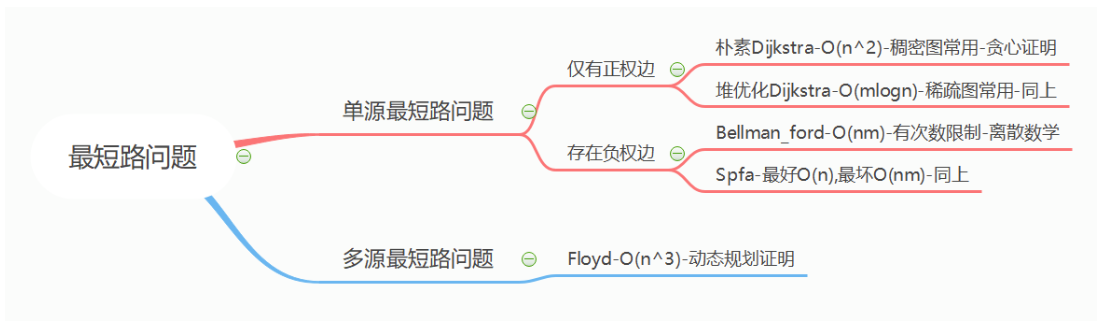
Dijkstra-朴素
- 以点为基础进行扩展的,从局部最优到整体最优 + 贪心,若存在负权边则不满足局部最优 = 全局最优了
- 只能处理 稠密图 + 不存在负权边,用邻接矩阵存储图。
- 步骤:
const int N = 510;
//存储图
int g[N][N];
//存每个点到起始点的最小距离
int dist[N];
//标记每个点是否已经找到最短距离
bool st[N];
int Dijkstra()
{
//初始化距离信息,将起始点的最短距离设置为0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for(int i = 0; i < n; i++)
{
//开始 n 次循环,每次找未被找到最短路的点中最近的点
int t = 0;
for(int j = 1; j <= n ; j++)
{
if(dist[j] < dist[t] && !st[j])
{
t = j;
}
}
//将找到的点标记为已找到最短路
st[t] = true;
//查看加入新的点后是否有最短路更新
for(int j = 1; j <= n; j++)
dist[j] = min(dist[j], dist[t] + g[t][j]);
}
//该距离不会被更新,因为不与起点连通就不会被更新
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
Dijkstra-堆优化
- 利用邻接表,优先队列
- 利用堆顶来更新其他点,并加入堆中类似宽搜
const int N = 510;
//存储图
int h[N], e[N * 2], ne[N * 2], w[N * 2], idx;
//存每个点到起始点的最小距离
int dist[N];
//标记每个点是否已经找到最短距离
bool st[N];
//利用堆顶存距离最近的点(小根堆,前面存距离,后面存对应的点)
typedef pair<int,int> PII;
queue<PII,vector<PII>,greater<PII>> q;
int Dijkstra()
{
//初始化距离信息,将起始点的最短距离设置为0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
q.push({0, 1});
while(!q.empty())
{
//直接找到当前最小的距离的点
PII t = q.front();
q.pop();
int ver = t.second, distance = t.first;
//如果已经被标记为找到最小距离的点了,说明前面的距离已经被设置为最小的了,并且也不需要重复入队进行更新
if(st[ver]) continue;
st[ver] = true;
//更新与该点相连的点的 dist 距离
for(int i = h[ver]; i != -1; i = ne[i])
{
int j = e[j];
if(dist[j] > dist[ver] + w[i])
{
dist[j] = dist[ver] + w[i];
//距离更新了,入队
q.push({dist[j], j});
}
}
}
//该距离不会被更新,因为不与起点连通就不会被更新
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
Bellman_ford
- 可以解决负权边,负权环的问题,代码也简单,唯一的缺点就是速度太太太慢了
- 核心思想是每次增加可走的边的条数,每次更新限制内的最短距离(有边数限制的最短路)
- 在每次边条数扩展之前备份是为了避免串联的情况
const int N = 510, M = 10010;
//定义边
struct Edge{
int a;
int b;
int w;
}edges[M];
//定义到起点的最短路和每次循环开始之前的备份
int dist[N], back[N];
int Bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
//每次扩展一条边
for(int i = 0; i < n; i++)
{
//拷贝
memcpy(back, dist, sizeof dist);
//开始遍历每一条边
for(int j = 0; j < m; j++)
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
//避免串联导致的问题
dist[b] = min(dist[b], back[a] + w);
}
}
//这里条件不是等于是因为其遍历每一条边,距离有可能会减小
if(dist[n] > 0x3f3f3f3f / 2) return -1;
else return dist[n];
}
Spfa
