
A.递归
基础知识
1.思想:自己调用自己

2.举例:斐波那契数列
斐波那契数列这个例子很好,即可用来学递归也可以用来学递推

3.代码实现:
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std;
int f(int n)
{
if(n==1) return 1;
if(n==2) return 2;
return f(n-1)+f(n-2);
}
int main()
{
int n;
cin>>n;
cout<<f(n)<<endl;
return 0;
}
注意scanf和cin的输入效率区别,因为cin有输入缓冲区,导致输入数据范围过大时会很慢,而scanf相对比较快,printf和cout的输出效率同理。
cin、cout头文件:#include <iostream>
scanf、printf头文件: #include <cstdio>,在c++11中不加这个,scanf和printf也能用,但最好加上

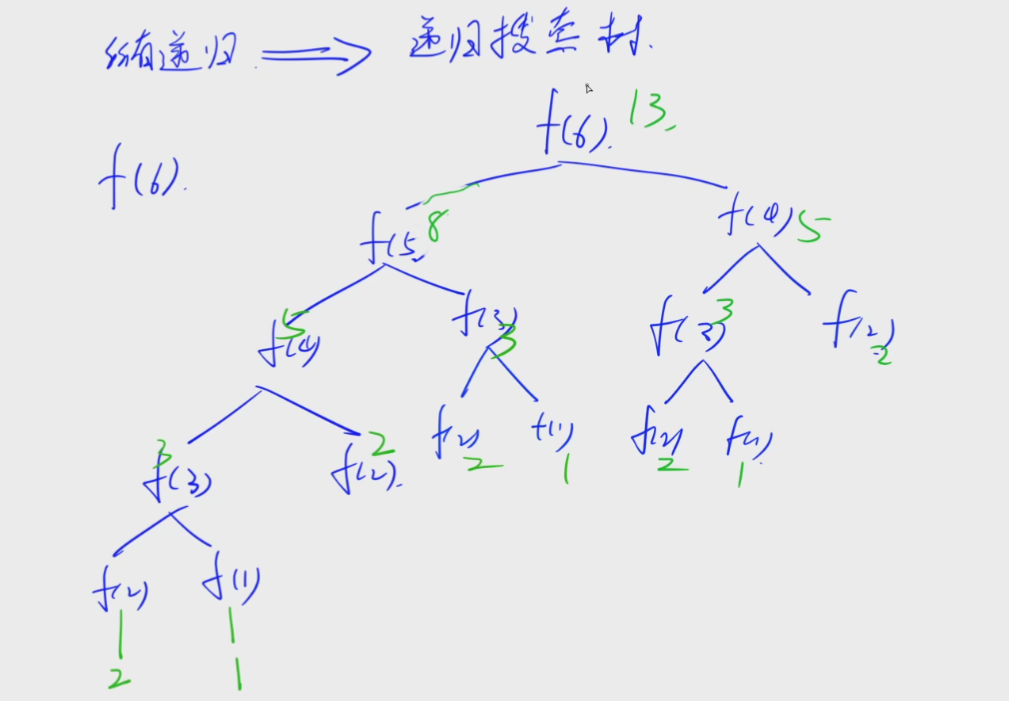
4.分析:递归搜索树
如何分析递归的执行顺序?
所有递归都可以用递归搜索树结构分析表示,都可以转化成一颗递归搜索树
但是可以发现它的时间复杂度很高,这个题目是2的n次方
动态规划和递归:
正向分析是动规(dp),逆向分析是递归(dfs),记忆化就是加上一个特征变量表示
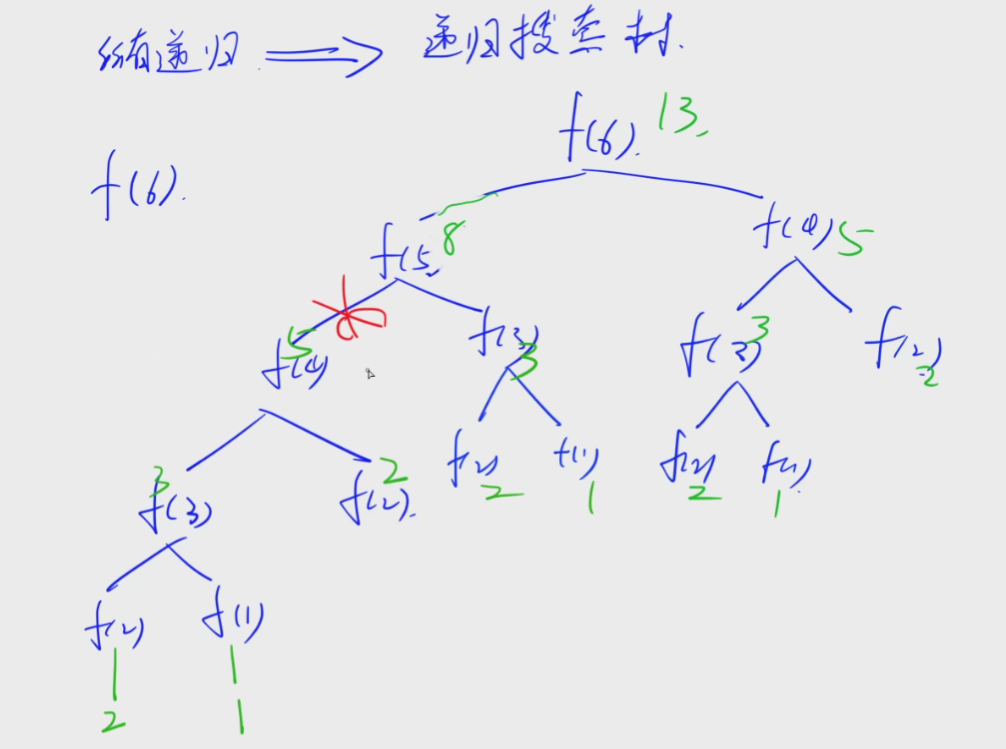
5.剪枝:
剪枝就是砍掉一个分支,如果提前返回的话相当于当前这个分支没有了,给这颗树砍掉了一个分支。
在递归搜索树中,有的分枝本身就是错误的,我们在还没往下递归时就先把这个分枝减掉,这样return返回上一级分枝时就不会走这个错误的分枝,省去了时间。
例题
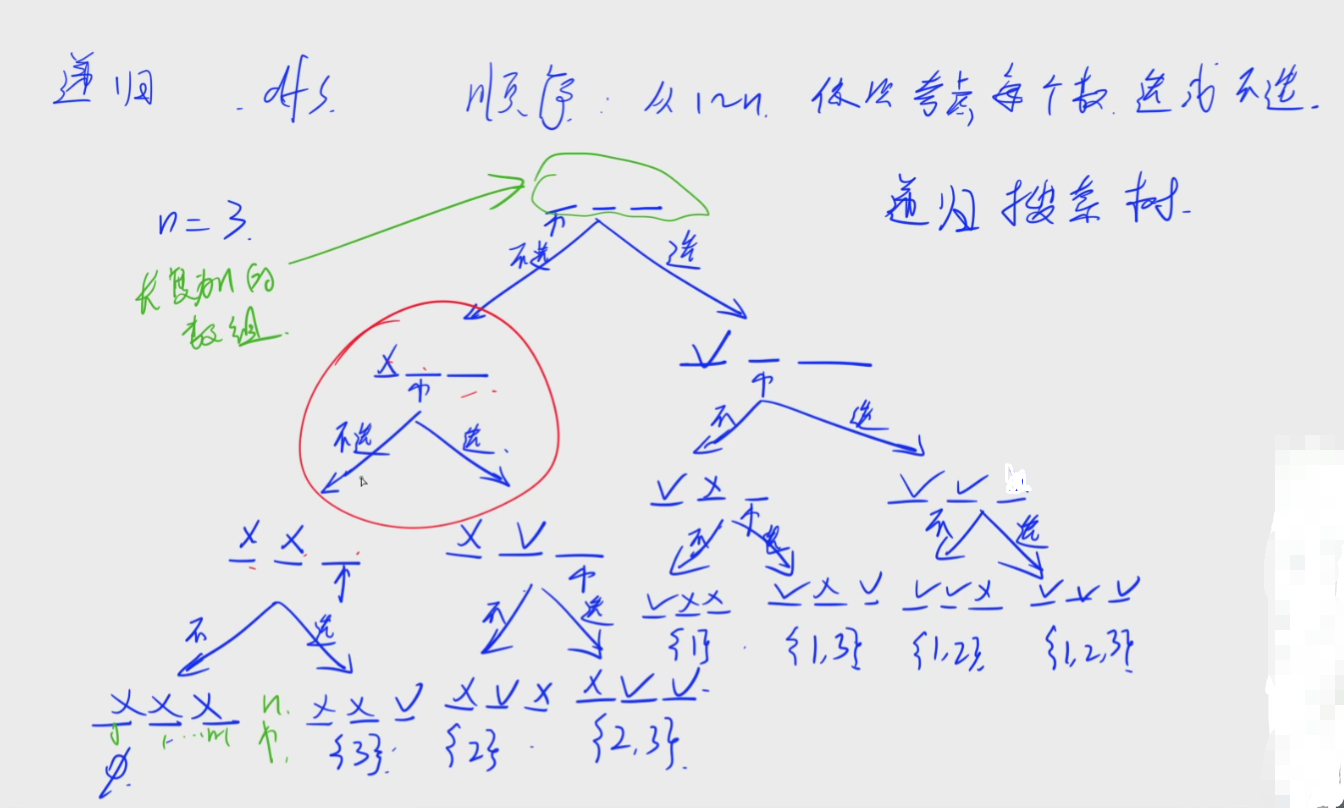
一、递归实现指数型枚举
1.基本思路:
2.注意:
(1)递归(或者是DFS)最重要的是顺序,要想一个顺序能把所有方案不重不漏的找出来。
(2)注意空和选和不选是有区别的
(3)我们需要记录状态,这个递归中有三种状态:选、没选、空(没考虑过),开一个长度为n的数组来记录。
3.时间复杂度:
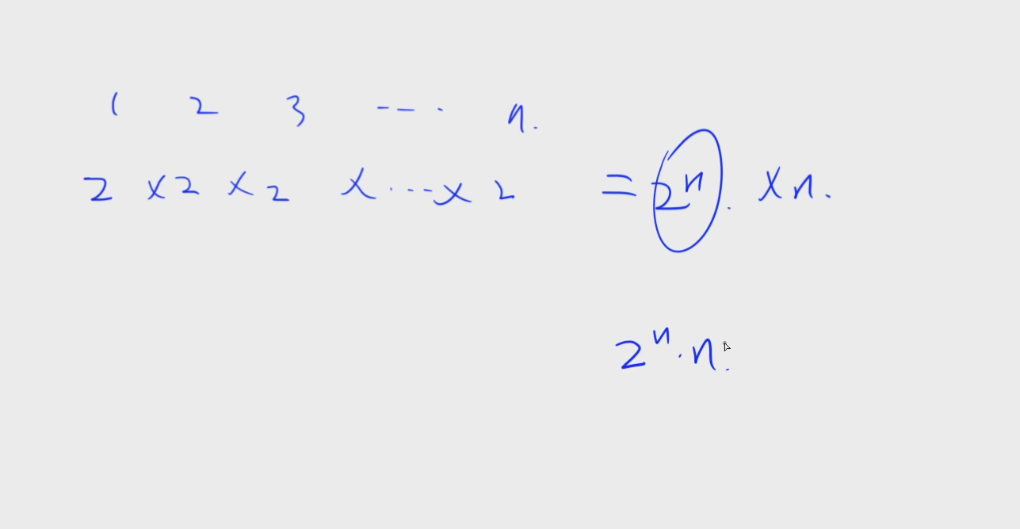
/*
常识:
2的0次方~2的10次方: 1 2 4 8 16 32 64 128 256 512 1024
2的20次方 近似为10的6次方(100万)
2的16次方 65536
2的15次方 32768
2的63次方 近似为2的18次方
*/
4.代码:
//第一种
//在判断边界时直接输出方案
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 16;//定义数据范围,习惯用const定义,范围比题目中要求的稍大一点即可
int n;
int st[N]; //定义一个数组表示状态,记录每个位置当前的状态:0表示还没考虑,1表示选它,2表示不选它
void dfs(int u) //u表示当前枚举第几位
{
if (u > n) //第一步:判断边界
{
//在return之前要先把这个方案输出
for (int i = 1; i <= n; i ++ ) //方案如何表示?从前往后枚举每个位置,看看这一位有没有选
if (st[i] == 1) //如果说当前这一位是1的话,表示选了它,就把它输出
printf("%d ", i);
printf("\n");//注意输出格式
return;//到底边界之后不能再递归了,要return
