
Code Opitimizing
编写程序的目标
写程序的主要目标/前提是在所有可能的情况下都正确工作. 程序员必须写出清晰简洁的代码, 为了
方便日后自己和其他人检查和修改代码. 另一方面程序运行速度也是一个重要的考虑因素.
编写高效程序的技术
-
选择一组适当的算法和数据结构.(做算法题时的必备技术)
-
编写编译器能够有效优化以转换为高效可执行代码的源代码. 为此理解优化编译器的能力和局限性是很
重要的. -
针对处理运算量特别大的计算: 将一个任务分成多个部分, 这些部分可以在多核和多处理器的某种组合
上并行计算, 这部分将在12章详细介绍.
在程序编写和优化的过程, 我们必须考虑代码的使用方式以及影响它的关键因素. 通常, 程序员需要
在实现和维护程序的简单性和它的运行速度之间做出权衡(trade-off).
理想情况下, 编译器能够接受我们编写的任何代码, 并产生尽可能高效的、具有指定行为的机器级程序.
现代编译器采用了复杂的分析和优化形式, 但即使最好的编译器也收到妨碍优化的因素
(optimizition blocker)的阻碍. 程序员得必须编写编译器容易优化的代码.

程序优化的步骤
- 1 消除不必要的工作, 包括消除不必要的函数调用、条件测试和内存引用. 这些优化不依赖于具体的机器.
为使程序性能最大化, 程序员和编译器需要一个目标机器的模型(具体的机器及其属性), 指明如何处理属性,
以及各个操作的时序性.
- 2 了解了处理器的运作, 我们可以进行优化的第二步: 利用处理器提供的指令级并行(
instruction-levelparallelism)能力, 同时执行多条指令.
代码优化是一个复杂的过程, 需要相当多的试错法试验(各种技术的变形和组合). 而研究
程序的汇编代码是理解编译器及其产生的代码会如何运行的最有效的手段之一.
5.1 优化编译器的能力和局限性 Capabilities and Limitations of Optimizing Compilers
优化编译器的能力
现代编译器会运用复杂精细的算法确认一个程序中计算的是什么值, 以及它们是如何被使用的, 接着利用一些
方法来简化表达式: 在不同的地方使用同一个计算, 降低一个给定的计算必须执行的次数等.
大多数编译器, 包括gcc, 向用户提供了一些对它们所使用的优化的控制. 最简单的控制就是指定 优化级别:
-Og使用基本优化, -O1或更高(如-O2, -O3)调用gcc会让它使用更大量的优化. 这样做可以进一步
提高程序性能, 但同时可能会增加程序的规模, 也可能使标准的调试工具更难对程序进行调试.
本书主要考虑以优化级别-O1编译出的代码.

编译器的局限性/保守的编译器
When in doult, the compiler must be conservative. (编译器总有一种优化方案: 不做任何优化.)
编译器必须很小心地对程序只使用安全的优化 : 对于程序可能遇到的所有可能的情况, 在C语言标准提供
的保证之下, 优化后得到的程序和未优化的版本有一样的行为。 这意味着程序员需要考虑编译器能够将之
转换为有效的机器代码的程序.
为理解决定一种程序转换是否安全的难度, 观察下面两个过程:
void twiddle1(long *xp, long *yp)
{
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp)
{
*xp += 2 * *yp;
}
乍一看这两个函数有着一样的行为 : 将存储在由指针yp指示的位置处的值2次加到指针xp指示
的位置处的值. 且twiddle2效率更高, 只要求两次内存引用(读*xp, 读*yp, 写*xp); 而twiddle1
要求读6次(2次读*xp, 2次读*yp, 2次写*xp). 因此编译器应该可以将twiddle1安全的优化为
twiddle2的代码, 然而考虑调用
twiddle1(&x, &x)
即*xp等于*yp的情况, 此时twiddle1执行
*xp += *xp; //double value at xp
*xp += *xp; //double value at xp
结果是xp指向的值变为原来的4倍, 而twiddle2执行
*xp += 2 * *xp; //triple value at xp
结果是xp指向的值变为原来的3倍.
编译器不知道twiddle1会被如何调用, 它必须假设参数xp和yp可能相等的情况, 因此不能产生twiddle2
风格的代码作为twiddle1的优化版本.
这种两个指针可能指向同一内存位置的情况被称为内存别名使用(memory aliasing). 在只执行安全优化中,
保守的编译器必须假设内存别名使用的情况可能发生. 再看一个内存别名使用的例子
内存别名使用 memory aliasing
x = 1000; y = 3000;
*q = y; //3000
*p = x; //1000
t1 = *q; //1000 or 3000 ?
t1的值取决于q和p是否指向同一位置, 若是: t1 = 1000; 否: t1 = 3000.

内存别名引用限制了编译器的优化, 被称为 妨碍优化的因素(opimiziing blockers). 另一个妨碍优化的因素
是函数调用(procedure calls), 考虑下面两个函数 :
long f();
long fun1()
{
return f() + f() + f() + f();
}
long fun2()
{
return 4 * f();
}
fun1和fun2好像执行相同的结果, 且fun2更高效. 但考虑下面f的代码
long counter = 0; //global variable 全局变量counter
long f()
{
return counter ++;
}
函数有一个副作用(side effects–影响除该过程外其他部分的状态)–修改了全局程序状态的一部分,
改变调用它的次数会改变程序的行为. 若counter设置为0, 对fun1的调用会返回0 + 1 + 2 + 3 = 6;
对fun2的调用会返回4 * 0 = 0.
大多数编译器不会试图判断一个函数是否有副作用, 所以编译器会保守的保持所有函数调用不变.
5.2 表示程序的性能 Expressing Program Performance
本书引入度量标准每周期的元素数(Cycles Per Element,CPE)作为一种表示程序性能
并指导我们改进代码的方法. CPE这种度量标准帮助我们在更细节的级别上理解迭代程序的循环性能.
这样的度量标准对执行重复计算的程序来说是很适当的, 例如处理图像中的像素或计算矩阵乘积中的元素.
CPU的活动顺序是由时钟控制的, 始终提供了某个频率的规律信号, 通常用千兆兹(GHz)表示.
时钟周期度量的是每秒执行操作的次数, 从程序员的角度来看相比用时间度量更有作用. 因为我们
不能控制程序执行的时间, 但可以控制程序执行的操作次数.
例 前缀和
用两个计算数组a的前缀和(prefix sum)的函数为例
//Compute prefix sum of vector a
void psum1(float a[], float p[], long n)
{
long i;
p[0] = a[0];
for( i = 1; i < n; i ++ )
p[i] = p[i - 1] + a[i];
}
void psum2(float a[], float p[], long n)
{
long i;
p[0] = a[0];
for( i = 1; i < n - 1; i += 2 )
{
float mid_val = p[i - 1] + a[i];
p[i] = mid_val;
p[i + 1] = mid_val + a[i + 1];
}
//对奇数n, 计算最后一个元素
if( i < n )
p[i] = p[i - 1] + a[i];
}
psum1每次计算1个元素的前缀和, psum2使用循环展开(loop unrolling)计数, 每次迭代计算2个元素.
(之后会探讨循环展开的好处).
这个过程所需要的时间可以用一个一次函数表示c+k∗n
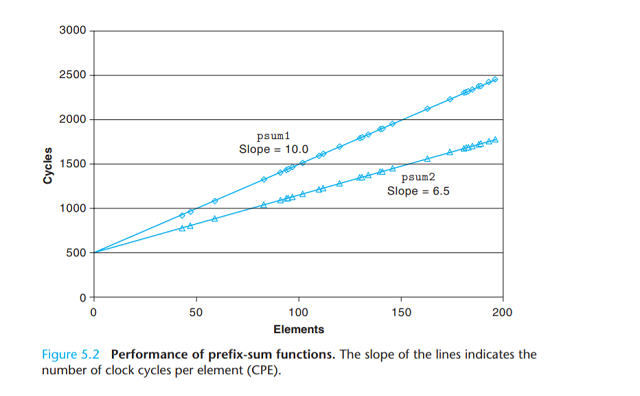
上图是两个函数需要的时钟周期和关于n的取值范围图, 使用 最小二乘拟合 (least squares fit
一种拟合方式)我们发现psum1和psum2的运行时间(以时间周期为单位)分别近似368+9.0n和368+6.0n. 等式表明对代码记时和初始化过程、准备循环(前面对应n为0时需要的耗时)以及完成循环过程
的开销为368个周期加上每个元素乘上6.0或9.0周期的线性因子, 这个因子即每个元素的周期数(CPE).
这里我们更愿意用每个元素的周期数而不是每次循环的周期数来度量, 因为如循环展开的计数会使得循环次数减少.
psum2的CPE为6.0, 优于CPE为9.0的psum1.
5.3 程序示例
为说明一个抽象的程序是如何被系统地转换成更有效代码的, 我们使用基于下图的向量数据结构的运行示例.
向量由两个内存块表示: 头部和数据数组.
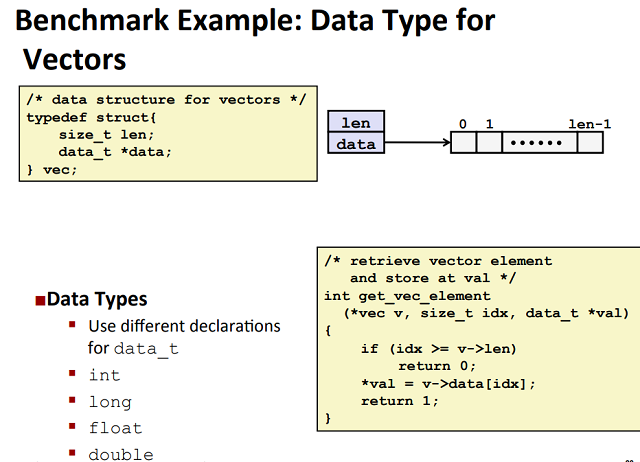
声明中用dada_t表示基本元素的数据类型. 在测试中我们会度量代码对整型(int&long)和浮点数
(float&double)数据的性能. 比如对long数据类型 :
typedef long data_t;
我们会分配len个data_t类型对象的数组, 存放实际的向量元素.
