
1.Redis的内存回收机制
这里需要介绍Redis的近似LRU算法了,它和常规的LRU算法不一样。近似LRU算法通过随机采样淘汰数据,每次随机出5个key,选择最近最少使用的那个进行淘汰。Redis为每个key存储一个24bit的字段,用于存储该key最后一次被访问的时间。
那为什么不使用标准的LRU算法呢?
因为标准LRU需要占更多的内存,标准LRU采用链表,除了kv外,每个node需要保存前后node的地址。
扩展:Redis 3.0对近似算法做了优化:新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。
Redis4.0采用LFU,网上资料很多,这里不再赘述。
2. Redis的key失效机制
Redis的key失效机制有两种:被动方式和主动方式。
被动方式:当客户端尝试访问该key,如果发现key已经失效了则删除该key,并由服务器告诉客户端已经失效了。
主动方式:存在一些过期key,且客户端不再访问。Redis不会遍历所有的key,这样太浪费时间了,Redis会随机抽取一些key进行校验,如果失效了就删除淘汰。
3. 如何用Redis实现分布式锁
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
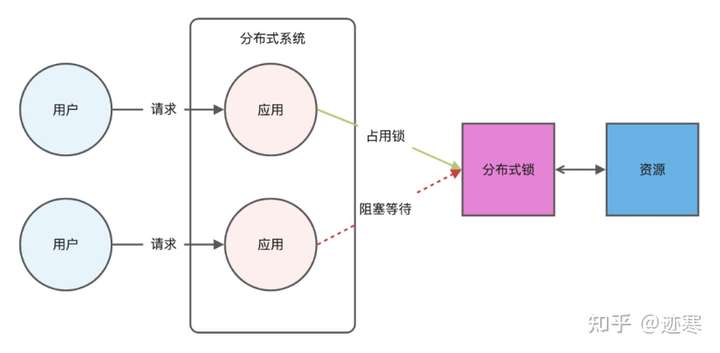
先拿setnx来抢锁,然后同expire给锁加一个过期时间防止忘记释放。
对应的命令是SET lock_key unique_value NX PX 10000.
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
分布式锁的优点:
- 性能高效
- 实现方便,很多研发直接用redis来实现分布式锁。
- 避免单点故障
缺点:
- 超时时间不好设置。如果锁的超时时间设置过长,会影响性能,如果超时时间过短就保护不到共享资源。解决方案:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可,不过这种方式实现起来相对复杂。
- Redis主从模式中,数据是异步复制的,这样导致分布式锁不可靠。如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
4. Redis真的是单线程吗
单线程指【接收和处理客户请求】由单个线程完成。但其实redis还有其它的线程:
- Redis 2.6,会在后台启动两个线程,分别处理关闭文件、AOF刷盘这两个任务;
- Redis 4.0 在以后,新增了一个线程,专门用于异步内存释放(lazyfree)。
5. Redis是单线程的,为何如此高效
- Redis是基于内存操作,采用高效的数据结构。CPU不可能是Redis的瓶颈,Redis瓶颈更有可能是内存或者网络带宽。
- Redis采用单线程可以避免线程之间资源竞争,减少线程上下文切换带来的性能开销。
- Redis采用I/O多路复用来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他同样以单线程运行的模块进行对接,这保持了Redis内部单线程设计的简单性。
6. 请你回答以下Memcached和Redis的区别?
Memcached是内存中的键值存储,最初用于缓存。它的设计十分简单 ,并且容易部署。它有内置的 API,提供分布在多台机器上的非常大的哈希表,并使用内部内存管理来提供更高的效率。
MemcacheD 仅支持 String 数据类型。Redis支持几乎所有类型的数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志和通过半径查询的地理空间索引。Redis 还可用于用作 pub / sub 的消息传递系统。
Memcached不使用持久化数据。而Redis 可以处理持久数据。默认情况下,它定期将数据同步到磁盘。
Memcached不支持复制,而redis采用主从复制。
MemcacheD 非常适合处理高流量场景。它可以一次读取许多信息,并在很长的响应时间内返回。Redis 既不能处理读取时的高流量,也不能处理繁重的写入。
Memcached的key最大长度250,而Redis为最多2GB。
7. 请你回答一下MongoDB和Redis区别
MongoDB是遵从文档存储结构最流行的NoSQL数据库之一。
内存管理机制上,Redis数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的LRU算法删除数据。MongoDB 数据存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘。
支持的数据结构上:Redis 支持的数据结构丰富,包括hash、set、list等。
MongoDB 数据结构比较单一,但是支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富。
8. 什么是缓存穿透?什么是缓存雪崩?什么是缓存击穿?如何避免?
缓存穿透指:大量请求不存在的key导致服务器必须绕过redis去后台数据库查找数据,造成很大的压力。
如何避免:最好方法是使用bloom filter这种过滤器,如果key不存在直接返回。或者缓存空对象。
缓存雪崩:当缓存服务器重启或者大量缓存在同一个时间段失效,这样会给后端系统带来很大的压力,导致服务器崩溃。
如何避免:1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
缓存击穿:一个存在的key,在缓存过期的瞬间,同时有大量请求,导致对DB访问暴增。
如何避免:设置热点数据永不过期,或者设置互斥锁。

宝儿姐[舔一舔]
图佬[舔一舔]