}
//第二步:分支:尝试每一种可能。(每一种情况都要先标记当前处于某一个节点,接下来递归到下一个位置,最后要恢复现场)
st[u] = 2;
dfs(u + 1); // 第一个分支:不选
st[u] = 0; // 恢复现场(即把变之后的状态恢复成变之前的状态,因为不能让儿子影响决策,要做一个公平的父节点,所以怎么变过去的就要怎么变回来)
st[u] = 1;
dfs(u + 1); // 第二个分支:选
st[u] = 0;//恢复现场
}
int main()
{
cin >> n;
dfs(1); //dfs(1,st),dfs中传递的是当前枚举到第几位
//一开始是写起点,从1开始,那就是1~n,也可以是0~n-1
//st因为定义的是全局数组,所以就不用传进去,直接在函数中使用修改即可
return 0;
}
//第二种
//如何把方案记录下来,而不是直接输出?
//二维数组记录方案
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 16;
int n;
int st[N]; // 状态,记录每个位置当前的状态:0表示还没考虑,1表示选它,2表示不选它
int ways[1 << 15][16];//用一个二位数组记录所有方案,1<<15表示一共有2的15次方个方案,15表示每一个方案会有15个数
int cnt;//cnt表示当前方案的数量是多少
void dfs(int u)
{
if (u > n)
{
for (int i = 1; i <= n; i ++ )
if (st[i] == 1)
ways[cnt][i] = i; //把每一个方案存进数组中
cnt ++ ;//记录完一个之后,说明方案多了一个,所以cnt++
return;
}
st[u] = 2;
dfs(u + 1); // 第一个分支:不选
st[u] = 0; // 恢复现场
st[u] = 1;
dfs(u + 1); // 第二个分支:选
st[u] = 0;//恢复现场
}
int main()
{
cin >> n;
dfs(1);
for(int i=0 ; i < cnt; i ++ ) //把所有方案输出
{
for(int j=1;j<=n;j++)
{
if(ways[i][j]!=0)
printf("%d ",ways[i][j]);
}
puts("");//输出一个回车,等价于printf("\n");
//因为puts是输出的是一个字符串加一个回车,因为这里输出的是一个空字符串,所以等价于只输出了一个回车
}
return 0;
}
//第三种
//用vector数组记录方案(就不需要特判处理里,但是效率会比前两种慢)
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 16;
int n;
int st[N]; // 状态,记录每个位置当前的状态:0表示还没考虑,1表示选它,2表示不选它
vector<vector<int>> ways;
void dfs(int u)
{
if (u > n)
{
vector<int>way;
for (int i = 1; i <= n; i ++ )
if (st[i] == 1)
way.push_back(i);
ways.push_back(way);
return;
}
st[u] = 2;
dfs(u + 1); // 第一个分支:不选
st[u] = 0; // 恢复现场
st[u] = 1;
dfs(u + 1); // 第二个分支:选
st[u] = 0;//恢复现场
}
int main()