- 可以解决负权边的最短路,若有负权环则会无限循环(但是可以判断负权环)
- st 数组不是标记已找到最短路的点,而是标记在队列中的点
- q 存储的是 dist 被更新过的点,将要更新其后继节点的 dist
- 检测图中的负权环可以使用标记到该点最短路所经过边数(cnt 数组迭代更新,且想象一个虚拟起点,详情看呆呆佬的 Orz)
const int N = 510;
//存储图
int h[N], e[N * 2], ne[N * 2], w[N * 2], idx;
//记录到起点的最短距离
int dist[N];
//记录该点是否在队列中
bool st[N];
//记录哪些点的最短距离被更新过
queue<int> q;
int spfa()
{
memset(dist, 0x3f, sizeof dist);
int dist[1] = 0;
st[1] = true;
q.push(1);
//若有负环则会死循环
while(!q.empty())
{
//当被更新最短距离的点还存在时弹出
int t = q.front();
q.pop();
st[t] = false;
//更新其后继节点的最短距离
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[j];
if(dist[j] > dist[t] + w[i])
{
//更新最短距离
dist[j] = dist[t] + w[i];
//若此点不在队列中,则将其加入队列中使其去更新其后继节点的最短距离
if(!st[j])
{
st[j] = true;
q.push(j);
}
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
Floyd
- 求多源最短路的方法,复杂度O(n^3)
- 初始化距离矩阵
- 三重循环更新距离
const int N = 210, M = 2e+10, INF = 1e9;
int n, m, k, x, y, z;
//存储任意两点之间的距离
int d[N][N];
void floyd() {
//i, j 循环可交换位置
for(int k = 1; k <= n; k++)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
int main() {
cin >> n >> m >> k;
//初始化距离矩阵
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
if(i == j) d[i][j] = 0;
else d[i][j] = INF;
while(m--) {
cin >> x >> y >> z;
d[x][y] = min(d[x][y], z);
//注意保存最小的边
}
floyd();
while(k--) {
cin >> x >> y;
//会更新最短距离
if(d[x][y] > INF/2) puts("impossible");
else cout << d[x][y] << endl;
}
return 0;
}
最小生成树问题
Prim
- 适合在稠密图中使用
- dist 存储的是到点集的距离,而不是到源点的距离,st 存储节点是否已经加入生成树
- 边中可以存在负权边,若某一个到点集的最小距离为无穷大则代表不连通
- 更新的时候用图中的边的距离
const int N = 510;
int g[N][N];//存储图
int dt[N];//存储各个节点到生成树的距离
int st[N];//节点是否被加入到生成树中
int pre[N];//节点的前去节点
int n, m;//n 个节点,m 条边
void prim()
{
memset(dt,0x3f, sizeof(dt));//初始化距离数组为一个很大的数(10亿左右)
int res= 0;
dt[1] = 0;//从 1 号节点开始生成
for(int i = 0; i < n; i++)//每次循环选出一个点加入到生成树
{
int t = -1;
for(int j = 1; j <= n; j++)//每个节点一次判断
{
if(!st[j] && (t == -1 || dt[j] < dt[t]))//如果没有在树中,且到树的距离最短,则选择该点
t = j;
}
//如果孤立点,直返输出不能,然后退出
if(dt[t] == 0x3f3f3f3f) {
cout << "impossible";
return;
}
st[t] = 1;// 在点的集中加入该点
res += dt[t];
for(int i = 1; i <= n; i++)//更新生成树外的点到生成树的距离
{
if(dt[i] > g[t][i] && !st[i])//从 t 到节点 i 的距离小于原来距离,则更新。
{
dt[i] = g[t][i];//更新距离
pre[i] = t;//从 t 到 i 的距离更短,i 的前驱变为 t.
