
国庆假期第一天,开摆开摆,做一个python上机作业放松下hh
任务描述

这个作业这么有意义的嘛?做完之后单词直接拿捏~开干开干!
分析任务后,得出解决思路和大致的步骤,分模块儿分步骤各个击破
- 使用字典保存每个单词的出现次数
- 打开文件
- 读取文件内容
- 统计文章中每个单词出现的次数
- 将每个单词出现的次数写入文件并保存
代码实现
1. word_number.py
#函数statistic_word()实现统计单个文本文件中英文单词出现的次数,统计结果存到word_dict
def statistic_word(source_file_name):
word_dict = {}
try:
with open(source_file_name, "r") as fp:
line_content = fp.read()
word_list = line_content.split() # 使用空格对读取内容进行拆分
for word in word_list:
# 删除一些特殊符号,防止对提取单词造成误判
word = word.rstrip('.').rstrip(',').rstrip(':').rstrip("()").strip('"')
# 只统计纯英文单词,同时限制单词的长度大于1
if word.isalpha() and len(word) >1:
word = word.lower() # 将单词都转为小写
word_dict[word] = word_dict.get(word,0) + 1 #完成一个单词出现次数的计数
except:
print("文件:'%s'不存在!"%source_file_name)
return word_dict
2、word_sort.py
# 函数write_statistic_results()实现将统计结果以降序排列并写入文件。
def write_statistic_results(word_dict): #将刚刚统计好的word_dict传入
# 将字典的值从大到小进行排序
sort_list = sorted(word_dict.items(), key = lambda x:x[1],reverse=True)
# 将统计结果写回文件words_number.txt中并保存
with open("words_number.txt","w",encoding="UTF-8") as fp:
for item in sort_list:
# item是字典中的元素,item[0]作为key值表示单词,item[1]作为value表示此单词出现的次数
fp.write("%s:%d\n"%(item[0],item[1]))
3、test.py
# 测试模块
from word_number import statistic_word
from word_sort import write_statistic_results
file_name = input("请输入文件名(若有多个文件,中间用英文逗号隔开):\n")
file_name_list = file_name.split(",") #若有多个文件,就以英文的,分隔开
total_word_dict = {} # 结果字典
for file_name in file_name_list:
file_name = file_name.strip() # 删除每个文件前后的空格或者换行符,增强输入的鲁棒性
words_dict = statistic_word(file_name)
for key, value in words_dict.items(): # 遍历每篇文章的结果词典
total_word_dict[key] = total_word_dict.get(key, 0) + value
write_statistic_results(total_word_dict) # 调用函数,得出结果
选取的数据集文章
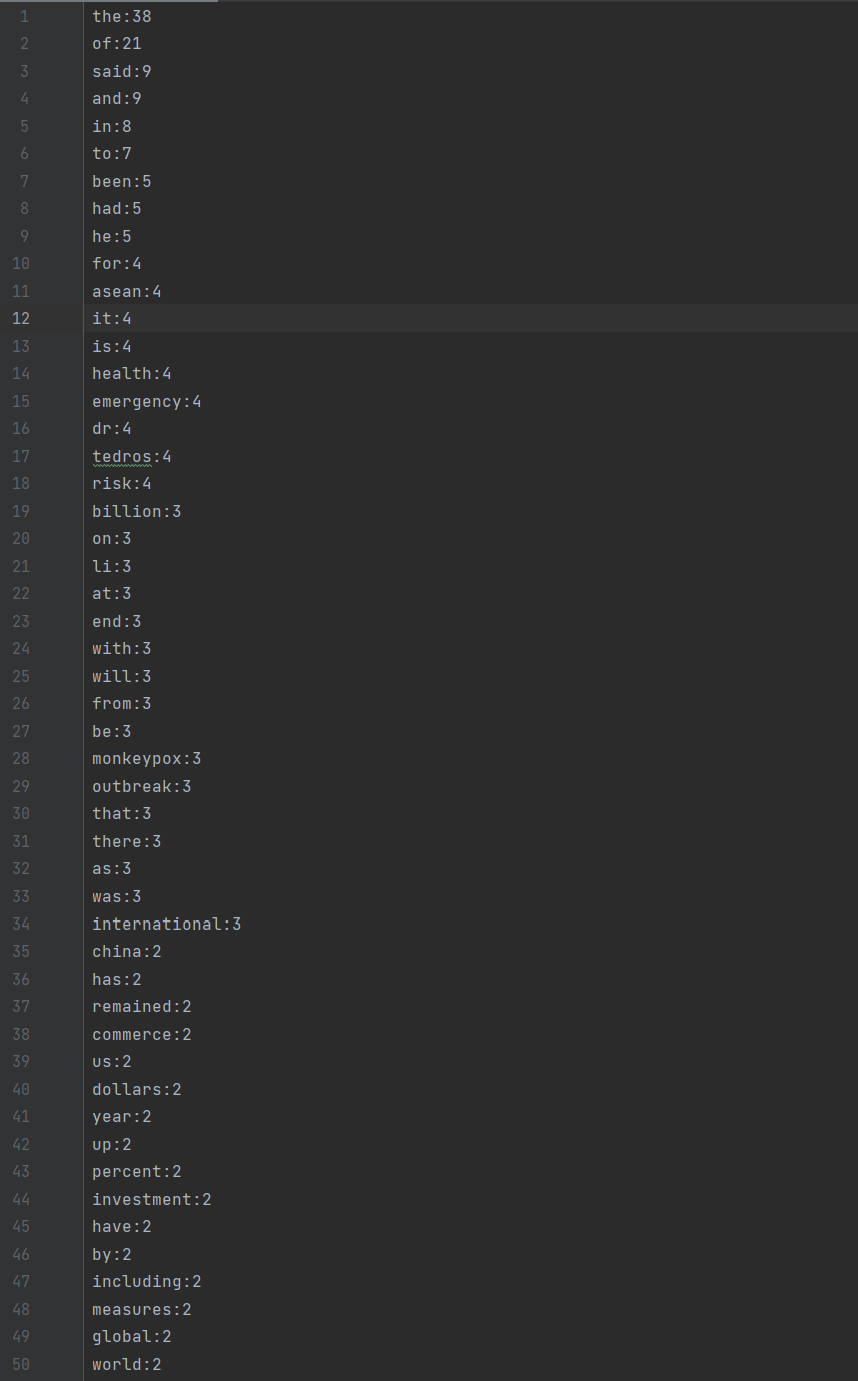
统计结果

注意with语句
with语句的作用是自动关闭文件,释放资源;不用写关闭文件的操作,简化了代码。
with open("data.txt", "w") as fp: # 打开文件
fp.write("Hello Python") # 写入数据
with open("first.txt", "r") as fp1, open("second.txt", "w") as fp2:
# 在这里通过文件对象读写文件内容的语句
