
(1)区间选点
给定 N 个闭区间 [ai,bi],请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点。
输出选择的点的最小数量。
位于区间端点上的点也算作区间内。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示所需的点的最小数量。
数据范围
1≤N≤105,
−109≤ai≤bi≤109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
代码
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e5+10;
struct Range
{
int l,r;
bool operator <(const Range &W)const
{
return r<W.r;
}
}range[N];
int n;
int main()
{
cin>>n;
for(int i=0;i<n;i++)
{
scanf("%d%d",&range[i].l,&range[i].r);
}
sort(range,range+n);
int res=0;
int std=-2e9;
for(int i=0;i<n;i++)
{
if(range[i].l>std)
{
res++;
std=range[i].r;
}
}
cout<<res;
return 0;
}
(1.1)雷达设备
假设海岸是一条无限长的直线,陆地位于海岸的一侧,海洋位于另外一侧。
每个小岛都位于海洋一侧的某个点上。
雷达装置均位于海岸线上,且雷达的监测范围为 d,当小岛与某雷达的距离不超过 d 时,该小岛可以被雷达覆盖。
我们使用笛卡尔坐标系,定义海岸线为 x 轴,海的一侧在 x 轴上方,陆地一侧在 x 轴下方。
现在给出每个小岛的具体坐标以及雷达的检测范围,请你求出能够使所有小岛都被雷达覆盖所需的最小雷达数目。
输入格式
第一行输入两个整数 n 和 d,分别代表小岛数目和雷达检测范围。
接下来 n 行,每行输入两个整数,分别代表小岛的 x,y 轴坐标。
同一行数据之间用空格隔开。
输出格式
输出一个整数,代表所需的最小雷达数目,若没有解决方案则所需数目输出 −1。
数据范围
1≤n≤1000,
−1000≤x,y≤1000
输入样例:
3 2
1 2
-3 1
2 1
输出样例:
2

代码
#include<iostream>
#include<algorithm>
#include<cmath>
using namespace std;
const int N = 1010;
struct Range
{
double l,r;
bool operator<(const Range &W)const
{
return r<W.r;
}
}range[N];
int n,d;
int main()
{
cin>>n>>d;
bool flag=true;
for(int i=0;i<n;i++)
{
int x,y;
cin>>x>>y;
if(y>d)flag=false;
else
{
double len=sqrt(d*d-y*y);
range[i].l=x-len;
range[i].r=x+len;
}
}
sort(range,range+n);
if(!flag)
{
cout<<-1;
return 0;
}
int res=0;
double std=-1e5;
for(int i=0;i<n;i++)
{
if(range[i].l>std)
{
res++;
std=range[i].r;
}
}
cout<<res;
return 0;
}
(2)最大不相交区间数量
给定 N 个闭区间 [ai,bi],请你在数轴上选择若干区间,使得选中的区间之间互不相交(包括端点)。
输出可选取区间的最大数量。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示可选取区间的最大数量。
数据范围
1≤N≤105,
−109≤ai≤bi≤109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
代码
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e5+10;
struct Range
{
int l,r;
bool operator <(const Range &W)const
{
return r<W.r;
}
}range[N];
int n;
int main()
{
cin>>n;
for(int i=0;i<n;i++)
{
scanf("%d%d",&range[i].l,&range[i].r);
}
sort(range,range+n);
int res=0;
int std=-2e9;
for(int i=0;i<n;i++)
{
if(range[i].l>std)
{
res++;
std=range[i].r;
}
}
cout<<res;
return 0;
}
(3)区间分组
给定 N 个闭区间 [ai,bi],请你将这些区间分成若干组,使得每组内部的区间两两之间(包括端点)没有交集,并使得组数尽可能小。
输出最小组数。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示最小组数。
数据范围
1≤N≤105,
−109≤ai≤bi≤109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
代码