下面给出生成向量、访问向量元素以及确定向量长度的基本过程. 一个值得注意的特性是向量访问函数
get_vec_element, 它会对每个向量引用进行边界检查, 这类似很多其他语言(如Java)所使用的数组表示法.
边界检查降低了程序出错的机会, 但也会减缓程序的执行.
typedef struct vec* vec_ptr;
//Create vector of specified length 构造特定长度的向量
vec_ptr new_vec(long len)
{
//Allocate header structure 为作为头部的数据结构vec分配内存
vec_ptr result = (vec_ptr) malloc( sizeof(vec) );
data_t *data = NULL;
if( !result )
return NULL; //Couldn't allocate storage
result->len = len;
//Allocate array
if( len > 0 )
{
data = (data_t *)calloc(len, sizeof(data_t));
if( !data )
{
free((void *)result);
return NULL; //Could't allocate storage
}
}
result->data = data;
return result;
}
/*
* Retrieve vector element ans store at dest
* Return 0 (out of bounds) or 1 (successful)
*/
int get_vec_element(vec_ptr v, long index, data_t *dest)
{
if( index < 0 || index >= v->len )
return 0;
*dest = v->data[index];
return 1;
}
//Return length of vector
long vec_length(vec_ptr v)
{
return v->len;
}
作为一个优化示例, 考虑下面的代码, 它使用某种运算将向量所有元素合并成一个值. 根据编译时IDENT
和OP的不同定义, 这段代码可以重编译成对数据执行不同的运算. 使用声明 :
#define IDENT 0
#define OP +
它对向量元素求和. 使用声明:
#define IDENT 1
#define OP *
它计算向量元素的乘积. 代码示例:
//Implementation with maximum use of data abstraction
void combine1(vec_ptr v, data_t *dest)
{
long i;
*dest = IDENT;
for( i = 0; i < vec_length(v); i ++ )
{
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
下面我们会对这段代码进行一系列的变化. 为评估性能变化, 本书在具有Intel Core i7 Haswell处理器的机器
上测试这些函数的CPE性能, 这个机器称为 参考机.
我们会进行一组变换, 有些只会带来很小的性能提高, 而其他的能带来巨大的效果. 确定应该使用哪些方法的组合
是编写快速代码的魔术black art. 最好的方法是实验加上分析: 反复尝试不同方法, 进行测量并检查汇编代码
表示以确定底层的性能瓶颈.
作为一个起点, 下表给出combine1的CPE度量值, 它运行在 参考机 上. 实验显示32位和64位的数据性能相同.
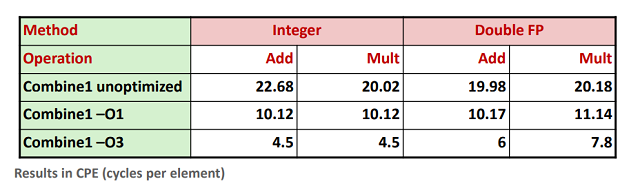
通过上表也能看出简单地使用命令选项-O1就会对程序性能提高不少. 在剩下的测试中, 我们使用-O1和-O2
级别的优化来生成和测量程序.
5.4 消除循环的低效率
code motion
combine1调用函数vec_length作为for循环的测试条件, 回想第三章如何将含有循环的代码翻译成机器级程序
的讨论(3.6.7节), 每次循环迭代时都必须对测试条件求值; 另一方面, 向量的长度不会随着循环的进行改变.
因此可以只计算一次向量长度, 在测试条件中都使用这个值.
//Mov call of vec_length out of loop
void combine2(vec_ptr v, data-t *dest)
{
long i;
long length = vec_length(v);
for( int i = 0; i < length; i ++ )
{
data_t val;
val = get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
combine2函数在循环前调用vec_length函数并赋值给局部变量length. 对于某些数据类型和操作,
这个变换明显影响了程序性能. 当然无论是否优化明显我们都需要这种变换来消除这部分的低效率,
因其可能成为进一步优化的瓶颈.

(不同版本的数字可能略有不同)
这个优化是一类常见优化的一个例子, 称为代码移动(code motion). 这类优化会包括识别要多次执行(如循环内)
但计算结果不会改变的计算, 可以将这类计算移动到多次执行前(有点类似于预处理). 优化编译器也会试着
进行代码移动, 但因为编译器无法可靠确定一个函数是否有副作用(side effects), 所以保守的编译器一般不会
做任何优化, 需要程序员帮助编译器显式地完成代码的移动.
code motion example
举一个combine1中看到的循环低效率的极端例子, 考虑将字符串中所有大写转换成小写字母的
lower1函数及它的优化版本lower2.
//Convert string to lowercase : slow
void lower1(char *s)
{
long i;
for( i = 0; i < strlen(s); i ++ )
{
if( s[i] >= 'A' && s[i] <= 'Z' )
s[i] -= ('A' - 'a');
}
}
//Convert string to lowercase : faster
void lower2(char *s)
{
long i;
long length = strlen(s);
for( i = 0; i < strlen(s); i ++ )
{
if( s[i] >= 'A' && s[i] <= 'Z' )
s[i] -= ('A' - 'a');
}
}
//Sample implementation of library function strlen 库函数strlen的一个简单实现版本
//Compute length of string
size_t strlen(const char *s)
{
long length = 0;
while( *s != '\0' )
{
s ++ ;
length ++ ;
}
return length;
}
lower1在n次循环每次都调用O(n)的strlen函数, 所以时间复杂度O(n2); 而优化版本的lower2时间
复杂度O(n).
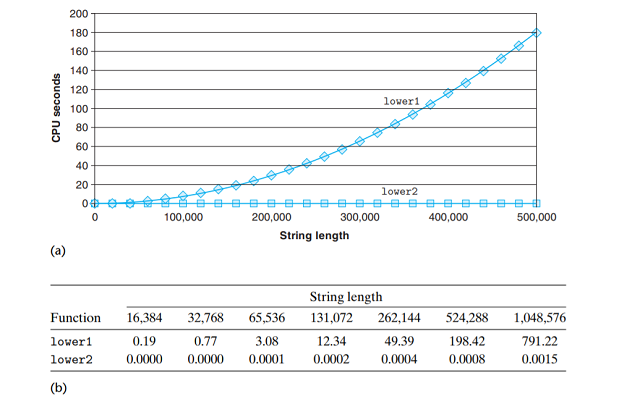
这个示例说明了一个编程中的常见问题, 一个看上去无足轻重的代码片段有着隐藏的渐近低效率
(asymptotic inefficiency). 在小数据集上lower1的表现和lower2相差无几, 但当过程应用在
一个有100万个字符的串上, 这段无危险的代码变成了一个主要的性能瓶颈. (提前做好时间复杂度分析)
5.5 减少调用过程 Reducing Procedure Calls
正如之前看到的, 过程调用会带来开销, 并妨碍大多数形式的代码优化. combine2的代码中每次循环
迭代都会调用get_vec_element获取向量元素, 每次对向量的引用前都会做边界判断. 在处理任意的数组
访问时, 边界检查会很有用, 但在combine2中明确每次引用都是合法的情况下这会带来低效率.
作为替代, 假设为我们的抽象数据类型增加一个函数get_vec_start, 函数返回数组的起始地址.
data_t *get_vec_start(vec_ptr v)
{
return v->data;
}
于是我们可以编写循环内没有函数调用而是直接访问数组的过程combine3 :
//Direct access to vector data
void combine3(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = IDENT;
for( i = 0; i < length; i ++ )
{
*dest = *dest OP data[i];
}
}
一个纯粹主义者可能会说这种变换损害了程序的模块性, 原则上说抽象数据类型的使用者不应该知道
其底层的实现. 比较实际的程序员会争论说这种变换是获得高性能结果的必要步骤.
令人吃惊的是, 性能并没有明显提升. 事实上, 整数求和的性能还略有下降. 显然是内循环中的其他
操作形成了瓶颈, 限制性能超过调用get_vec_element, 之后还会回到combine3(5.11.2节)看看为什么
反复的边界检查不会让性能更差. 现在我们可以将这个转换视为一系列步骤中的一步, 这些步骤最终
将产生显著的性能提升.
5.6 消除不必要的内存引用 Eliminating Unneeded Memory References
combine3将元素合并的运算结果累计在指针dest指向的内存位置. 下面是double数据类型合并运算
为乘法的x86-64代码 :
Inner loop of combine3. data_t = double, OP = *
dest in %rbx, data+i in %rdx, data+length in %rax
.L17 loop
vmovsd (%rdx), %xmm0 读取dest指向内存的值( %xmm系列寄存器用来存储浮点数 )
vmulsd ($rdx), %xmm0, %xmm0 将取出值与data[i]相乘
vmovsd %xmm0, (%rbx) 将结果存回dest
addq $8, %rdx data+i指向位置加1
cmp %rax, %rdx %rax存储data+length值作为循环结束的哨兵
jne .L17 data+i不等于data+length时循环继续
可以看到每次循环迭代都要对累计变量(dest指向的变量)进行读和写操作, 这样的读写很浪费, 因为每次迭代
开始是从dest读出的值就是上次迭代最后写入的值.
我们能够消除这种不必要的内存读写, 一种方法是引入临时变量, 用它来保存计算累计结果的值, 只有在循环
完成之后结果才存放在dest中, 具体实现 : combine4代码
Inner loop of combine4. data_t = double, OP = *
acc in %xmm0, data+i in %rdx, data+length in %rax acc作为临时变量, 存储在%xmm0中
.L25:
vmulsd (%rdx), %xmm0, %xmm0
addq $8, %rdx
cmpq %rax, %rdx
jne .L25
//Accumulate result in local variable
void combine4(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length( v );
data_t *data = get_vec_start( v );
data_t acc = IDENT;
for( i = 0; i < length; i ++ )
{
acc = acc OP data[i];
}
*dest = acc;
}
与combine3中的循环相比, 我们将每次迭代的内存操作从2次读和1次写 --> 1次读.