{
cin >> n;
dfs(1);
for(int i=0 ; i <ways.size(); i ++ ) //把所有方案输出
{
for(int j=0;j<ways[i].size();j++)
{
printf("%d ",ways[i][j]);
}
puts("");//输出一个回车,等价于printf("\n");
//因为puts是输出的是一个字符串加一个回车,因为这里输出的是一个空字符串,所以等价于只输出了一个回车
}
return 0;
}
5.总结:
/*
递归(DfS)模板总结:
bool state[]; //定义一个数组表示状态,记录每个位置当前的状态
//也可以定义成int型,根据需求和习惯来
//这是所说的状态就是深搜时的顺序,状态就是如何把顺序表示出来,有几种状态表示顺序就开几个状态数组
void dfs(int step)//step表示当前枚举第几位
{
第一步:判断边界
{
(1)相应操作
//一般是输出方案等操作
(2)return;
//注意:1.void型函数不能return一个值,但是如果只是return;表示当前这一层函数到此终止。
//2.return会结束当前这层递归,返回上一层递归去,u也会变为上一层的值
}
第二步:枚举分支:尝试每一种可能
{
前提:满足某一个check条件
(1)标记:表示当前所在的节点位置处于哪种状态(更新状态)
(2)继续下一步dfs(step+1):递归到下一个位置
(3)恢复现场 :节点有几个状态表示数组就恢复几个。原因:回溯时要用到,即把变之后的状态恢复成变之前的状态,因为不能让儿子影响决策,要做一个公平的父节点,所以怎么变过去的就要怎么变回来
}
}
int main()
{
dfs(递归起点,state) //dfs(1,state),dfs中传递的是当前枚举到第几位
//一开始是写起点,从1开始,那就是1~n,也可以是0~n-1
//st如果定义的是全局数组,就不用传进去了,直接在函数中使用修改即可
}
*/
二、递归实现排列型枚举
1.基本思路:
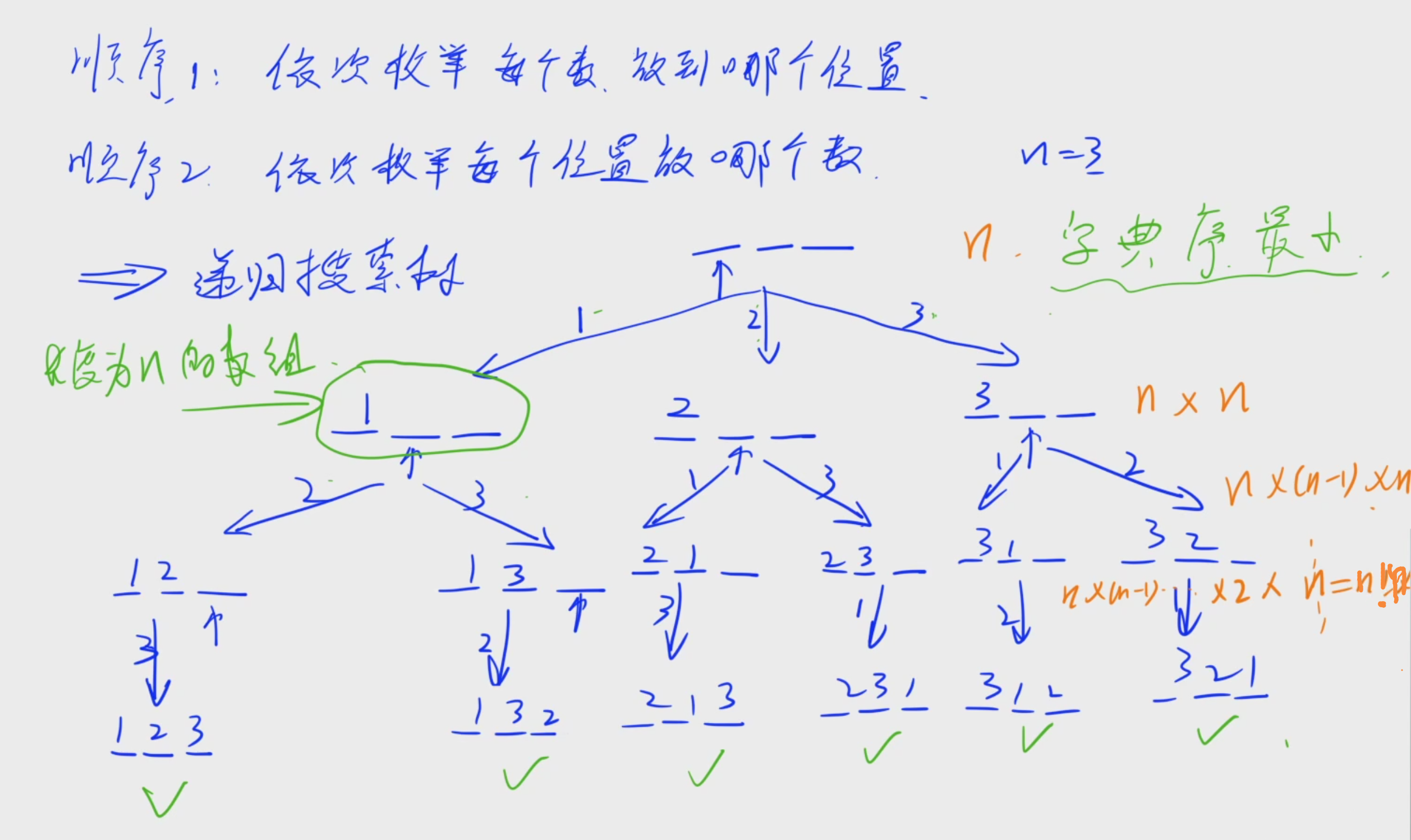
什么是字典序?

分析题目样例:

基本思路:
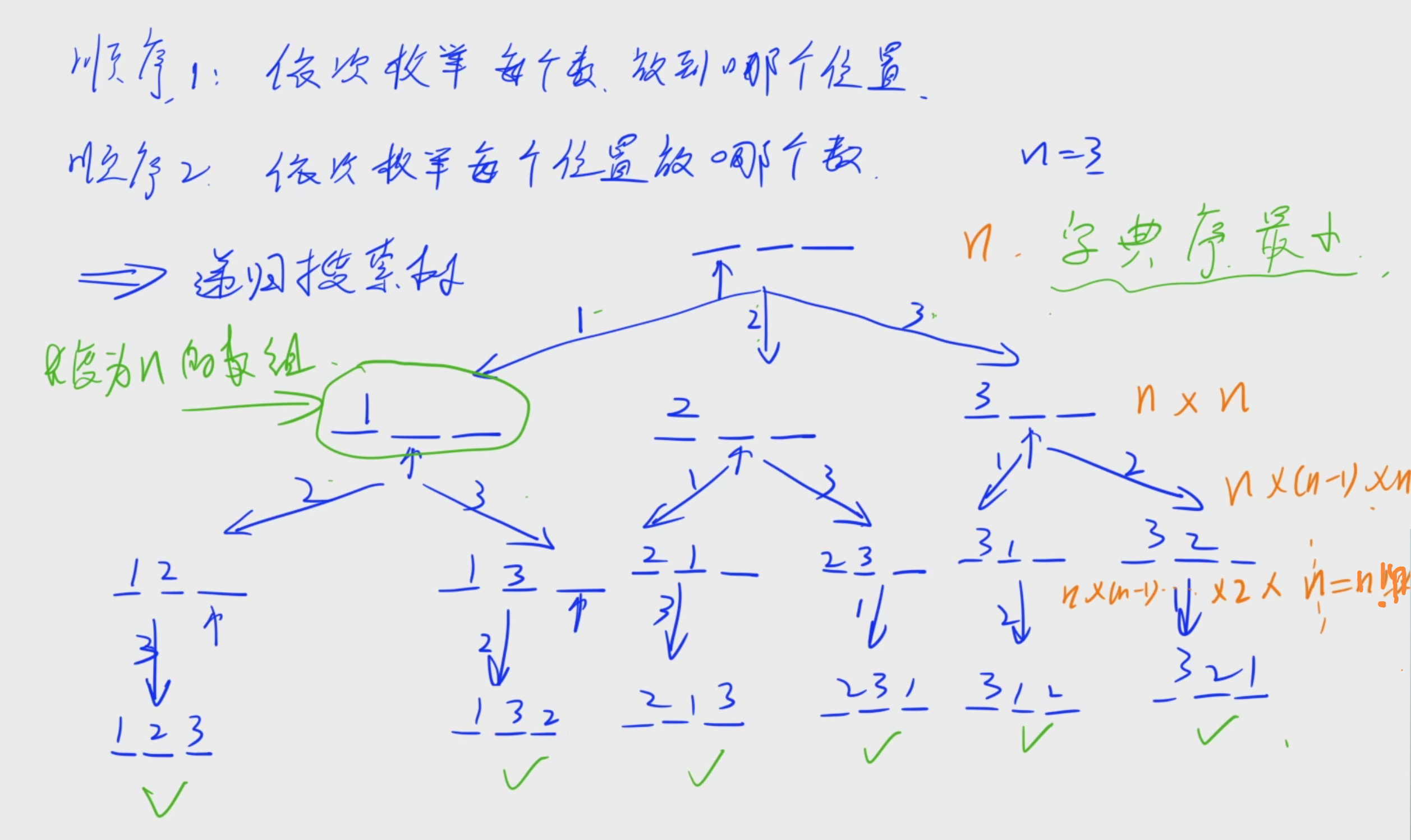
2.注意:
(1)全排列问题一般有两种递归顺序,要么是枚举位置,要么枚举数,这里以顺序2为例。
(用递归首先要想一个顺序,能把所有方案不重不漏输出出来)
(2)注意这个题目输出要求按字典序最小输出
(题目要求按字典序输出最小的意思,一般来说是出题人比较懒,如果是输出任意一个方案,都要写一个专门的程序来判断这个方案是不是正确的,就太麻烦了。因此出题人一般为了省事,会直接要求输出一个字典序最小的一个方案,这样的话方案的顺序就唯一了。然后,出题人本身就是为了偷懒,也不想难为我们,因此一般来说题目如果想让我们输出一个字典序最小的方案的话,我们只需要注意一下,在每次做的时候,只需要从小到大枚举每个数,保证每一步每一个分支都是按照字典序最小来枚举的,那么得到的方案一定就是最小的。)
一般情况下,我们不需要去特殊的关注字典序最小的这个限制,只要按照正常的思路去写,思路不要过于奇葩,他的字典序就一定是最小的。
此题的字典序最小证明:
首先因为是深度优先搜索,第一个分支里面,字典序是1的所有方案一定都小于字典序是2的,字典序是2的所有方案一定小于字典序为3的,因此在第一个分支里面,按照1、2、3的顺序来枚举一定是字典序最小的。因此,在递归来看。在每一个分支中,我们一定都是先枚举字典序最小的,再枚举字典序较大的。所以,每一步都是按照从小到大顺序来枚举,因此最终走到叶结点的顺序也一定是按照从小到大的顺序走到的。