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100010;
int n;
struct Range
{
int l, r;
bool operator< (const Range &W)const
{
return l < W.l;
}
}range[N];
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ )
{
int l, r;
scanf("%d%d", &l, &r);
range[i] = {l, r};
}
sort(range, range + n);
priority_queue<int, vector<int>, greater<int>> heap;
for (int i = 0; i < n; i ++ )
{
auto r = range[i];
if (heap.empty() || heap.top() >= r.l) heap.push(r.r);
else
{
heap.pop();
heap.push(r.r);
}
}
printf("%d\n", heap.size());
return 0;
}
(4)区间覆盖
给定 N 个闭区间 [ai,bi] 以及一个线段区间 [s,t],请你选择尽量少的区间,将指定线段区间完全覆盖。
输出最少区间数,如果无法完全覆盖则输出 −1。
输入格式
第一行包含两个整数 s 和 t,表示给定线段区间的两个端点。
第二行包含整数 N,表示给定区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示所需最少区间数。
如果无解,则输出 −1。
数据范围
1≤N≤105,
−109≤ai≤bi≤109,
−109≤s≤t≤109
输入样例:
1 5
3
-1 3
2 4
3 5
代码
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n;
struct Range
{
int l, r;
bool operator< (const Range &W)const
{
return l < W.l;
}
}range[N];
int main()
{
int st, ed;
scanf("%d%d", &st, &ed);
scanf("%d", &n);
for (int i = 0; i < n; i ++ )
{
int l, r;
scanf("%d%d", &l, &r);
range[i] = {l, r};
}
sort(range, range + n);
int res = 0;
bool success = false;
for (int i = 0; i < n; i ++ )
{
int j = i, r = -2e9;
while (j < n && range[j].l <= st)
{
r = max(r, range[j].r); //找出能覆盖到起点且终点最大的一个区间
j ++ ;
}
if (r < st)
{
res = -1;
break;
}
res ++ ;
if (r >= ed)
{
success = true;
break;
}
st = r;
i = j - 1;
}
if (!success) res = -1;
printf("%d\n", res);
return 0;
}
(5)合并果子
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 n−1 次合并之后,就只剩下一堆了。
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使达达耗费的体力最少,并输出这个最小的体力耗费值。
例如有 3 种果子,数目依次为 1,2,9。
可以先将 1、2 堆合并,新堆数目为 3,耗费体力为 3。
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12,耗费体力为 12。
所以达达总共耗费体力=3+12=15。
可以证明 15 为最小的体力耗费值。
输入格式
输入包括两行,第一行是一个整数 n,表示果子的种类数。
第二行包含 n 个整数,用空格分隔,第 i 个整数 ai 是第 i 种果子的数目。
输出格式
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 231。
数据范围
1≤n≤10000,
1≤ai≤20000
输入样例:
3
1 2 9
输出样例:
15
代码
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
int main()
{
int n;
scanf("%d", &n);
priority_queue<int, vector<int>, greater<int>> heap;
while (n -- )
{
int x;
scanf("%d", &x);
heap.push(x);
}
int res = 0;
while (heap.size() > 1)
{
int a = heap.top(); heap.pop();
int b = heap.top(); heap.pop();
res += a + b;
heap.push(a + b);
}
printf("%d\n", res);
return 0;
}
(6)排队打水
有 n 个人排队到 1 个水龙头处打水,第 i 个人装满水桶所需的时间是 ti,请问如何安排他们的打水顺序才能使所有人的等待时间之和最小?