程序性能有了明显提高 :

可能有人回想编译器应该能自动将combine3的代码转换为将循环内累计值存储在寄存器中, 即转换为
combine4的形式. 然而由于内存别名使用(memory aliasing), 两个函数可能有不同的行为. 例如
整数数据, 运算为乘法, v=[2,3,5], 考虑下面的函数调用 :
combine3(v, get_vec_start(v) + 2 );
combine4(v, get_vec_start(v) + 2 ); //dest = (data + 2)
也就是在向量的最后一个元素和存放结果的目标之间创建一个别名. 函数执行结果如下 :
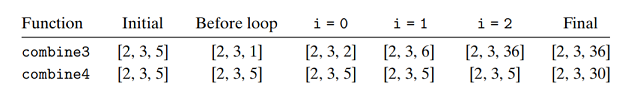
combine3将其结果存放在dest中, 在本例中dest指向向量最后一个元素. 因为这个值首先被设置为1, 然后
分别计算1∗2=2,2∗3=6,6∗6=36; 而对于combine4, 在循环过程中向量保持不变, 循环结束
后将局部变量的值2∗3∗6=30赋值给向量最后一个元素. 因此保守的编译器又会什么优化也不做…
5.7 理解现代处理器
到目前为止, 我们运用的优化只是简单的降低过程调用带来的开销, 消除一些重大的”妨碍优化因素”(optimizition blocker). 要想进一步提高性能, 我们需要理解现代处理器的 微体系结构 .
现代处理器越来越复杂, 处理器的实际操作与观察到的汇编代码大相径庭. 现代处理器取得的了不起的功绩之一 :
它们采用复杂而奇异的微处理器结构, 其中, 多条指令可以并行执行(instruction-level parallelism), 同时
又呈现出一种简单的顺序执行指令的表象(运行结果与顺序执行相同).
本书不会讨论微处理器的详细设计, 对微处理器的运行原则有一般性了解就足够能理解它们如何实现指令级并行.
我们会发现两种下界描述了程序的最大性能. 当一系列操作必须严格按照顺序执行时, 就会遇到延迟界限(latency bound) : 在下一条开始执行之前, 这条指令必须结束. 当代码中的数据相关限制了处理器利用指令级并行能力时, 延迟界限限制程序性能. 吞吐量界限(throughput bound)刻画了处理器功能单元的原始计算能力,
这个界限是程序性能的终极限制.
5.7.1 整体操作
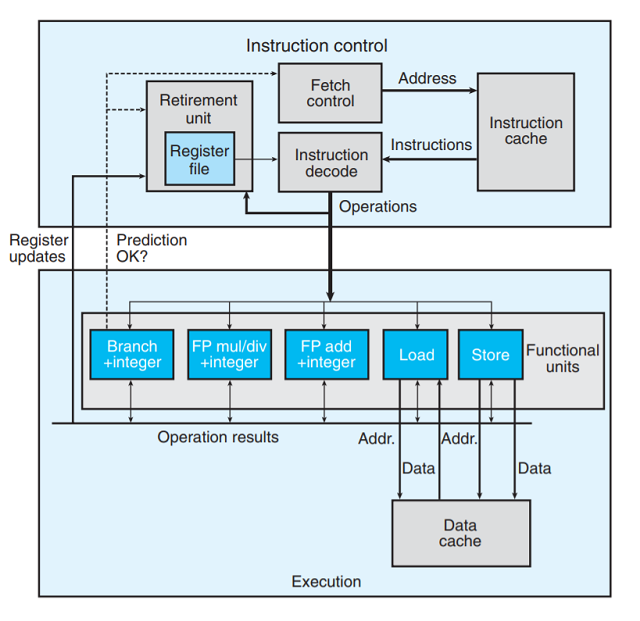
下图是现代处理器的一个非常简化的示意图. 这里假象的处理器设计是不太严格地基于Intel处理器的结构.
这些处理器被称为是 超标量的 (superscalar)—每个时钟周期可执行多个操作, 且是乱序的(out-of-order),
意思就是指令的执行顺序不一定要与它们在机器级程序中的顺序一致.
整体的设计分为两部分:
-
指令控制单元(
Instruction Control Unit, ICU), 负责从内存读出指令序列, 并根据这些指令序列生成
一组针对程序数据的基本操作. -
执行单元(
Execution Unit, EU), 执行ICU生成的操作.
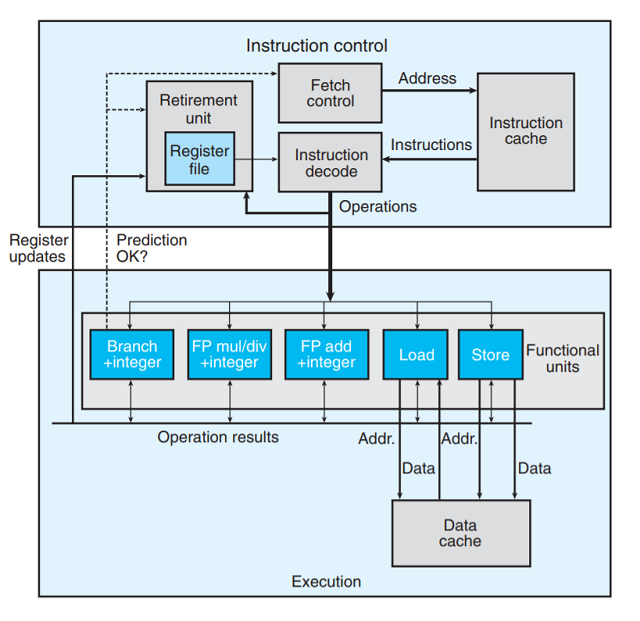
下面简单介绍处理器的各个部分:
- 指令高速缓存(
instruction cache): 特殊的高速存储器, 存储最近的指令,ICU就是从这里读取指令.
通常
ICU会在当前正在执行的指令很早之前取指, 以保证有足够的时间对指令译码, 并把生成的操作
发送给EU. 不过一个问题是当程序遇到分支(条件转移指令)时, 程序可能会进入分支也可能跳过分支.
现代处理器采用一种称为分支预测(branch prediction)的计数, 处理器会猜测是否选择分支, 同时
预测分支的目标地址. 采用投机执行speculative execution的计数, 处理器会开始取出它预测的分支
目标地址处取指令, 并对指令译码, 甚至在确定分支预测是否正确之前就开始执行这些操作. 如果过后
确定分支预测错误, 会将状态重新设置到分支点的状态, 并开始取出并执行另一个方向的指令.
-
取指控制(
fetch control): 包括上述的分支预测 -
指令译码(
instruction decode): 接受实际的程序指令, 并将它们转换成一组基本操作(有时称为微操作).
这样的操作完成一个简单的任务, 如加减、内存读写.
程序指令-->基本操作的示例
在典型的x86实现中, 一条只对寄存器的操作, 如:
addq %rax, %rbx
会被转化为一个操作. 而一条包含一个或多个内存引用的指令, 如:
addq %rax, 8(%rdx)
会产生多个操作, 把内存引用和算数运算分开. 这条指令会被分为3个操作: 从内存读; 将读入的值加上rax
中的值; 对内存写.
-
功能单元(
functional units):EU中的用于执行不同的来自ICU操作的单元. -
数据高速缓存(
data cache): 高速存储器, 存放最近访问的数据值. -
加载和存储单元(
load&store): 读写内存. 均有一个加法器用于计算地址. 通过数据高速缓存来访问内存.
使用投机执行技术对操作求值, 直到处理器能确定应该实际执行这些指令前, 其最终结果不会存储
在程序寄存器或内存中. 分支操作被送到EU, 用于确定分支是否预测正确. 如果预测错误,EU
会丢弃分支点之后计算的结果, 并发送信号给分支单元(branch)告诉预测时错误的. 就像在3,6,6
节看到的, 这样的预测错误会带来很大的性能开销.
功能单元
由上处理去框图可以看到不同的功能单元被设计执行不同操作. 随着单处理器芯片能够集成的晶体管数量
越来越多, 后续的微处理器型号都增加了功能单元的数量以及每个单元能执行的操作组合. 由于不同程序
间所要求的操作变化很大, 因此, 算法运算单元被特意设计称能够执行不同的操作.
举个例子, 我们的Intel Core i7 Haswell参考机有编号为0∼7的8个功能单元:
0: 整数运算、浮点乘、整数和浮点数除法、分支1: 整数运算、浮点加、整数乘、浮点乘2: 加载、地址计算3: 加载、地址计算4: 存储5: 整数运算6: 整数运算、分支7: 存储、地址计算
整数运算指基本操作, 如加法、位运算. 我们看到存储操作需要两个功能单元—一个计算存储地址, 一个
保存实际数据. 5.12节将介绍存储和加载的操作机制.
可以看到功能单元的这种组合具有同时执行多个同类型操作的潜力. 它有4个功能单元执行整数操作, 2个
单元执行加载操作, 2个单元执行浮点乘法. 稍后我们将看到同时执行同类型操作对程序获得最大性能的影响.
- 退役单元(
retirement unit): 记录正在进行的处理, 并确保它遵守机器级程序顺序的语义. 图中展示的
寄存器文件(register file), 包含整数、浮点数和最近的SSE和AVX寄存器, 是退役单元的一部分.
退役单元控制这些寄存器的更新.
指令译码时, 关于指令的信息会被放置在一个先进先出的队列中. 这些信息会一直保持在队列中, 直到
发生以下2个结果中的一个: 一条操作完成且所有引起这条指令的分支点都被确认预测正确, 那么这条
指令就可以退役了(retired), 所有对程序寄存器的更新可被实际执行; 另一个结果是如果引起该指令
的某个分支点预测错误, 这条指令就会被清空(flushed), 丢弃所有计算出的结果. 也就是指令执行完
后, 引起该指令的分支预测正确则更新寄存器, 否则丢弃计算结果. 这样预测错误就不会改变程序状态
了. 为加速一条指令到另一条指令的结果的传送, 许多此类信息是在执行单元之间交换的, 即图中的操作
结果. 如图中箭头所示, 执行单元可以直接将结果发送给彼此.
寄存器重命名 register renaming
5.7.2 功能单元的性能
下图提供了Intel Core i7 Haswell参考机的一些算术运算的性能, 这些时间对其他处理器来说也是具有
代表性的. 每个运算都是由以下这些数值刻画的:
-
延迟(
latency): 完成运算的总时间. -
发射时间(
issue time): 两个连续的同类型运算之间需要的最小周期数. -
容量(
capacity): 能够执行该运算的功能单元的数量

我们看到, 从整数运算到浮点运算, 延迟是增加的; 加法和乘法运算的发射时间都为1, 意思是每个
时钟周期都可以开始一条新的同类型的运算—这种很短的发射时间是由 流水线 实现的. 发射时间
为1的功能单元被称为 完全流水化的 (fully pipelined). 出现容量大于1的运算是由于有多个
功能单元, 例如前述参考机有4个功能单元执行整数操作.
