目录
0.基础概念
1.新鲜事–消息流的实现方式
2.用户系统(1)–缓存
2.用户系统(2)–好友关系
3.网站系统、API–翻页
3.短网址系统
4.数据库拆分和一致性哈希
5.分布式文件系统
BigTable
由于文件系统只能提供一些简单的读写文件操作,当有复杂查询需求的时候,就需要在文件系统之上建立一个更为复杂的系统,负责把数据存储到文件系统,并提供方便操作数据的接口。
设计需求
需求比较单一,给出key/过滤条件,返回value。
从文件系统的基础上思考搭建数据库系统
-
查询操作:直接在硬盘里面进行排序和二分。
-
更新操作:直接在文件最后面追加(append)一条记录
这种方式操作速度快,但是存在的问题是无法识别哪个是最新的记录,而且没有顺序无法进行二分查找。
解决方案:- 对于识别最新的记录,可以通过添加时间戳,时间戳最大的结果就是最新的数据。
- 对于顺序问题可以通过分块来解决,将数据拆分成多个文件块,只有最后一块无序,其他文件块有序。当最后的文件块写满之后,开一个新的文件块,定期将无序的文件块进行排序。
- 块越写越多,可能会有很多重复数据,每次查询所有的块非常消耗时间,可以通过定期多路归并解决。
一个可行的读写过程
直接把无序的文件块放到内存中,如果文件写满,排序后统一写入到硬盘中,写入过程中可以同步写入Log(Write Ahead Log)到硬盘,防止机器失效后,内存中的数据丢失。
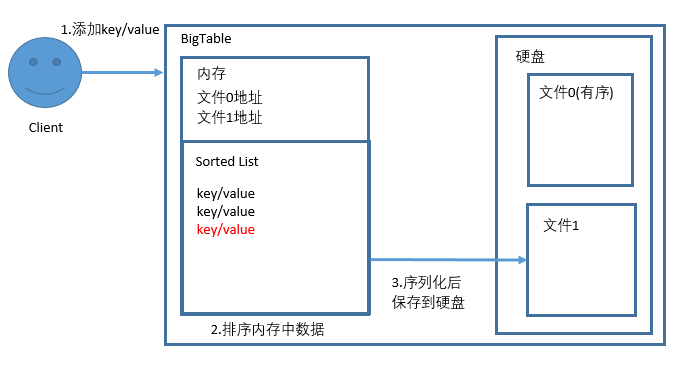
读取过程大致相同,优先从内存中查找,如果没有找到,再到硬盘的文件中进行查询。
在文件中查询除了二分查找,还可以使用索引,把一些Key放入内存作为index,通过内存中的查询,快速定位到数据的位置,可以有效的减少磁盘的读写次数。感兴趣可以参考B树和B+树等相关资料。
更好的定位key的方法(布隆过滤器BloomFilter)
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