也可以用反证法来证明:
否则,假设这个顺序不是字典序最小的方案,那么就必然存在两个相邻的方案,字典序后面比前面大,对于这两个相邻方案而言,每个方案都有n个数,我们从后往前来看一定会找到第一个不同的数,对于这个第一个不同的数找到他的分支,在这个分支里面就会发现我们是先枚举的较大的数,再枚举的较小的数,就矛盾了,因为我们本来是按照从小到大的顺序来枚举的,这就矛盾了。所以反证不成立,那么原来的结论成立。
3.代码:
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10;//题目中N的范围是9,但我们如果下标想从1开始,那么多用一个,开10
int n;
//此题可以发现在搜索的时候还要保证每个数只搜索一次,要判断当前这个位置可以用的数有哪些,
//因此还要存一个新的状态used:表示每个数有没有被用过
int state[N]; // 用st[]表示当前的状态:0 表示还没放数,1~n表示放了哪个数
bool used[N]; // true表示用过,false表示还未用过
//注意变量如果定义成全局变量的话,初值会自动赋成0,如果定义成随机变量的话,初值是一个随机值
void dfs(int u)
{
if (u > n) // 边界:枚举完了最后一位,
{
for (int i = 1; i <= n; i ++ ) printf("%d ", state[i]); // 打印方案:只需要把当前每个位置输出出来
puts("");
return;
}
// 依次枚举每个分支,即当前位置可以填哪些数
for (int i = 1; i <= n; i ++ )//从小到大枚举
if (!used[i])//如果当前位置是没有用过的,表示当前位置可以填这个数,成为一个分支,等价于used[i]==false
{
state[u] = i;//标记,更新状态
used[i] = true;//标记,更新状态,因为此题递归时需要两个状态表示
dfs(u + 1);//递归下一步
// 恢复现场,两个状态都要恢复
state[u] = 0; //当然,在这里state[]状态数组其实可以不用恢复,因为会直接覆盖掉,但是为了更好的展现算法流程,方便初学者理解最好加上
used[i] = false;
}
}
int main()
{
scanf("%d", &n);
dfs(1);//从前往后枚举,函数里面写一个参数,表示当前枚举到第几位了
//因为state[]和used是全局变量了,所以不需要写到函数参数里面
return 0;
}
4.总结补充:
/*
小结补充:
(1)state[]数组:该状态是用来表示顺序2,枚举哪个位置放了哪个数
//与递归实现指数型枚举的区别:
(2)used[]数组:该状态是因为排列要保证搜索时每个数只能搜一次,所以新增了used数组来标记使用情况。
(3)具体用几个根据搜索时具体需求来
(4)回溯时前面有几个状态数组就恢复几个 ,有时因为覆盖原的因不恢复也对,但为了理解最好都恢复
(5)函数传参传几个参数也是要灵活来看
*/
5.时间复杂度:
/*
会递归n层,第一层复杂度n,第二层n*n,第三层n*(n-1)*n,......第n层 为n*n!
所以总的时间复杂度为:n*(1+n*(n-1)+n*(n-1)*(n-2)+......+n!) ,可以把n提出来
*/
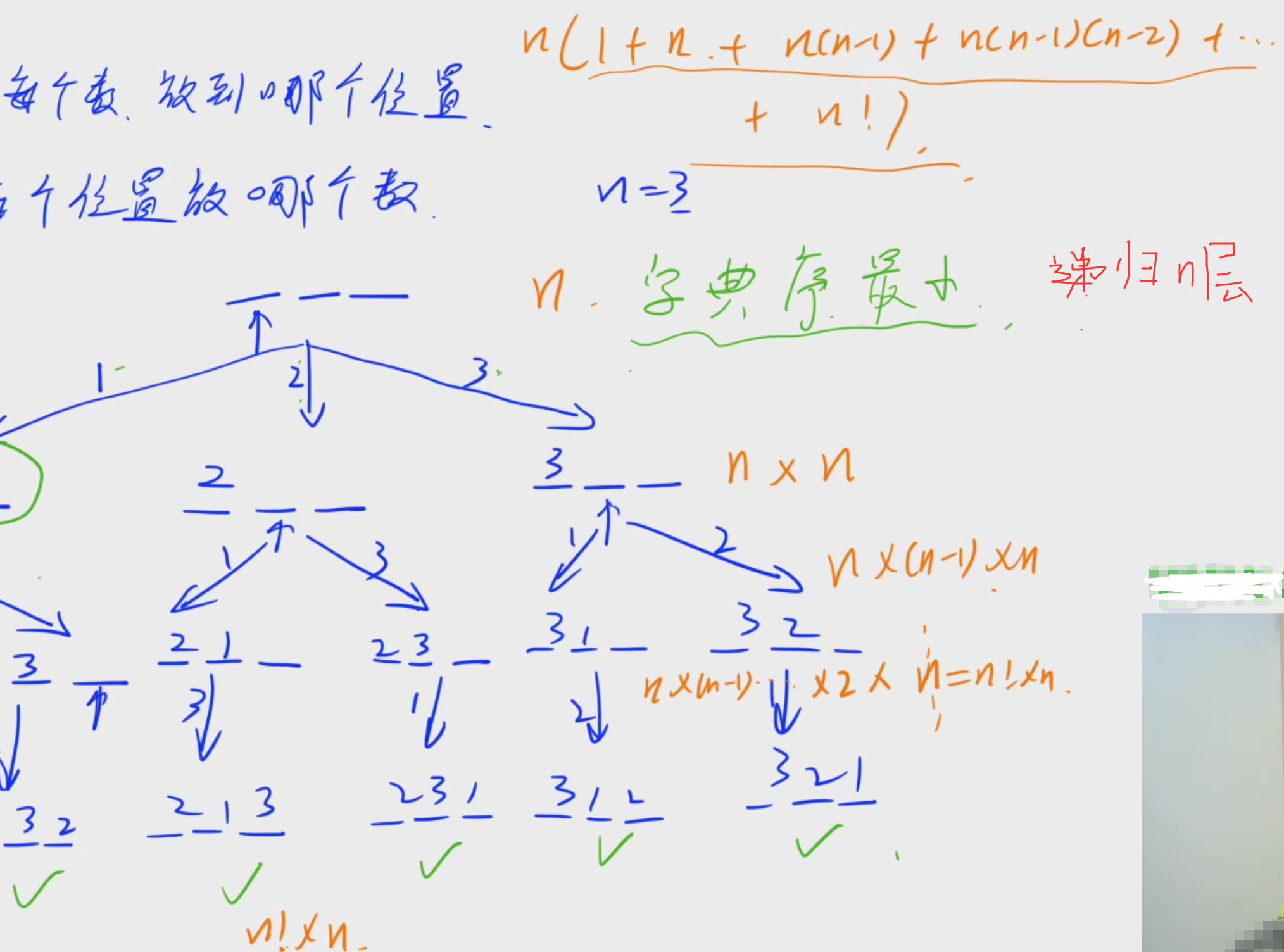
/*
算一下括号里的等式的大概递归数量级:在n!~3n!之间(n! =< 括号内等式 =< 3n!) ,约为 O(n!)