我们还看到, 除法器(用于整数和浮点数除法, 以及浮点数平方根)不是完全流水化的—它的发射时间
等于它的延迟. 这就意味着对每个执行除法的功能单元, 必须执行完毕依次除法才能执行新的除法操作.
此外除法的延迟和发射时间是以范围∼给出的, 因为某些被除数和除数的组合比其他的组合需要
更多的步骤. 除法的长延迟和长发射时间表明其是一个开销很大的运算.
表示发射时间的一种更常见方法是指明这个功能单元的最大吞吐量—发射时间的倒数. 一个完全流水化
的功能单元具有最大的吞吐量. 具有多个功能单元可以提高吞吐量: 对一个容量为C, 发射时间为I的
操作来说, 处理器可能获得的吞吐量为C/I.(单个功能单元的吞吐量为1/I).
这种算术运算的延迟、发射时间和容量会影响合并函数的性能. 我们用CPE值的两个基本界限来描述
这种影响:

-
延迟界限(
latancy)—给出单个功能单元严格按照顺序完成运算的函数所花费的最小的CPE值. -
吞吐量界限(
throughput)—根据功能单元产生结果的最大速率, 给出CPE的最小界限.
例如, 对于单个整数加法器(中文版原书是乘法器, 目前我觉得可能是打印错误), 他的发射时间为1
个时钟周期, 处理器无法支持每个时钟周期大于1条乘法的速度. 另一方面, 4个功能单元都可以
执行整数加法, 处理器就有可能持续每周期执行4个操作的速率(CPE降为0.5); 然而因为需要读
内存, 这造成另一个吞吐量界限—2个加载单元限制了处理器每个时钟周期最大只能读取2个数据,
从而使得吞吐量界限只能降为0.5. 我们会展示延迟界限和吞吐量界限对合并函数不同版本的影响.
5.7.3 处理器操作的抽象模型
数据流图
- 程序的数据流(
data-flow)表示: 作为分析在现代处理器上执行的机器级程序性能的一个工具,
是一种图形化的表示方法, 展示不同的操作之间的数据相关是如何限制它们的执行顺序的.这些限制形成了图中的关键路径(
critical path), 这是执行一组机器指令所需时钟周期的下界.
在继续技术细节前, 回顾一下目前最快代码combine4的CPE测量值:

可以看到, 除了整数加法, 这些测量值与处理器延迟界限是一致的. 这不是巧合—它表明这些函数的
性能是由所执行的求和或者乘积计算主宰的.
1.从机器级代码到数据流图
程序的数据流表示是非正式的, 这里只是用它来形象描述程序中的数据联系是如何主宰程序性能的.
以combine4为例描述数据流表示法. 我们将注意力集中在循环执行的计算上, 因为对于大向量
来说, 这是决定性能的主要因素. 考虑类型double, 以整数乘法作为合并运算的情况, 不过其他
组合也有几乎一样的结构.
循环编译出的代码由4条指令组成, 寄存器%rdx存储数组第i个元素的指针, %rax存储数组
末尾指针, 而%xmm0存放累积值acc:
Inner loop of combine4, data_t = double, OP = *
acc in %xmm0, data+i in %rdx, data+length in %rax
.L25: loop:
vmulsd (%rdx), %xmm0, %xmm0 Multipy acc by acc[i]
addq $8, %rdx Increment data+i
cmpq %rax, %rdx Compare to data+length
jne .L25 if !=, goto loop
如下图所示, 在我们假想的处理器设计中, 指令译码器会把这4条指令扩展成为一系列的5个步骤,
其中最开始的乘法指令被扩展为一个load指令 — 从内存读出源操作数, 和一个mul指令 — 执行乘法.
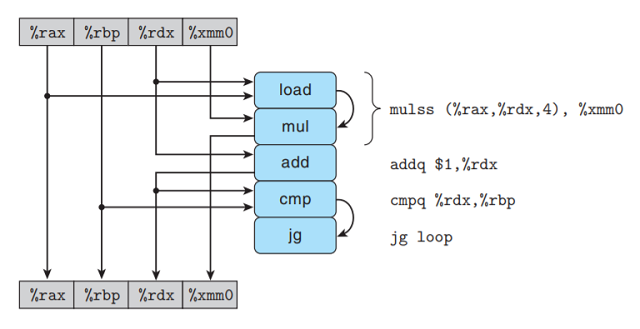
-
左边的方框和箭头给出了各个指令是如何使用和更新寄存器的, 顶部放开表示每次循环开始时寄存器的值,
而底部方框表示每次循环结束寄存器的值. 例如%rax仅作为cmp操作的源值, 它在循环过程中值未改变;
而rdx会被load和add操作使用, 其值会被add更新. -
某些操作产生的值不对应图中任何寄存器, 这在图右边操作间的弧线表示.
load操作从内存中读出一个值,
接着把它直接传送到mul操作 — 这两个操作通过对一条vmulsd操作产生, 所以两个操作间传递的中间
值没有与之相关的寄存器.cmp操作更新条件码,jne操作测试条件码, 其寄存器不对应图中寄存器.
对于上循环的代码片段, 可以将访问到的寄存器分为四类:
-
只读: 只作为源值, 在循环过程中不被修改, 如例子中的
%rax. -
只写: 只作为操作的目的值, 在例子中不存在这样的寄存器.
-
局部: 在循环中可被读写, 但在循环之间独立. 例如例子中的条件码寄存器, 此次条件码仅与
%rax和%rdx
相关, 与上一次迭代的条件码无关. -
循环: 在循环中可被读写 — 作为操作的源值和目的值. 一次迭代的值会在另一次迭代中用到(迭代相关).
例子中%rax与%xmm0是循环寄存器.
我们会看到, 循环寄存器之间的操作链(先后或并行)决定了限制性能的数据相关. 下面数据流图特别关注
循环寄存器的操作联系.
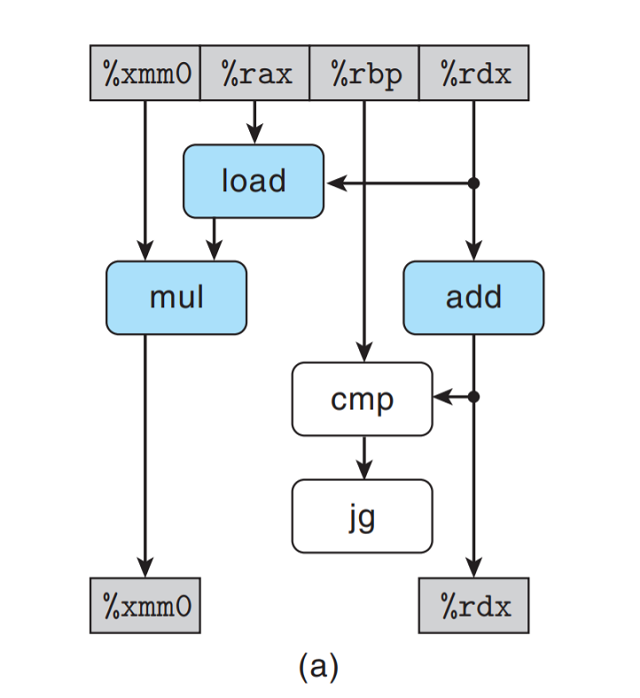
上图中, 将不属于循环寄存器操作链的操作符标识为白色. 进一步只关注与循环寄存器操作链相关的操作,
消除标识为白色的操作符, 且只保留循环寄存器.
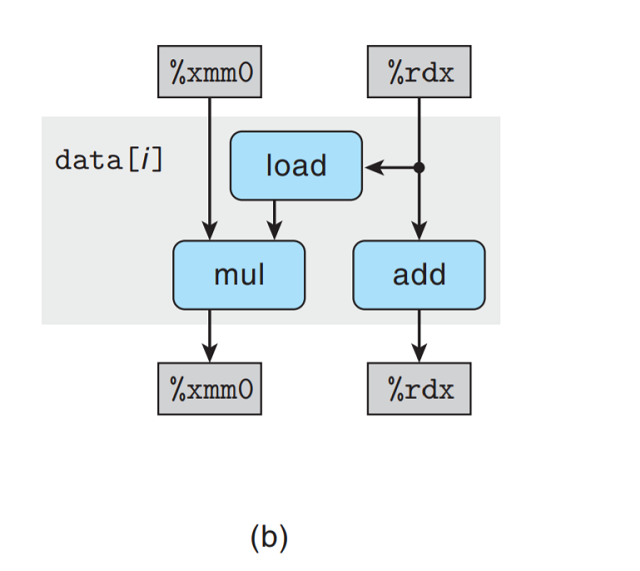
上图只剩下一个抽象模板, 表明循环一次迭代在循环寄存器中形成的数据相关.
上图表明从一次迭代到下一次迭代有两个数据相关. 在左边我们看到%xmm0存储的累积值acc的迭代
相关: 将旧acc乘以一个数组元素得到新acc, 这个数据元素由load得到; 在右边我们看到循环
索引i的迭代相关: 每次迭代中, load通过i的旧值读取元素, add操作更新索引值.