输入格式
第一行包含整数 n。
第二行包含 n 个整数,其中第 i 个整数表示第 i 个人装满水桶所花费的时间 ti。
输出格式
输出一个整数,表示最小的等待时间之和。
数据范围
1≤n≤105,
1≤ti≤104
输入样例:
7
3 6 1 4 2 5 7
输出样例:
56
代码
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 100010;
int n;
int t[N];
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &t[i]);
sort(t, t + n);
reverse(t, t + n);
LL res = 0;
for (int i = 0; i < n; i ++ ) res += t[i] * i;
printf("%lld\n", res);
return 0;
}
(7)货仓选址
在一条数轴上有 N 家商店,它们的坐标分别为 A1∼AN。
现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。
为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小。
输入格式
第一行输入整数 N。
第二行 N 个整数 A1∼AN。
输出格式
输出一个整数,表示距离之和的最小值。
数据范围
1≤N≤100000,
0≤Ai≤40000
输入样例:
4
6 2 9 1
输出样例:
12
代码
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n;
int q[N];
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &q[i]);
sort(q, q + n);
int res = 0;
for (int i = 0; i < n; i ++ ) res += abs(q[i] - q[n / 2]);
printf("%d\n", res);
return 0;
}
(8)付账问题
几个人一起出去吃饭是常有的事。
但在结帐的时候,常常会出现一些争执。
现在有 n 个人出去吃饭,他们总共消费了 S 元。
其中第 i 个人带了 ai 元。
幸运的是,所有人带的钱的总数是足够付账的,但现在问题来了:每个人分别要出多少钱呢?
为了公平起见,我们希望在总付钱量恰好为 S 的前提下,最后每个人付的钱的标准差最小。
这里我们约定,每个人支付的钱数可以是任意非负实数,即可以不是 1 分钱的整数倍。
你需要输出最小的标准差是多少。
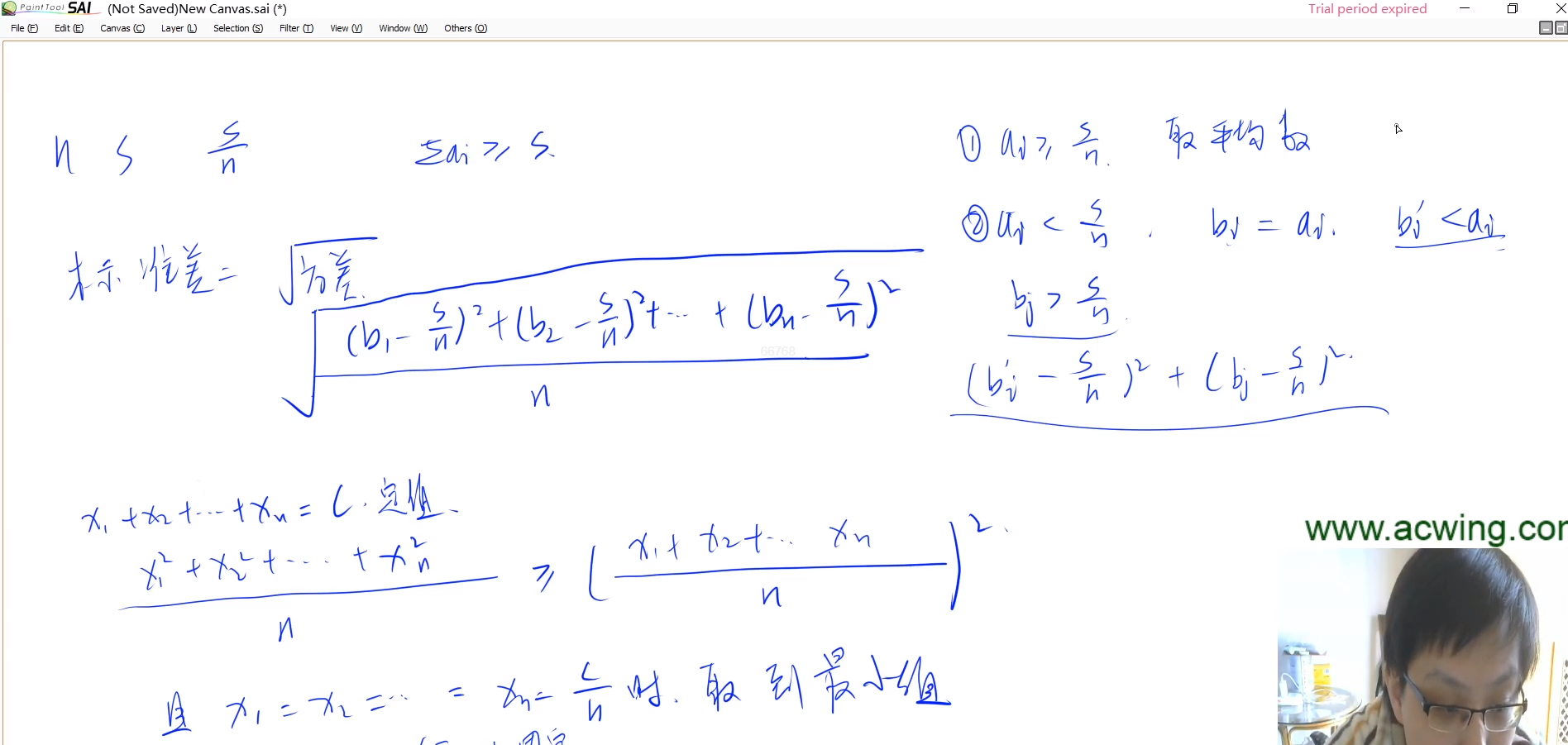
标准差的介绍:标准差是多个数与它们平均数差值的平方平均数,一般用于刻画这些数之间的“偏差有多大”。
形式化地说,设第 i 个人付的钱为 bi 元,那么标准差为 :
p1.png
输入格式
第一行包含两个整数 n、S;
第二行包含 n 个非负整数 a1, …, an。
输出格式
输出最小的标准差,四舍五入保留 4 位小数。
数据范围
1≤n≤5×105,
0≤ai,S≤109
输入样例1:
5 2333