*/
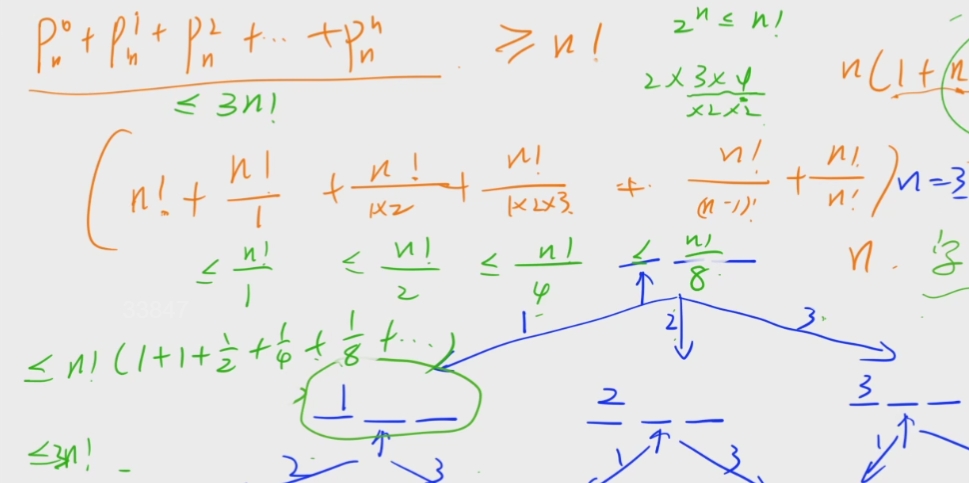
/*
所以最终的 时间复杂度为 O(n*n!)
*/
三、递归实现组合型枚举
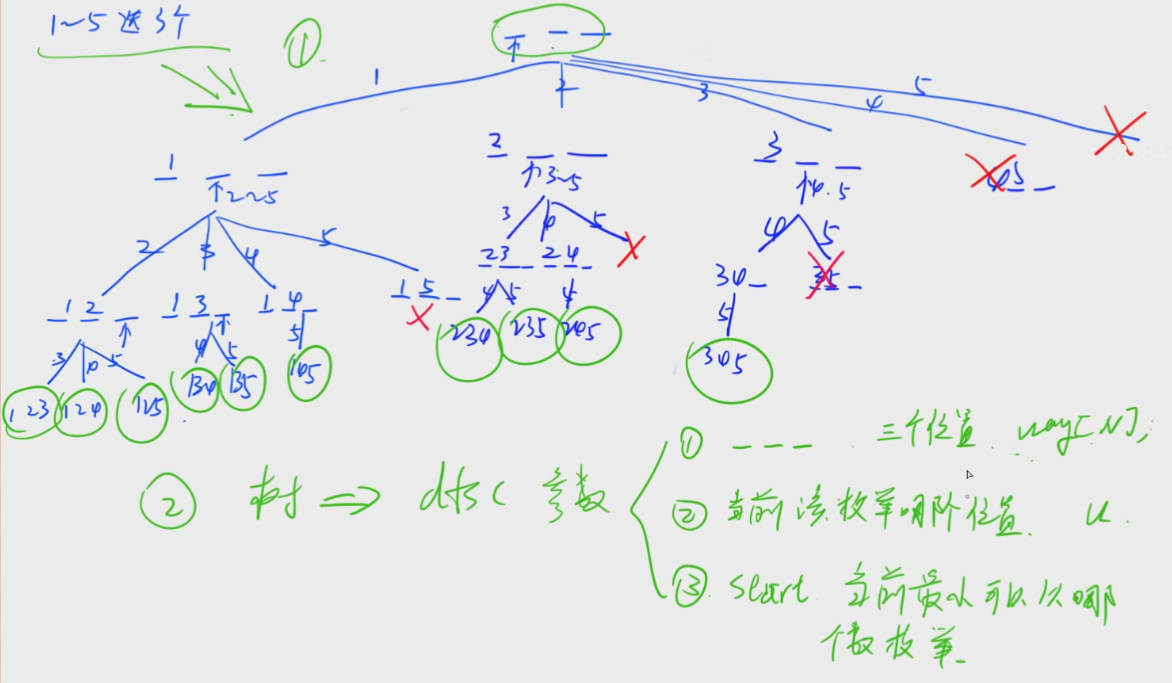
1.基本思路:
(1)首先,明确排列和组合的区别:
排列要考虑顺序(123与132是不同的方案),组合不需要考虑顺序(123与132是同一种方案)

小白思路顺序:从前往后一个数一个数枚举,优先换最后一个数位置
(注意:第一遍学算法要用纸和笔去画一下,相当于一开始学加法列竖式,不要干想;该算法熟悉之后可以直接写,相当于加法口算)
(2)如果按照上面的思路会发现,跟上一道 递归实现排列型枚举 的题目思路一样,如果这么做的话肯定会把一种方案重复输出多次,如何去避免这种问题呢?(如何实现不重复呢?)
可以人为得规定一种顺序(人为定序),使得这种顺序对于每一个方案集合来说只有一种方案满足
我们发现123和132是一种方案,只需要输出123即可,所以可以按照第一个数从小到大排序
即在递归的时候加一个限制,限制方案内部的每一个数是从小到大排序,保持升序选择。
又因为升序是一个局部属性,只需要考虑相邻两个数之间的关系即可
所以只需要保证每种方案中:下一个数永远>上一个数(这也是递归实现排列和组合最大的区别)
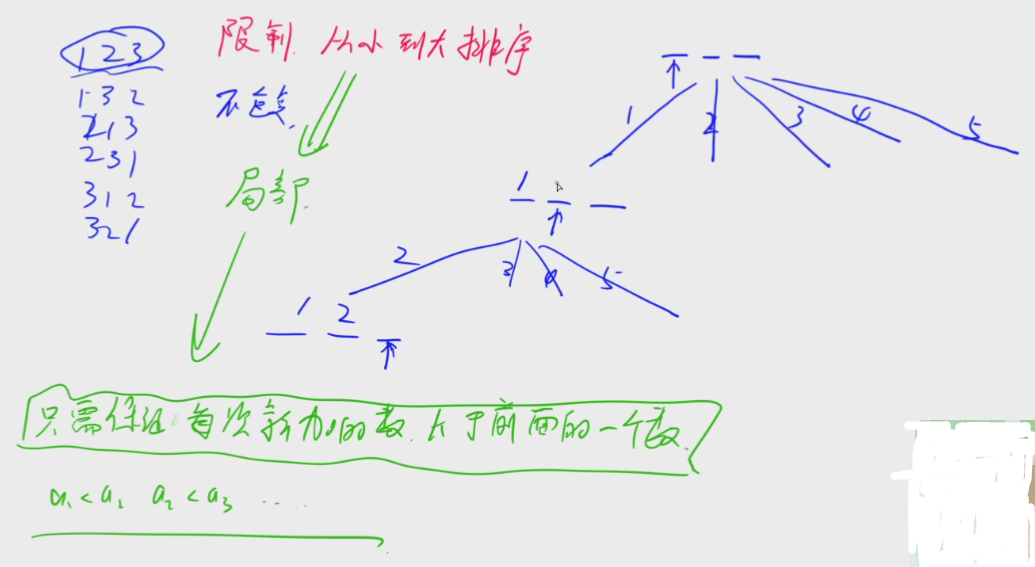
(3)画出这种思路的递归搜索树:
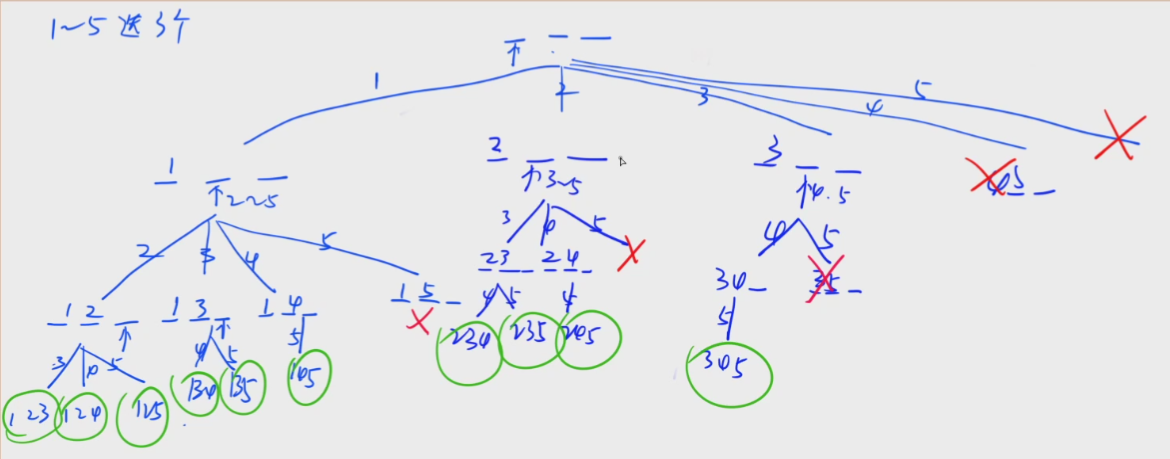
(4)
第一步,要想如何把普通的答案顺序转换为递归搜索树的顺序
第二步,要想如何把搜索树的形式转换为dfs代码
转换为代码的核心是考虑dfs()参数有哪些?