将每次迭代串联, 得到combine4内循环的n次迭代的数据流表示:
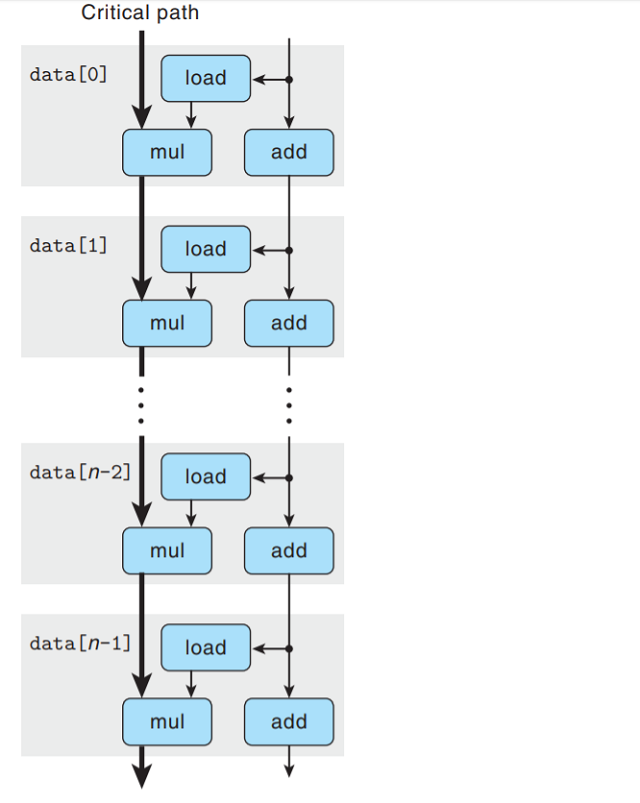
可以看到, 程序有两条数据相关链, 分别对应于mul操作 — 对acc修改和add操作 — 对data+i修改.
参考机的浮点乘法延迟(latency)为5个周期, 而整数加法延迟为1个周期, 所以左边mul操作成为关键
路径(critical path), 需要5×n个周期执行.
上图说明为何单精度浮点数乘法的CPE=5: 当执行combine4时, 浮点乘法器成为制约资源. 循环中需要的
其他操作 — 更新和测试指针值data+i, 以及从内存读取数据 — 与乘法器并行执行. 每次acc值被计算
后, 就作为旧值更新下一个acc, 不过每次需要等5个周期才能完成.
其他数据类型和运算组合的数据流与上图结构相同, 只是左边形成数据相关链的数据操作不同 — 操作的延迟
为L≥1, 则CPE=L.
2. 其他性能因素
另一方面, 对于整数加法, 对combine4的测试表明CPE=1.27, 而根据沿着数据流表示中的关键路径CPE
的预测值应为1.00, 实际测试值比预测值要慢.
这说明了一个原则: 数据流表示中的关键路径提供的只是程序所需周期数的下界.
还有一些其他因素会限制性能 — 包括可用单元数量和每步中功能单元之间能够传递数据值的数量. 对于合并
运算为整数加法的情况, 数据操作足够快, 使得其他因素成了制约时间的因素. 要准确知道为什么CPE=1.27,
需要获得比公开更详细的硬件信息.
看来, 顺序执行运算操作时延迟界限是基本限制. 接下来的任务是重新调整操作结构, 增加指令级 并行性 ,
使得越过延迟界限, 接近吞吐量界限.
5.8 循环展开 Loop unrolling
- 循环展开是一种程序变换, 通过增加每次迭代计算的数量, 减少迭代次数.
上面提到的
psum2就是这样的一个例子: 每次迭代计算两个前缀和, 因而将迭代次数减半.
循环展开能够从两个方面改进程序的性能:
-
减少了不直接有助于程序结果的操作数量, 例如循环索引计算和条件分支.
-
提供改变代码的方法, 减少整个计算中关键路径的操作数量.
本节中我们会看到一些简单的循环展开, 不做任何进一步变化.
k×1循环展开
combine5是合并代码使用2×1循环展开的版本:
//2 * 1 loop unrolling
void combine5(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1; //循环上界
data_t *data = get_vec_start(v); //数组指针
data_t acc = IDENT;
//Combine 2 elements at a time
for(i = 0; i < limit; i += 2)
{
acc = (acc OP data[i]) OP data[i + 1];
}
//Finish any remaining elements
for(; i < length; i ++ )
{//剩余元素
acc = acc OP data[i];
}
*dest = acc;
}
一般来说, 向量不一定是2的倍数. 为使得我们的代码对任意长度都能正确工作, 需注意2个方面:
- 确保第一次迭代不会越界: 对于长度为n的向量, 我们将循环界限设为n−1, 循环索引i<n−1.
将上述思想归纳为对一个循环按任意因子k展开, 即k×1循环展开, 此时上限为:
-
将循环上界设为n−k+1, 循环索引i<n−k+1. 每次处理k个元素, i=i+k.
-
确保将剩余0∼k−1个元素合并: 另外开一个循环, 每次合并一个元素.
k×1展开: 每次处理k个元素, 累积值只在单个变量acc中.
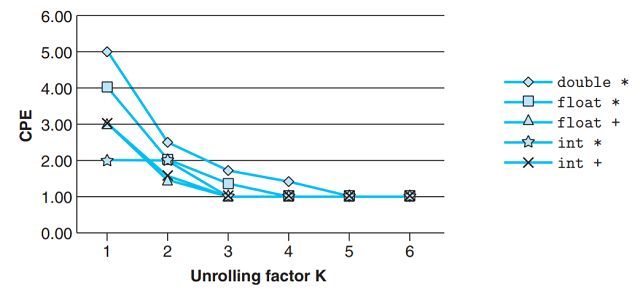
测量combine5展开次数k=2和k=3的展开代码性能:
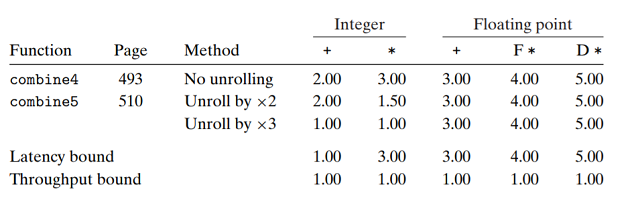
-
对于整数加法, CPE有所改进: 达到延迟界限. 这得益于减少了循环开销操作(这里指的应该是索引计算和
条件判断), 此时整数加法的延迟成为限制性能的关键因素. -
其他情况并没有性能提高 — 已经到达延迟界限.
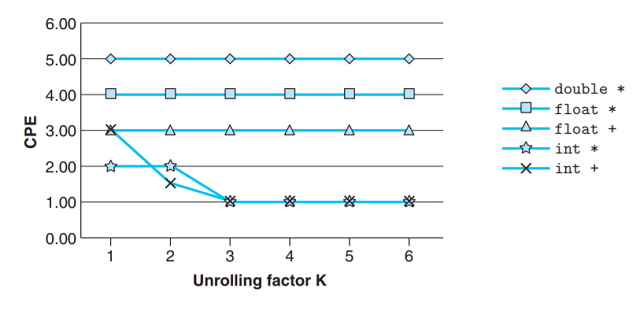
下图给出循环展开至6的CPE测量值, 可以看到没有一个低于延迟界限.
为何展开次数的增大仍然无法超越延迟界限? 观察2×1时, combine5内循环代码. 其中
合并类型为浮点数乘法:
i in %rdx, data in %rax, limit in %rbp, acc in %xmm0
.L35 loop:
vmulsd (%rax, %rdx, 8), %xmm0, %xmm0 Multiply acc by data[i]
vmulsd 8(%rax, %rdx, 8), %xmm0, %xmm0 Multiply acc by data[i + 1]
addq $2, %rdx Increment i by 2
cmpq %rdx, %rbp Compare limit to i
jg .L35 if >, goto loop
可以看到, 循环展开后每次迭代有两条vmulsd指令, 下图给出这段代码的数据流表示:
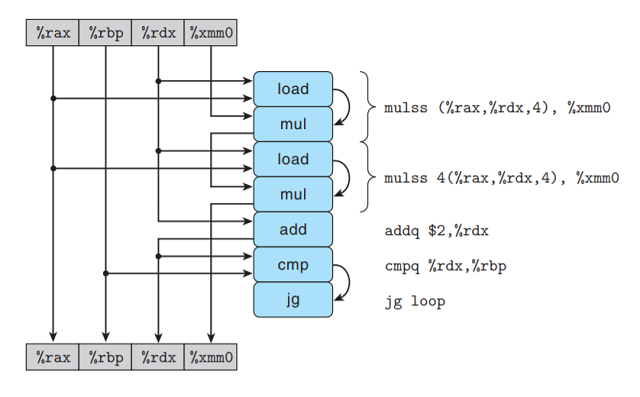
每次迭代过程中, %xmm0会被读写两次. 重新排列, 简化和抽象后得到的数据流表示:
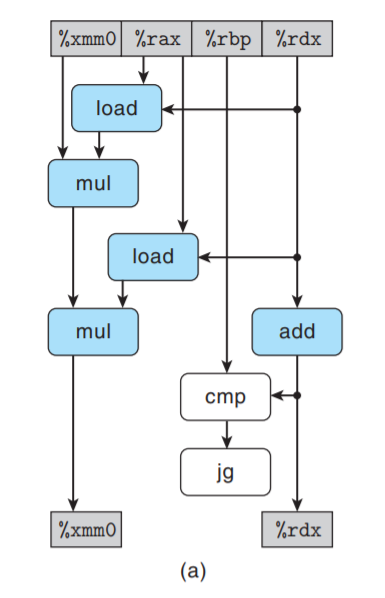
在上图基础上只保留循环寄存器及相关的操作符:
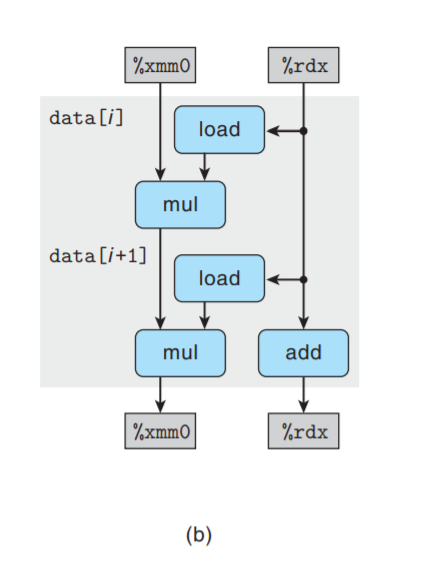
再把上图复制n/2次, 得到完整循环的数据流表示:
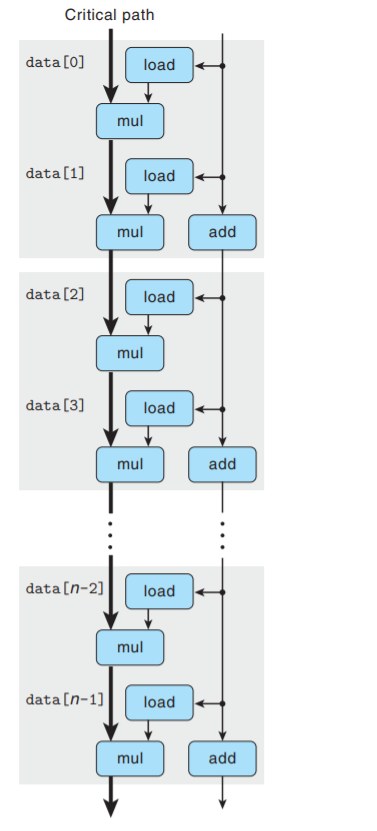
我们看到, 上图关键路径长度仍是n个mul操作 — 迭代次数减半, 但每次迭代中还有有两个顺序的
乘法操作. 这就是k×1循环展开不能超过延迟限制的原因. (实际上仍是顺序操作).