创建过程主要是通过多个hash函数计算同一个数值,并且记录。当有新的key需要查询的时候,如果发现hash计算的结果不同,表示key一定不在这个文件中。
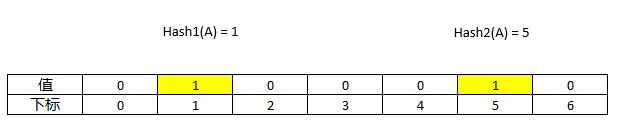
可能会出现误判,hash计算出来的结果恰好与其他key相同

结果不同一定不同,结果相同可能不同
bloomfilter精确度与hash函数的个数,位数组的长度和存入元素的数量都有关系。实际应用中误判率并不会很高,而且在降低误判率方面产生了有很多不同的变种,有兴趣可以自行了解。
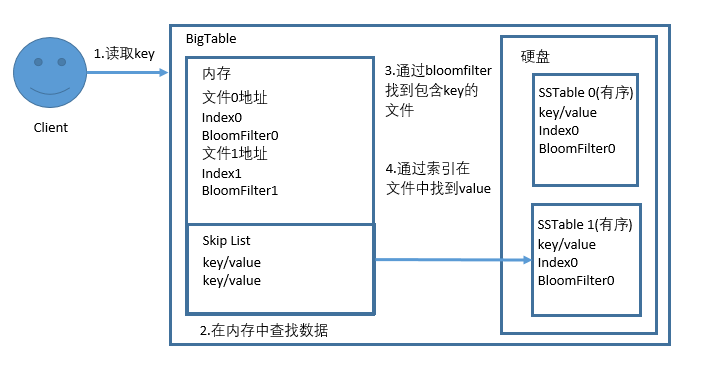
加入bloomfilter之后,完整读取过程如下:
硬盘中的文件一般称为SSTable(Sorted String Table),内存中的Sorted List可以使用跳表(Skip List)实现
具体算法可以参考 力扣1206 设计跳表
拓展系统
一些问题在之前的内容中已经涉及到
1. 如何读写1Pb的文件:数据库拆分
2. 一台机器搞不定,需要多台机器:Master + Slave模式,一致性哈希,Master作为哈希表,记录key和server地址。
3. 多台机器如何读写:以读取为例
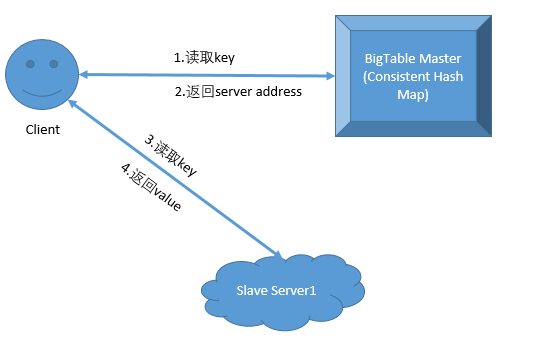
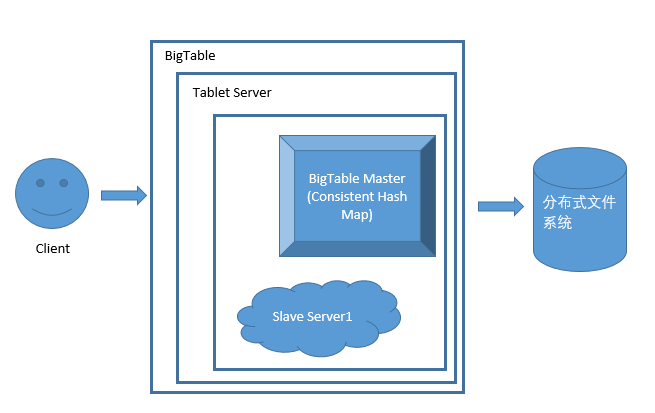
数据越来越多,服务器硬盘写不下怎么办:使用分布式文件系统,整体框架
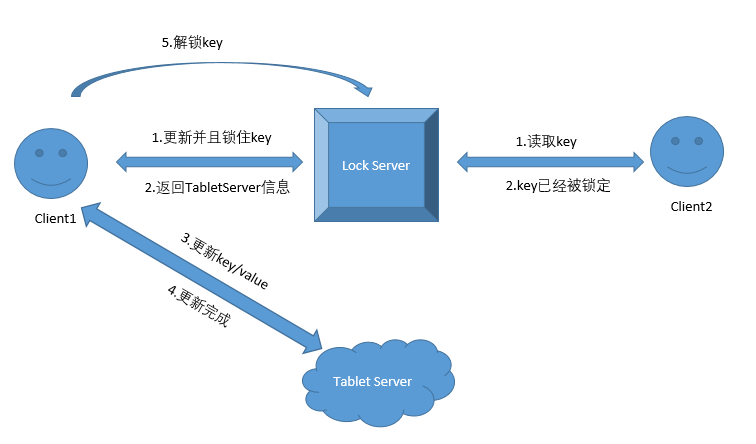
读写竞争
读和写同时发生的时候,没办法确定读取的是新值还是旧值,这个时候就需要用到分布式锁服务,常用的比如Zookeeper。
而且加入锁服务之后,原来存在Master节点上的一些Metadata也可以保存到锁服务器上面。
拓展内容
外排序:内存只有2G的情况下,怎么排序8G的数据?