注意参数有两种形式:
①全局变量:可以写成全局变量,不一定非得写成dfs()函数中真正的参数去
②函数形参:作为( )内的形参传入
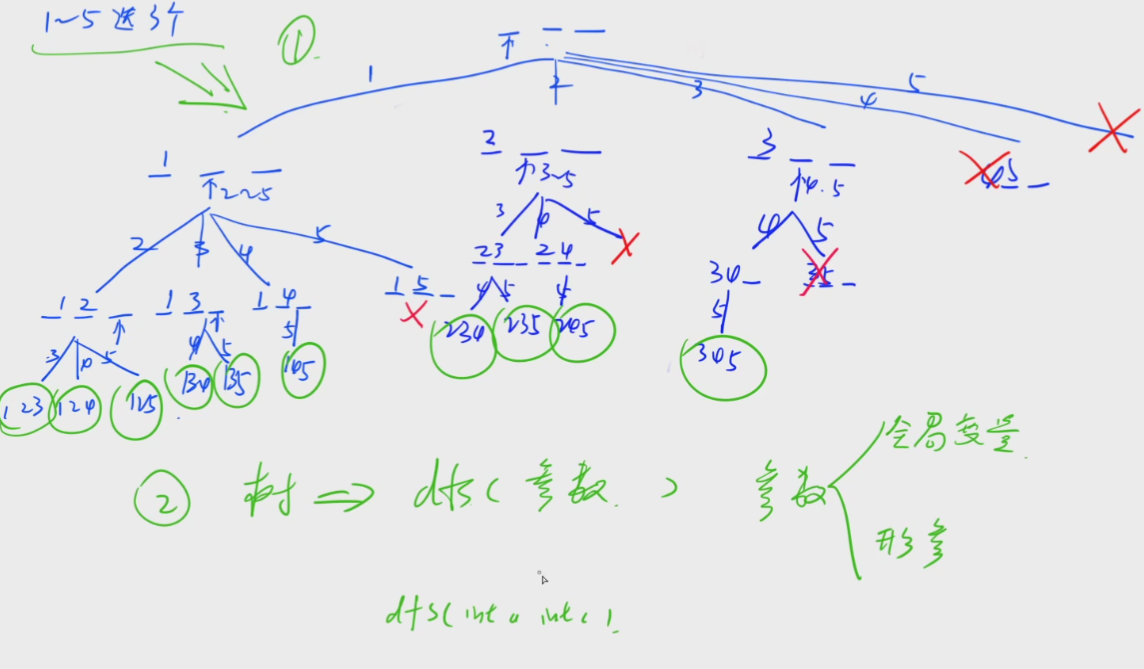
(5)如何判断要传哪些参数呢?
经验问题,写多了就有感觉了,第一遍在做的时候只能慢慢的去分析,分析过一遍之后后面就很好做了,万事开头难。
本题中应该传哪些参数?
①记录方案状态:比如需要存三个数的位置,开一个长度为N的数组way[N]
②当前该枚举哪个位置:传一个变量就可以u
③当前最小可以从哪个数开始枚举:因为要保证升序选择(每个数在枚举的时候一定要比前一个数大),传一个start
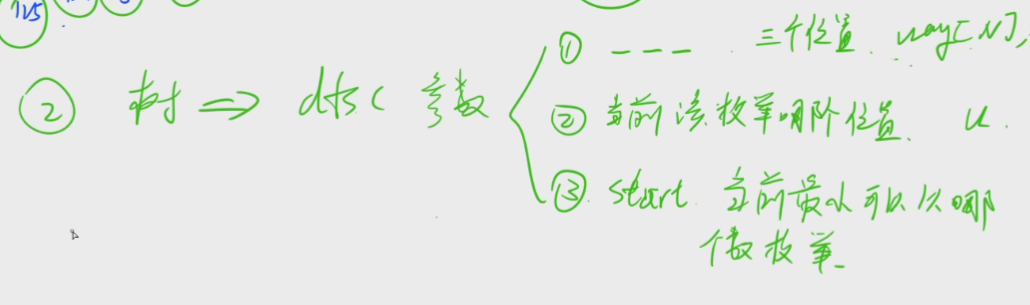
这三种状态都是我们在题目中要自己分析看出的状态,第一次做的时候可能要花时间去记忆理解,等再去做类似组合型枚举题目时,就能直接去使用去想到这三种状态了。
(6)三种模式:
递归实现指数型枚举:每次两个分支选或者不选
递归实现排列型枚举:考虑顺序的所有枚举方案
递归实现组合型枚举:不考虑顺序所有枚举方案。
区别:
组合比排列的参数多了一个:start用来保证升序选择
但组合比排列的数组少了一个:排列里面需要加一个判重数组st[ ],因为它不知道每个数有没有用过,而组合不需要用到判重数组,因为每次枚举的时候保证了下一个数永远比上一个数大。比上一个数大的话一定比前面所有数都大,因此当前出现的数一定在前面都没出现过,所以判重数组在组合中是可以忽略的。
2.注意:
(1)本题中字典序的问题:
第一个分支里的所有数的第一个数一定是1,因此第一个分支里的所有方案一定比第二个分支字典序小,其次是第二个分支,其次是第三个分支,递归下来每个分支都是一样的。因此只要按照从小到大的顺序来枚举,那么得到的必然就是一个字典序的顺序。
(2)数据范围:
组合数是杨辉三角,中间角取最值。

3.代码:
//原始做法:
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 30;//多开,防止数组越界
int n, m;
int way[N];//表示方案
void dfs(int u, int start)//u表示该枚举哪个位置,start表示从哪个位置开始枚举
{
if (u == m + 1)//判读边界:表示选了恰好m个数
{
for (int i = 1; i <= m; i ++ ) printf("%d ", way[i]); //输出方案
puts("");//输出一个回车,输出格式
return;
}
for (int i = start; i <= n; i ++ )//从start到n开始枚举
{
way[u] = i;//每一次把当前这个数放到way[]数组中去
dfs(u + 1, i + 1);//递归下一层 :因为当前最后一个数是i,所以要从i+1开始
way[u] = 0; // 恢复现场:用0来表示空,因为当前这个数枚举完之后后面都是空的,要恢复
//当然这个不加在这也对,后面会把他覆盖掉,但标准上最全的角度要加上
}
}
int main()
{
scanf("%d%d", &n, &m);
dfs(1, 1);
return 0;
}
//剪枝优化做法:
/*
剪枝:当发现这个分支没有解,那么可以提前退出
可以发现:当(u-1)+(n-start+1)<m 时,无解
整理:当u+n-start<m时,无解
*/
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 30;//多开,防止数组越界
int n, m;
int way[N];//表示方案
void dfs(int u, int start)//u表示该枚举哪个位置,start表示从哪个位置开始枚举
{
if (u + n - start < m) return; // 剪枝
if (u == m + 1)//判读边界:表示选了恰好m个数
{
for (int i = 1; i <= m; i ++ ) printf("%d ", way[i]); //输出方案
puts("");//输出一个回车,输出格式
return;
}
for (int i = start; i <= n; i ++ )//从start到n开始枚举
{
way[u] = i;//每一次把当前这个数放到way[]数组中去
dfs(u + 1, i + 1);//递归下一层 :因为当前最后一个数是i,所以要从i+1开始
way[u] = 0; // 恢复现场:用0来表示空,因为当前这个数枚举完之后后面都是空的,要恢复
//当然这个不加在这也对,后面会把他覆盖掉,但标准上最全的角度要加上
}
}
int main()
{
scanf("%d%d", &n, &m);
dfs(1, 1);
return 0;
}
四、带分数
1.题意
给定一个数N,问有多少组a,b,c满足a+b/c=N,且a,b,c三个数不重不漏地涵盖1−9这9个数字,输出总组数
2.注意:
(1)/:一般来说在题目中没有特殊声明是整除的话,我们都认为是正常意义(带小数)的除法
(2)在考试中只要能AC即可,不用非得追求最优,找一个最好写的,平时练习要追求最优。
(3)要会看题目的空间限制:
①64MB(兆)能开多大的空间(数组)?大约能开1.6千万个int

②虽然题目给了我们64兆,但我们不能真的使用64兆,因为它还会有其他的栈开销,一般用个60兆就极限了。
③程序中的数组并不是开多大就会占多大空间,这个操作系统会给我们做优化,如果开一个很大的数组但是不用的话,他也是不会占空间的。
3.思路及代码:
(1)暴力解题思路:
- 递归枚举全排列:暴力枚举出9个数的全排列,然后用一个长度为9的数组保存全排列的结果
枚举完全排列之后会有九个数
- 枚举位数:从全排列的结果中用两重循环暴力分解出三段,每段代表一个数
可以边枚举边算,不用先枚举再算
- 判断等式是否成立:验证枚举出来的三个数是否满足题干条件,若满足则计数
把a,b,c转换为数字,判断是否满足等式

时间复杂度:
枚举全排列的时间复杂度n!n,在这为9! 9 ,枚举位数是C8/2
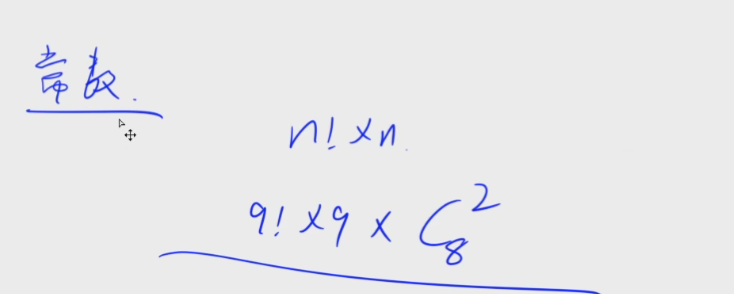
#include <iostream>
using namespace std;
const int N = 10;
int target; // 题目给出的目标数
int num[N]; // 保存全排列的结果
bool used[N]; // 生成全排列过程中标记是否使用过
int cnt; // 计数,最后输出的结果
// 计算num数组中一段的数是多少
int calc(int l, int r) {
int res = 0;
for (int i = l; i <= r; i++) {
res = res * 10 + num[i];
}
return res;
}
// 生成全排列
// 当全排列生成后进行分段
void dfs(int u) {
// 用两层循环分成三段
if (u == 9) {