}
}
}
cout << res;
}
Kruskal
- 按照边的权重从小到大合并不同集合
- 用了并查集
using namespace std;
const int N = 100010;
int p[N];//保存并查集
struct E{
int a;
int b;
int w;
bool operator < (const E& rhs){//通过边长进行排序
return this->w < rhs.w;
}
}edg[N * 2];
int res = 0;
int n, m;
int cnt = 0;
int find(int a){//并查集找祖宗
if(p[a] != a) p[a] = find(p[a]);
return p[a];
}
void klskr(){
sort(edg, edg + m);
for(int i = 1; i <= m; i++)//依次尝试加入每条边
{
int pa = find(edg[i].a);// a 点所在的集合
int pb = find(edg[i].b);// b 点所在的集合
if(pa != pb){//如果 a b 不在一个集合中
res += edg[i].w;//a b 之间这条边要
p[pa] = pb;// 合并a b
cnt ++; // 保留的边数量+1
}
}
}
二分图
染色法判定二分图
- 搜索每个连通图查看其是否满足二分图的性质
- 可以使用 dfs 和 bfs 搜索
- 维护的各个节点的状态就是他们被染的颜色
const int N = 100010 * 2;
int h[N], e[N], ne[N], idx;//邻接表存储图
int color[N];//保存各个点的颜色,0 未染色,1 是红色,2 是黑色(状态)
int n, m;//点和边
bool dfs(int u, int c)//深度优先遍历
{
color[u] = c;//u的点成 c 染色
//遍历和 u 相邻的点
for(int i = h[u]; i!= -1; i = ne[i])
{
int b = e[i];
if(!color[b])//相邻的点没有颜色,则递归处理这个相邻点
{
if(!dfs(b, 3 - c)) return false; //如果递归处理过程中出错则返回失败
}
else if(color[b] && color[b] != 3 - c)//如果已经染色,判断颜色是否为 3 - c
{
return false;//如果不是,说明冲突,返回
}
}
return true;
}
int main()
{
memset(h, -1, sizeof h);//初始化邻接表
for(int i = 1; i <= n; i++)//遍历点
{
if(!color[i])//如果没染色
{
if(!dfs(i, 1))//染色该点,并递归处理和它相邻的点
{
cout << "No" << endl;//出现矛盾,输出NO
return 0;
}
}
}
cout << "Yes" << endl;//全部染色完成,没有矛盾,输出YES
return 0;
}
匈牙利算法求二分图最大匹配数(NTR算法)
- 建议看 yxc 讲一遍就懂了
- 存图的时候边存一遍就行了,因为找的时候是通过遍历男生找对象
- match 数组表示女生匹配的男生编号
- st 数组用于预定女生,用于其现男友换对象时避开这个女生
//存的图中边不是完整的,只存了男生到女生的边
int h[N], e[N], ne[N], idx;
//match[j]=a,表示女孩j的现有配对男友是a
int match[N];
//st[]数组我称为临时预定数组,st[j]=a表示一轮模拟匹配中,女孩j被男孩a预定了。
int st[N];
//这个函数的作用是用来判断,如果加入x来参与模拟配对,会不会使匹配数增多
int find(int x)
{
//遍历自己喜欢的女孩
for(int i = h[x] ; i != -1 ;i = ne[i])
{
int j = e[i];
if(!st[j])//如果在这一轮模拟匹配中,这个女孩尚未被预定
{
st[j] = true;//那x就预定这个女孩了
//如果女孩j没有男朋友,或者她原来的男朋友能够预定其它喜欢的女孩。配对成功,更新match
if(!match[j]||find(match[j]))
{
match[j] = x;
return true;
}
}
}
//自己中意的全部都被预定了。配对失败。
return false;
}
//记录最大匹配
int res = 0;
for(int i = 1; i <= n1 ;i ++)
{
//因为每次模拟匹配的预定情况都是不一样的所以每轮模拟都要初始化
memset(st,false,sizeof st);
if(find(i))
res++;
}

最短路问题和最小生成树以及二分图问题主要理解每一步为什么这么写,不用再进一步抽象