将8G数据分4次读入内存排序,排序成功后写回到硬盘,然后通过多路归并算法每次读取少量数据到内存的堆中,再从堆中选取最小的元素写回硬盘,实现排序。
力扣23. 合并K个升序链表
BST, B Tree, B + Tree
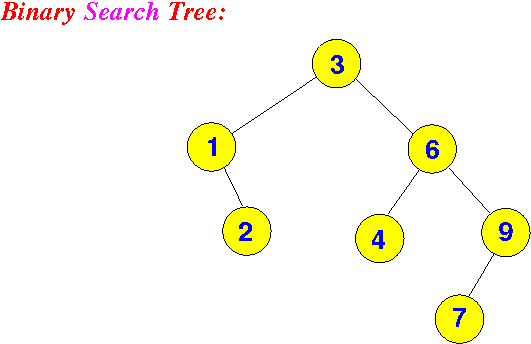
二叉搜索树(BST)
- 左边都比root小
- 右边都比root大
- 查找时间与高度h有关
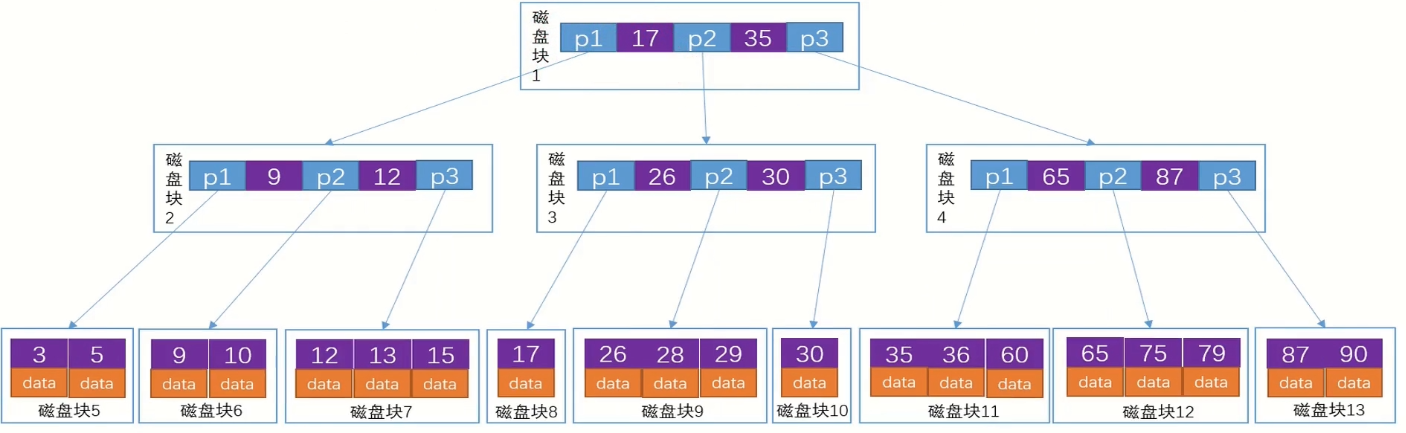
B Tree
如果有10亿数据,想要长期保存只能存在硬盘中,而硬盘的读写很慢,对BST来说效率并不高。
优化:把二叉树变成多叉树,降低树高h,每个磁盘块保存子节点的指针和当前节点的data
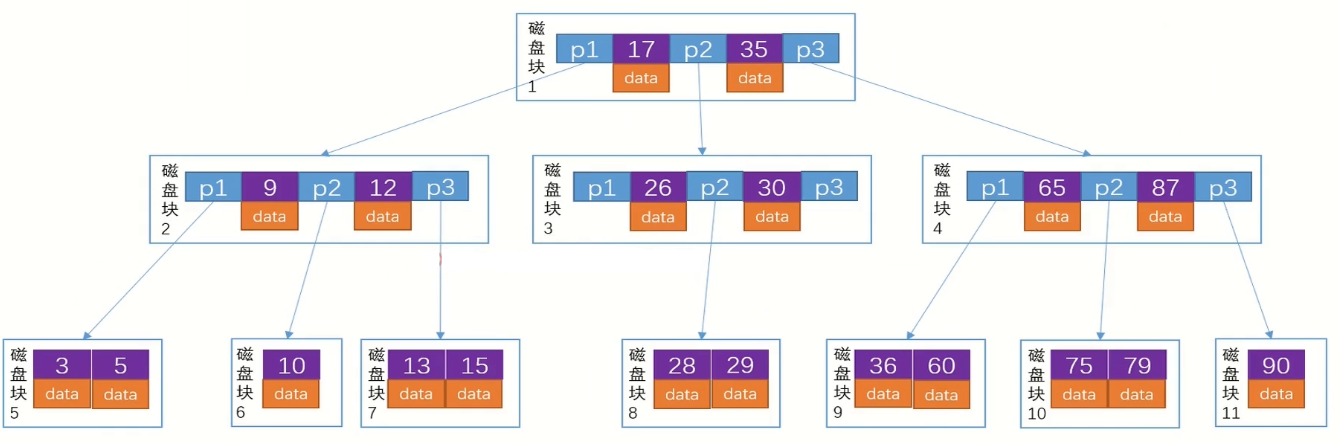
B+ Tree
B Tree存在的问题就是非叶子节点中data占用了太多的空间,磁盘块的空间是有限的,data越大,能存储的key数量越小,也就是叉树会变小。解决方案就是非叶子节点不保存data,一个磁盘块16kb可以存1000个key的话,3层可以保存大约10亿个key。