for (int i = 0; i < 7; i++) {
for (int j = i + 1; j < 8; j++) {
int a = calc(0, i);
int b = calc(i + 1, j);
int c = calc(j + 1, 8);
// 注意判断条件,因为C++中除法是整除,所以要转化为加减乘来计算
if (a * c + b == c * target) {
cnt++;
}
}
}
return;
}
// 搜索模板
for (int i = 1; i <= 9; i++) {
if (!used[i]) {
used[i] = true; // 标记使用
num[u] = i;
dfs(u + 1);
used[i] = false; // 还原现场
}
}
}
int main() {
scanf("%d", &target);
dfs(0);
printf("%d\n", cnt);
return 0;
}
下面再给出一个直接调用 next_permutation() 函数的做法,可以代替手写暴搜来枚举全排列,蓝桥杯是可以使用这个函数的。
很多同学都比较疑惑循环边界问题,事实上像下面的代码一样,都写成全排列数组的个数( 9 )也是一样的,只不过上面的代码在写的时候处理得更加细致一些,实际上没必要,像下面这么写就可以了。
#include <bits/stdc++.h>
using namespace std;
const int N = 10;
int target;
int num[N];
int calc(int l, int r) {
int res = 0;
for (int i = l; i <= r; i++) {
res = res * 10 + num[i];
}
return res;
}
int main() {
cin >> target;
for (int i = 0; i < 9; i++) {
num[i] = i + 1;
}
int res = 0;
do {
for (int i = 0; i < 9; i++) {
for (int j = i + 1; j < 9; j++) {
int a = calc(0, i);
int b = calc(i + 1, j);
int c = calc(j + 1, 8);
if (a * c + b == c * target) {
++res;
}
}
}
// 调用函数生成全排列
} while (next_permutation(num, num + 9));
cout << res << '\n';
return 0;
}
(2)优化版:
要优化的话根据题目中本身的性质来优化。
优化一:刚才是没有用到n的任何信息,是暴力枚举的a、b、c
但可以发现:由于n是给定的,所以自变量并不是有三个,自变量只有两个,n=a+b/c 可以转换为 cn=c a+b ,因此只需要枚举a和c即可,b可以直接根据等式算出来
(这样优化就是只枚举了两个变量,第三个变量是直接算出来的,比暴力枚举三个变量就快多了)
优化二:剪枝
根据数据范围来看 1<=N<=10的6次方,因此n最多有6位,a也最多只有6位
如果a>=n,return
优化思路:
-
先枚举a,
-
对于每个枚举的a来说,再去枚举c,
-
对于每个a和c来说,判断b是否成立

其实把两个排列函数的组合起来,两个dfs的嵌套关系
这里全排列不能直接使用next_permutation() ,next_permutation() 只能求所有的1~n整个区间的全排列,不能把某一部分的全排列
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10;
int n;
bool st[N];//判重数组
bool backup[N];//判重备份数组
int ans;//用全局变量来记录答案的方案数
bool check(int a, int c)//判断a和c是否是满足要求的
{
//1.先要把b求出来
//2.接下来把b里面每一位数字抠出来,看看有没有和a、c相同的数字
//3.然后判断一下将a的数字,b的数字,c的数字加在一块是不是恰好是1~9出现了一次
long long b = n * (long long)c - a * c;//先把b求出来
if (!a || !b || !c) return false; //判断边界:a和b和c都不能是0
memcpy(backup, st, sizeof st);//把st数组拷贝到backup数组中,因为会对backup做修改,而st需要保证原样恢复现场,所以弄一个备份,直接修改backup
while (b)//从前往后扣掉b的每一位
{
int x = b % 10; // 取个位
b /= 10; // 个位删掉
if (!x || backup[x]) return false;//判断x是否是0 或者x之前是否已经在a或c中出现过
backup[x] = true;//否则的话,标记一下,相当于x已经用过了
}
for (int i = 1; i <= 9; i ++ ) //判断1~9每个数是否都出现过
if (!backup[i])
return false;
return true;
}
void dfs_c(int u, int a, int c)
{
if (u > 9) return;
if (check(a, c)) ans ++ ;//check就是用来判断a和c是否是满足要求的
//如果满足,ans++;否则就继续从1~9枚举
for (int i = 1; i <= 9; i ++ )
if (!st[i]) //如果当前数组没有用过的话就把他接到c的后面
{
st[i] = true;
dfs_c(u + 1, a, c * 10 + i);//a不变,c后面加上一个i
st[i] = false;
}
}
void dfs_a(int u, int a) //u表示当前已经用了多少个数字,a就是a
{
if (a >= n) return; //剪枝:如果a>=n,b、c为空
if (a) dfs_c(u, a, 0); //如果a是正确的,就枚举c,把u和a传进去,第三个0是当前c的值(起点)
for (int i = 1; i <= 9; i ++ )//当前这一位可以用哪个数字,应该是从1~9循环
if (!st[i]) //如果没有被用过
{
st[i] = true; //标记当前这一层已经被用过了
dfs_a(u + 1, a * 10 + i); //递归到下一层,同时更新一下a
//如何把一个序列变成数字? a * 10 + i,*10是把当前这位往前移一位,+i是加到个位
st[i] = false; //恢复现场
}
}
int main()
{
cin >> n;
dfs_a(0, 0); //第一个0表示当前已经用了多少个数字
//第二个0表示a是多少
cout << ans << endl;
return 0;
}
/*
主要注意两个细节:
1.如何在某一个数后面加上一位? a * 10 + i
2.如何把某一个数的每一位扣出来?