666 666 666 666 666
输出样例1:
0.0000
输入样例2:
10 30
2 1 4 7 4 8 3 6 4 7
输出样例2:
0.7928
总结:两个数的和一定,差越小,平方和越小
代码
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 500010;
int n;
int a[N];
int main()
{
long double s;
cin >> n >> s;
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
sort(a, a + n);
long double res = 0, avg = s / n;
for (int i = 0; i < n; i ++ )
{
double cur = s / (n - i);
if (a[i] < cur) cur = a[i];
res += (cur - avg) * (cur - avg);
s -= cur;
}
printf("%.4Lf\n", sqrt(res / n));
return 0;
}
(9)耍杂技的牛
农民约翰的 N 头奶牛(编号为 1..N)计划逃跑并加入马戏团,为此它们决定练习表演杂技。
奶牛们不是非常有创意,只提出了一个杂技表演:
叠罗汉,表演时,奶牛们站在彼此的身上,形成一个高高的垂直堆叠。
奶牛们正在试图找到自己在这个堆叠中应该所处的位置顺序。
这 N 头奶牛中的每一头都有着自己的重量 Wi 以及自己的强壮程度 Si。
一头牛支撑不住的可能性取决于它头上所有牛的总重量(不包括它自己)减去它的身体强壮程度的值,现在称该数值为风险值,风险值越大,这只牛撑不住的可能性越高。
您的任务是确定奶牛的排序,使得所有奶牛的风险值中的最大值尽可能的小。
输入格式
第一行输入整数 N,表示奶牛数量。
接下来 N 行,每行输入两个整数,表示牛的重量和强壮程度,第 i 行表示第 i 头牛的重量 Wi 以及它的强壮程度 Si。
输出格式
输出一个整数,表示最大风险值的最小可能值。
数据范围
1≤N≤50000,
1≤Wi≤10,000,
1≤Si≤1,000,000,000
输入样例:
3
10 3
2 5
3 3
输出样例:
2
代码
#include <iostream>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 50010;
int n;
PII cow[N];
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ )
{
int s, w;
scanf("%d%d", &w, &s);
cow[i] = {w + s, w};
}
sort(cow, cow + n);
int res = -2e9, sum = 0;
for (int i = 0; i < n; i ++ )
{
int s = cow[i].first - cow[i].second, w = cow[i].second;
res = max(res, sum - s);
sum += w;
}
printf("%d\n", res);
return 0;
}