旁注: 让编译器展开循环
编译器可以很容易地执行循环展开, 主要优化等级设置的足够高, 很多编译器都能例行公式地做的这点.
5.9 提高并行性
在此, 程序的性能是受运算单元的延迟限制的.
不过, 执行加法和乘法的功能单元是完全流水化的 — 可以以每个时钟周期开始一个新操作;
并且有些操作可以被多个功能单元执行.
硬件具有以更高速率执行乘法和加法的潜力, 但至此的代码都不能利用这种能力, 即使是使用循环展开也不能.
这是因为我们将累计变量放在一个单调的变量acc中, 其结果是在前面acc的计算完成前, 都不能计算acc
的新值 — 有关acc的操作虽然可以每个时钟周期开始一个操作, 但实际只会每L个周期开始一个操作,
因为它们的数据联系导致只能顺序执行. 这里L是合并操作的延迟.
现在我们要打破这种顺序相关, 得到比延迟界限更好性能.
5.9.1 多个累积变量
k×k循环展开
对于一个可结合和可交换的合并运算来说, 例如整数加法和乘法, 我们可以通过将一组合并运算分割成
两个或多个部分, 并在最后合并结果来提高性能.
例如将运算分割成2部分, 分别计算索引值为奇数和偶数的部分:
// 2 x 2 loop unrolling
void combine6(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1; //length - k + 1
data_t *data = get_vec_start(v);
data_t acc0 = IDENT;
data_t acc1 = IDENT;
//Combine 2 elements at a time
for (i = 0; i < limit; i += 2)
{
acc0 = acc0 OP data[i];
acc1 = acc1 OP data[i + 1];
}
//Finish any remaining elements
for(; i < length; i ++)
{
acc0 = acc0 OP data[i];
}
*dest = acc0 OP acc1; //合并最终结果
}
上述代码既使用了2次循环展开, 也使用了2路并行: 将索引值为偶数的元素累积在acc0中, 索引值为
奇数的元素累积在acc1中. 因此我们将其称为2×2循环展开.
比较只做循环展开和既做循环展开同时使用两路并行两种方法:
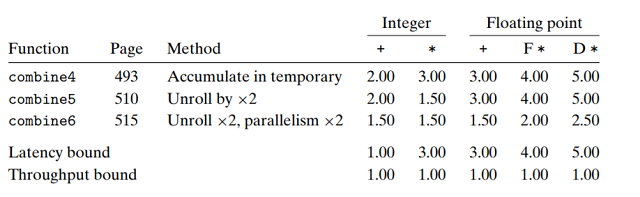
我们看到所有情况都得到了改进. 最棒的是, 我们打破了由延迟界限设下的限制. 处理器不再需要延迟一个
加法或乘法操作以待前一个操作完成.
同样用数据流表示分析combine6的性能:
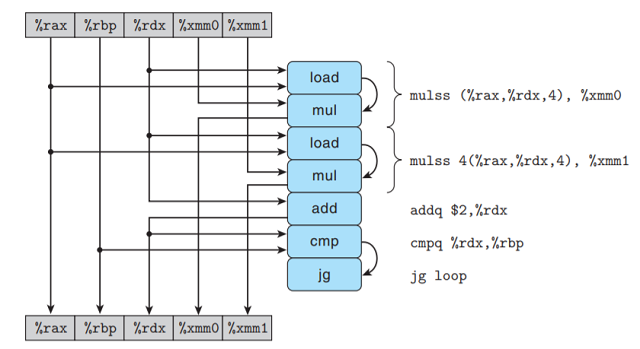
只关注与循环寄存器相关的操作:
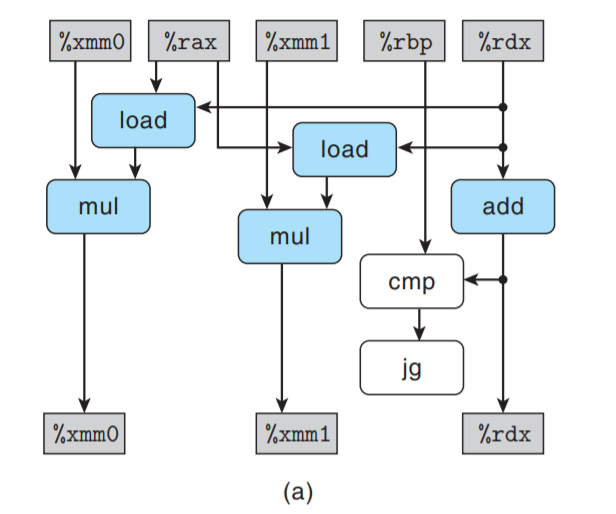
同combine5一样, 每次迭代包括2次vmulsd运算; 不同的是, 两次运算的读写寄存器不同, 它们之间
没有数据相关:
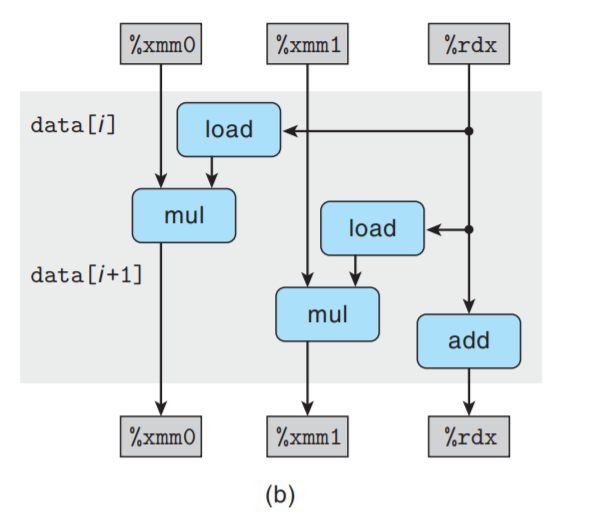
将模板复制n/2次, 得到在长度为n向量上的循环操作:
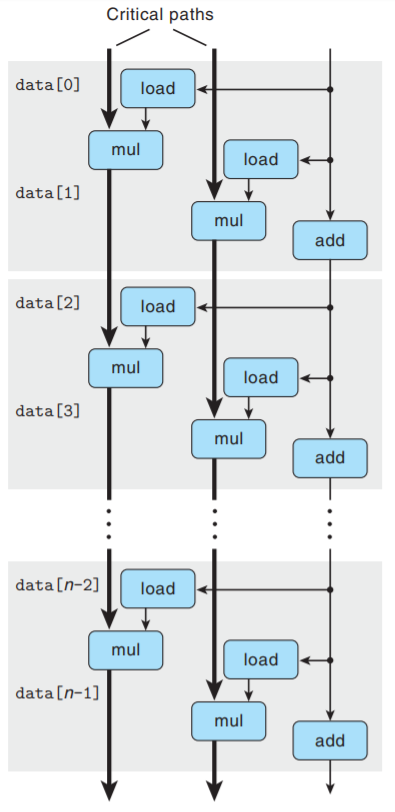
可以看到, 现在有2条关键路径 — 一条对应于计算索引为偶数的元素的乘积; 一条对应奇数. 每条关键
路径只包含n/2次操作, 两条路径并行执行, 因此CPE≈5.00/2=2.50.
相似的分析可以解释其他运算组合. 唯一例外是整数加, 我们已将CPE降到1.0以下, 但还是有太多循环
开销, 而无法达到理论界限0.50.
我们可以将多个累积变量变换归纳为: 循环k次展开, 并行累积k个变量, 得到k×k循环展开.
下图展示当k=6时, 应用k×k的效果:
通常, 只有保持能够执行该操作的所有功能单元的流水线都是满的, 程序才能达到这个操作的吞吐量界限.
对延迟为L, 容量为C的操作而言, 要求循环展开的因子k≥L×C.
在执行k×k循环展开时, 我们必须考虑变换后是否保留原始函数功能.
-
在第二章我们知道, 整数补码的运算是可交换和可结合的, 甚至当溢出时也是如此,
因此变换后保留原始函数功能. 有些编译器可以做这种或与之类似的变换来提高
整数数据的运算性能. -
另一方面, 浮点数乘法和加法是不可结合的, 可能出现舍入或溢出. 实际中数据一般是连续的,
所以这种情况很少出现, 程序员在选择优化前最好和用户协商使用. 大多数编译器并不会尝试
对浮点数代码进行这种变换, 因为它们没有办法判断引入这种变换所带来的风险.
(When in doult, the compiler must be conservative.)
5.9.2 重新结合变换
k×1a循环展开
现在讨论另一种打破顺序相关从而使性能提高到延迟界限之外的方法.
我们看到k×1循环展开的combine5没有改变合并向量元素的操作数. 不过, 如果我们对
代码做很小的改动, 我们可以从根本上改变合并执行的方式, 极大地提高程序的性能.
// 2 x 1a loop unrolling
void combine7(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1; //循环上界
data_t *data = get_vec_start(v); //数组指针
data_t acc = IDENT;
//Combine 2 elements at a time
for(i = 0; i < limit; i += 2)
{
acc = acc OP (data[i] OP data[i + 1]);
}
//Finish any remaining elements
for(; i < length; i ++ )
{//剩余元素
acc = acc OP data[i];
}
*dest = acc;
}
combine7代码与combine5的唯一区别在于内循环中元素的合并方式.
combine5中:
acc = (acc OP data[i]) OP data[i + 1];
combine7中:
acc = acc OP (data[i] OP data[i + 1]);
差别仅在于两个括号是如何放置的. 我们称之为 重新结合变换 (reassociation transformation), 因为
括号改变了向量元素与累积值acc的合并顺序, 产生了我们称为2×1a的循环展开形式.