while(b)//从前往后扣掉b的每一位 ,当b>0的时候
{
int x = b % 10; // 取个位
b /= 10; // 个位删掉
}
*/
DFS递归解题思路总结
第一步,递归(或者是DFS)最重要的是顺序,要想一个顺序能把所有方案不重不漏的找出来。
可以根据题目样例手推一遍所有方案,找到几个样例正确的顺序。
例:

第二步,要想如何把普通的答案顺序转换为递归搜索树的顺序
因为所有递归都可以用递归搜索树结构分析表示,都可以转化成一颗递归搜索树
递归搜索树一般有三种模式:
①递归实现指数型枚举:每次两个分支选或者不选(从1~n依次考虑每个数选或不选)
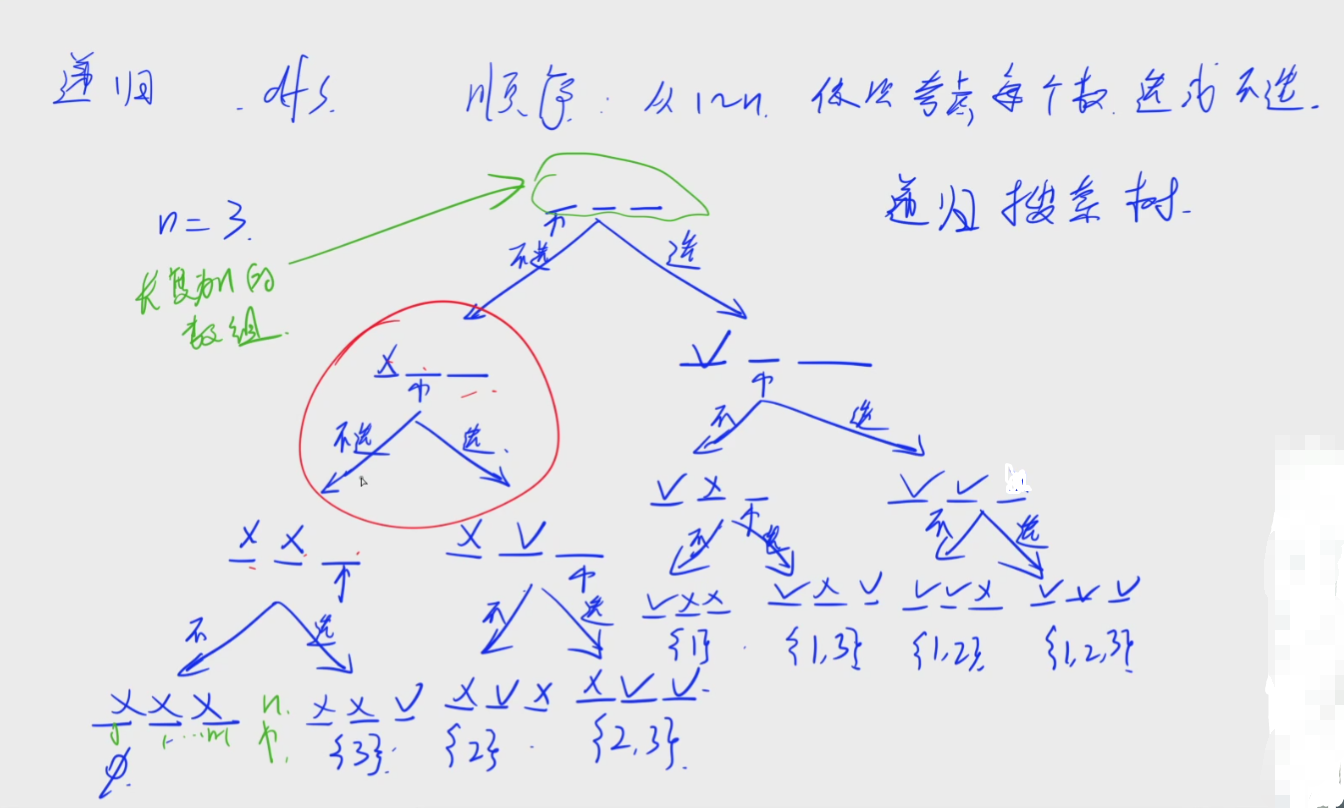
②递归实现排列型枚举:考虑顺序的所有枚举方案(依次枚举每个位置放哪个数)
③递归实现组合型枚举:不考虑顺序所有枚举方案。(依次枚举每个位置放哪个数,并且保证下一个数永远>上一个数)
第三步,要想如何把搜索树的形式转换为dfs代码
转换为代码的核心是考虑dfs()参数(也可以叫状态)有哪些?
注意参数有两种形式:
①全局变量:可以写成全局变量,不一定非得写成dfs()函数中真正的参数去
②函数形参:作为( )内的形参传入
三种搜索模式的参数状态:
/*
三种搜索模式的参数状态:
(1)递归实现指数型枚举
①全局变量int st[N]; //定义一个数组表示状态,记录每个位置当前的状态:0表示还没考虑,1表示选它,2表示不选它
//注意变量如果定义成全局变量的话,初值会自动赋成0,如果定义成随机变量的话,初值是一个随机值
②形参int u //u表示当前枚举第几位
(2)递归实现排列型枚举
①int state[N]; // 该状态是用来表示顺序2,枚举哪个位置放了哪个数。用st[]表示当前的状态:0 表示还没放数,1~n表示放了哪个数
//与递归实现指数型枚举的区别:
②bool used[N]; //判重数组,该状态是因为排列要保证搜索时每个数只能搜一次,所以新增了used数组来标记使用情况。
// true表示用过,false表示还未用过
③形参int u //u表示当前枚举第几位
(3)递归实现组合型枚举
①全局变量int way[N];//表示方案
②形参int u//u表示当前枚举第几位 ,该枚举哪个位置
③形参int start//当前最小可以从哪个数开始枚举:因为要保证升序选择(每个数在枚举的时候一定要比前一个数大),传一个start表示从哪个位置开始枚举
组合与排列参数的区别:
组合比排列的函数形参多了一个:start用来保证升序选择
但组合比排列的数组少了一个:排列里面需要加一个判重数组st[ ],因为它不知道每个数有没有用过,而组合不需要用到判重数组,因为每次枚举的时候保证了下一个数永远比上一个数大。比上一个数大的话一定比前面所有数都大,因此当前出现的数一定在前面都没出现过,所以判重数组在组合中是可以忽略的。
*/
第四步,根据模板写出dfs代码,如果时间超时或过大考虑剪枝优化
/*
递归(DfS)模板总结:
bool state[]; //定义一个数组表示状态,记录每个位置当前的状态,根据具体题目来看要定义几个参数状态数组
//也可以定义成int型,根据需求来
//这是所说的状态就是深搜时的顺序,状态就是如何把顺序表示出来,有几种状态表示顺序就开几个状态数组
void dfs(int step) //step表示当前枚举第几位
{
剪枝优化
{
return;
}
第一步:判断边界if()
{
(1)相应操作
//一般是输出方案等操作,注意输出格式
(2)return;
//注意:1.void型函数不能return一个值,但是如果只是return;表示当前这一层函数到此终止。
//2.return会结束当前这层递归,返回上一层递归去,u也会变为上一层的值
}
第二步:枚举分支:尝试每一种可能
{
前提:满足某一个check条件
(1)标记:表示当前所在的节点位置处于哪种状态(更新状态)
(2)继续下一步dfs(step+1):递归到下一个位置
(3)恢复现场 :节点有几个状态表示数组就恢复几个。原因:回溯时要用到,即把变之后的状态恢复成变之前的状态,因为不能让儿子影响决策,要做一个公平的父节点,所以怎么变过去的就要怎么变回来
}
}
int main()
{
dfs(递归起点,state) //dfs(1,state),dfs中传递的是当前枚举到第几位
//一开始是写起点,从1开始,那就是1~n,也可以是0~n-1
//st如果定义的是全局数组,就不用传进去了,直接在函数中使用修改即可
//根据具体题目来看要定义几个函数形参
}
*/
CSDN链接: https://blog.csdn.net/qq_46009744/article/details/122811777?spm=1001.2014.3001.5501

厉害厉害!