对于未经训练的人来说, 这两个语句看上去本质上是一样的, 但是当我们测量CPE时, 得到了惊人的结果:
整数加的性能几乎与k×1展开版本(combine5)相同; 而其他操作则与并行累积变量的版本(combine6)
相同, 时k×1性能的两倍, 已经突破了延迟界限造成的限制.
下图说明combine7内循环代码(乘法, double)的数据流表示:
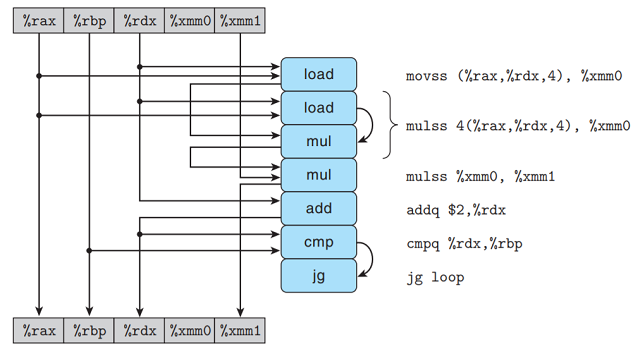
我们看到首先第一个load操作读取data[i], 第二个load与mul操作读取data[i + 1]并将
两个元素相乘.
接着第二个mul操作将上述乘积结果乘以累积值acc. 下图对操作进行重新排列、优化和抽象:
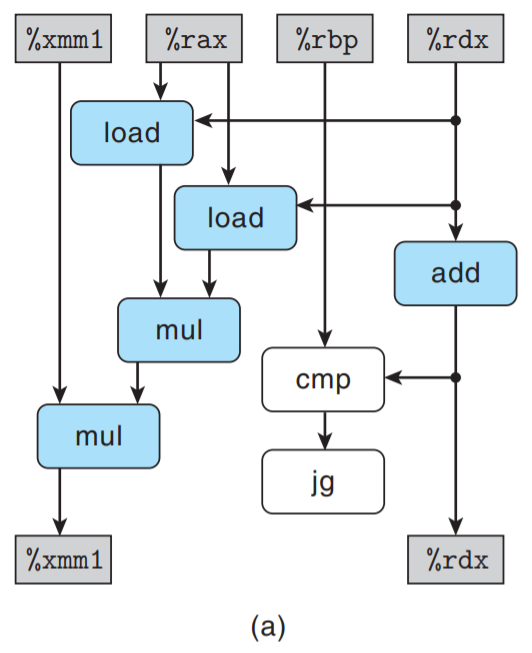
消除与循环寄存器无关的操作:
每次迭代有两个load和两个mul操作, 但只有一个mul操作形成了循环寄存器间的数据相关链.
(只有一个mul操作与acc相关, 有前后依赖关系, 另一个mul可以用流水线技术优化).
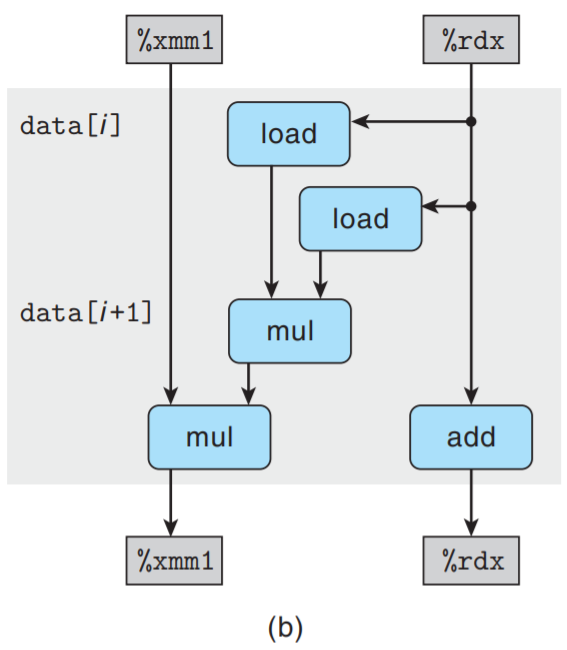
接着把上模板复制n/2次, 给出了n个向量元素相乘所执行的计算:
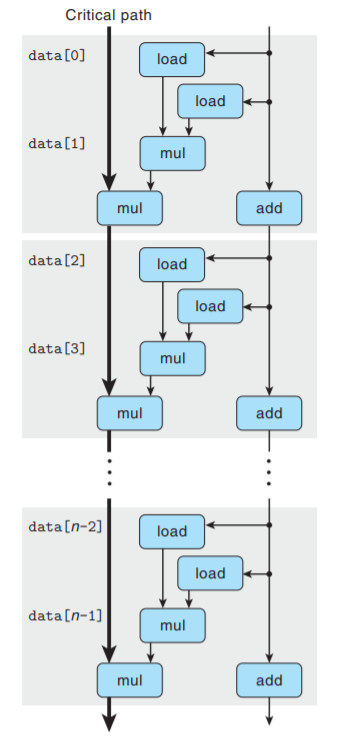
可以看到关键路径上只有n/2个操作, 每次迭代的第一个mul不需要等待前一次迭代的累积值
就可以执行. 因此CPE的下界变为原来的1/2.
在执行重新结合变换时, 我们同样改变了向量元素的合并顺序. 其是否保留原始函数功能与k×k
变换的讨论相同.
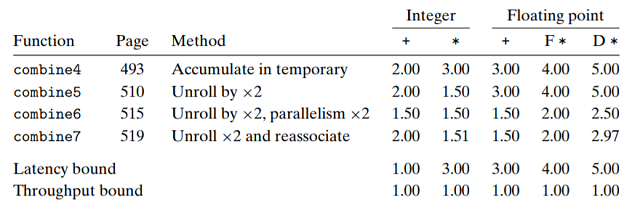
5.10 优化合并代码的结果小结 Summary of Results for Optimizing Combining Code
我们极大地提高了对向量元素加和乘的合并函数性能. 下标总结了不同代码的性能结果:
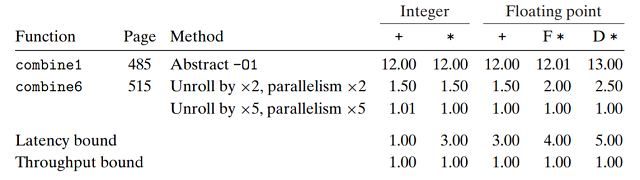
使用多项优化技术, 程序的CPE以及接近于吞吐量界限, 只受限于功能单元的容量. 与原始代码相比,
使用普通的C代码和标准的编译器就获得了10∼20倍的提升. 这个例子说明现代处理器具有相当
的计算能力, 但我们可能需要非常程式化的方式来编写程序以便将这些能力诱发出来.
5.11 一些限制因素 Some Limiting Factors
-
我们已经看到在一个程序的数据流表示中, 关键路径指明了执行该程序所需时间的一个基本下界.
即如果程序中有某条数据相关链, 链上所有延迟之和为T, 则程序执行至少需要T个周期. -
另外功能单元的吞吐量界限也是程序执行时间的一个下界. 假设一个程序一共需要N个某种
运算, 而微处理器只有C个能执行这个操作的功能单元, 每个功能单元的发射时间为I.
那么程序执行完毕至少需要N×I/C个周期.
(顺序执行需要N×I, 并行C个累积值后时间缩短为原之间的1/C).
本节中, 我们会考虑一些其他制约程序在实际机器上性能的因素.
5.11. 1 寄存器溢出 Register Spilling
循环并行带来的优化受计算能力的限制. 如果我们的并行数目p超过了可用寄存器的数量, 那么
编译器会诉诸 溢出 (spilling), 将某些临时值存放到内存中 — 通常是在运行时堆栈上.
例如将combine6的多累积变量模式扩展到k=20时其CPE相比k=10不降反升. 这是由于
现代x86-64处理器有16个寄存器及16个YMM寄存器保持浮点数, 一旦循环变量的数量超过
了可用寄存器的数量, 程序就必须在栈上分配一些变量.
在10×10循环展开的迭代中, 累积变量acc0的更新:
vmulsd (%rdx), %xmm0, %xmm0 acc0 *= data[i]
我们看到acc0保存在寄存器中. 与之相比, 20×20循环展开的对应部分非常不同:
vmovsd 40(%rsp), %xmm0
vmulsd (%rdx), %xmm0, %xmm0
vmovsd %xmm0, 40(%rsp)
此时累积变量保存为栈上的一个局部变量, 程序必须从内存读取累积变量, 并将结果保存回栈内存中.
一旦编译器必须要诉诸寄存器溢出, 那么维护多个累积变量的优势就有可能消失. 幸运的是, x86-64有
足够多的寄存器, 大多数循环展开在出现寄存器溢出前就已经达到了吞吐量限制.
5.11.2 分支预测和预测错误处罚
在3.6.6节我们知道, 当分支预测逻辑不能正确一个分支是否要跳转的时候, 条件分支可能会招致
很大的 预测错误处罚 . 通过本章关于一些处理器的知识, 我们可以理解这样的处罚是从何而来的了.
现代处理器的工作远超前于当前正在执行的指令, 从内存中读取新指令 --> 译码指令以确定在什么
操作数上执行什么操作. 只要指令遵循的是简单的顺序, 那么指令流水化(instruction pipelining)
就能很好的工作.
当遇到分支时, 处理器必须预测分支该往哪个方向走. 在一个使用投机执行(speculative execution)
的处理器中, 处理器会开始执行预测的分支目标处的指令. 它会避免修改任何实际的寄存器或内存位置,
直到确定了预测结果: 如果预测✔, 处理器“提交”投机执行的指令结果, 存储到实际的寄存器或内存中;
如果预测❌ ,处理器必须丢弃所有投机执行的结果, 重新回到分支的正确位置, 重新开始执行指令.
这样做会引起错误预测处罚: 需要重新填充指令流水线.
那么一个程序员如何能够保证分支预测的处罚不会阻碍程序的效率呢? 对于这个问题没有简单的答案, 但
存在一些可用的通用原则.
1. 不要过分关心可预测分支
我们已经看到错误的分支预测的影响可能很大, 但这并不意味着所有的程序分支都会减缓程序的执行.
实际上, 现代处理器中的分支预测逻辑非常善于辨别不同的分支指令的有规律的模式和长期的趋势.
例如, 在合并函数中结束循环的分支通常会被预测为选择分支(选择继续for循环), 因此只在最后
一次会导致预测错误处罚.
正如前面说到的, 当从combine2变化到combine3时, 我们把函数get_vec_element从内循环中
拿了出来, 考虑我们观察到的结果:

CPE基本没变, 即使combine3消除了每次迭代用于检查向量索引是否在界限内的2个条件语句.
对于这个函数来说, 这些预测总是确定索引在界内, 所以是高度可预测的.
性能主要受限于合并操作的延迟, 执行边界检测所需的额外计算可以与合并操作并行执行. 处理器可以
预测分支的结果, 所以不会对程序执行的关键路径产生多大影响.
2. 书写合适用条件传送实现的代码
分支预测只有对有规律的模式可行. 程序中的许多测试是完全不可预测的, 依赖于数据的特性: 例如
一个数是正数还是负数. 对于这些测试, 分支预测逻辑会处理地很糟糕.
对于本质上无法预测的情况, 如果编译器能够产生使用条件数据传送而不是使用条件控制的代码, 可以
极大提高性能. (条件数据传送: 提前计算所有分支的结果, 最后根据不同条件赋值).
下面举例说明: 给定两个整数数组a和b, 我们想将a(i)和b(i)分别设为两者较小/较大值.
条件控制代码:
void minmax1(long a[], long b[], long n)
{
long i;
for( i = 0; i < n; i ++ )
{
if( a[i] > b[i] )
{
long t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
在随机数据上测试这个函数, 得到的CPE大约为13.5; 而对于可预测的数据, CPE为2.5∼3.5,
预测错误惩罚约为20个周期.
条件数据传送代码:
void minmax1(long a[], long b[], long n)
{
long i;
for( i = 0; i < n; i ++ )
{
long min = a[i] < b[i] ? a[i] : b[i];
long max = a[i] < b[i] ? b[i] : a[i];
a[i] = min;
b[i] = max;
}
}
上述函数对于随机或可预测数据, 其CPE都约为4.0.
注意这里代码虽然多了两个条件判断, 但并不是可以一直执行下去的一条分支.
在3.6.6中讨论过, 不是所有的条件行为都能用条件数据传送实现, 所以不可避免存在某些情况, 程序员
不能避免写出会导致条件分支的代码, 而对于条件分支, 处理器用分支预测可能会处理地很糟糕. 不过有时
程序员在这种情况如果懂点脑筋, 可以使代码更容易地被翻译成条件数据传送.
5.12 理解内存性能 Understanding Memory Performance
到目前为止我们所写的代码, 都只访问相对比较小的内存: 例如合并函数中的向量元素长度小于1000,
数据量不会超过8000个字节. 所有现代处理器都包含一个或多个 高速缓存 (cache)存储器, 以对
这样少量的数据提供快速访问.
本节会进一步研究涉及加载(从内存 --> 寄存器)和存储(寄存器 --> 内存)操作的程序的性能, 只考虑
所有数据都存放在高速缓存中的情况. 在第6章会进一步探究高速缓存.
如下图, 现代处理器有专门的功能单元来执行加载和存储操作, 这些单元有内部的缓冲区来保存未完成的
内存操作请求.
例如我们的参考机有2个加载单元, 每个可以保存72个未完成的读请求; 有1个存储单元, 可以保存
42个写请求. 每个单元通常可以每个时钟周期开始一个操作.
5.12.1 加载的性能 Load Performance
一个包含加载操作的程序的性能既依赖于流水线的能力, 也依赖于加载单元的延迟. 目前为止我们的所有函数
CPE都没有低于0.50.
一个制约示例的CPE因素是: 每次迭代都需要读内存, 对于2个加载单元而言, 其每个时钟周期均只能启动
1条加载操作, 所以CPE不可能小于0.50. 对于每次计算需要加载k个值的应用, 我们不可能获得低于k/2
的CPE.
到目前为止, 我们在示例中都没看到加载操作的延迟带来的影响 — 加载操作的地址仅依赖于循环索引i, 所以
加载操作不会成为限制性能的关键路径的一部分.
要确定一台机器的加载延迟, 我们可以建立由一系列加载操作组成的一个计算, 且具有迭代间的依赖关系.
考虑计算一个链表长度的函数list_len:
typedef struct ELE{
struct ELE *next;
long data;
}list_ele, *list_ptr;
long list_len(list_ptr ls){
long len = 0;
while(ls){
len ++;
ls = ls->next;
}
return len;
}
测试表明函数list_len的CPE为4.00, 我们认为这直接表明了加载操作的延迟.
为理解原因, 需要考虑循环的汇编代码:
ls in %rdi, len in %rax
.L3: loop:
addq $1, %rax Increment len
movq (%rdi), %rdi ls = ls->next
testq %rdi, %rdi Test ls
jne .L3 if ls != null, goto loop
其中mov指令是循环中的关键瓶颈: 加载操作更新%rdi值作为下一次迭代的操作值. 函数的性能是由
加载操作的延迟所限制的. 事实上, 这个测试结果与文档中参考机的L1级cache的4周期访问时间
是一致的, 相关内容将在6.4节讨论.
5.12.2 存储的性能 Store Performance
存储操作将一个寄存器的值写到内存, 这个操作的性能, 尤其是与加载操作的相互关系, 包含一些细微的问题.
与加载操作一样, 在大多数情况中, 存储操作能够在完全流水化的模式中工作, 每个周期开始一条新的存储.
例如将向量元素设置为0的函数, 其CPE值为1.00, 对于只具有单个存储功能单元的机器, 已经达到最佳
情况.
//Set elements of array to 0
void clear_array(long *dest, long n)
{
long i;
for( i = 0; i < n; i ++ )
*dest = 0;
}
与到目前为止我们考虑过的其他操作不同, 存储操作不影响任何寄存器 — 将寄存器值写到内存, 一系列
存储操作不会产生数据相关. 而只有加载操作会收到存储操作影响, 因为只有加载操作能从由存储操作写的
那个位置读回值.
write_read函数代码说明了加载和存储操作之间可能的相互影响. 图中也展示了该函数的2个执行示例,
均是对数组a=−10,17调用, 参数cnt=3. 这些执行说明了加载和存储操作的一些细微之处:

-
在示例A中, 参数
src和dst分别指向数组的两个元素, 从src的读取不会受对dst写的影响.
在较大次数迭代上测试这个示例得到CPE=1.3. -
在示例B中, 参数
src和dst都是a[0]. 在这种情况下, 指针引用*src即读取操作都会得到
dst之前加载操作的值. 函数的最终效果是a[0]=n−1. 这个示例说明了一个现象, 我们称为
读/写相关 (write/read dependency) — 一个内存读的结果依赖于一个最近内存的写. 我们的
性能测试表明示例B的CPE为7.3, 读/写相关导致处理速度下降约6个时钟周期.
为理解处理器如何区别两个示例 — 为何下降了6个时钟周期, 我们必须更加仔细的看看加载单元和存储
单元. 如下图所示, 存储单元包含一个 存储缓冲区, 包含已经被发射到存储单元而又还没有完成的存储
操作的地址和数据, 这里的完成包括更新高速缓存:
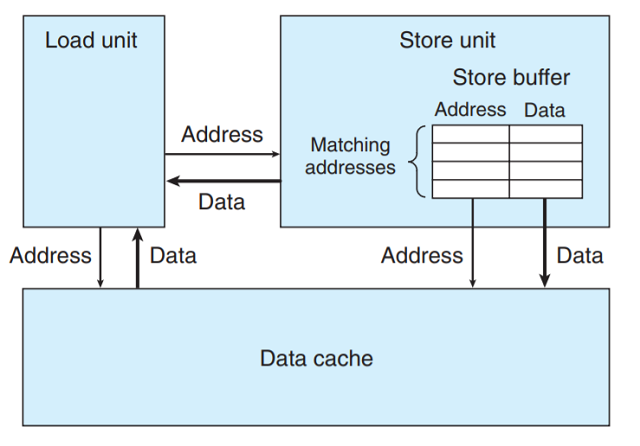
提供这样一个缓冲区, 使得一系列存储操作不必等到每个操作都更新高速缓存就能够执行.
当一个加载操作执行时, 它必须检查存储缓冲区中的条目, 看看没有没地址匹配. 如果有地址匹配
(意味着读操作位置的数据会被最近的写操作更新), 它就取出相应的数据条目作为加载操作的结果.
GCC生成的write_read内循环代码如下:
src in %rdi, dest in %rsi, val in %rax, cnt in %rdx
.L3: loop:
movq %rax, (%rsi) Write val to dst
movq (%rdi), %rax val = *src
addq $1, %rax val = val + 1 = *src + 1
subq $1, %rdx cnt --
jne .L3 if cnt != 0, goto loop
下图给出循环代码的数据流表示:
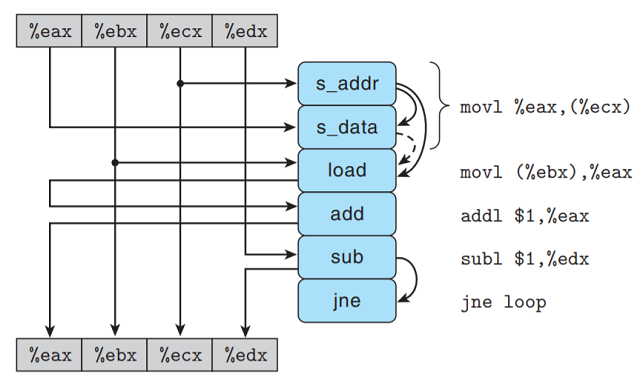
指令movq %rax, (%rsi)被翻译成2个操作: s_addr指令计算存储地址, 在存储缓冲区创建一个条目,
并设置该条目的地址字段, s_data操作设置该条目的数据字段. 正如我们看到的, 两个计算是独立进行的,
这对程序的性能很重要 — 这使得参考机中的不同功能单元同步执行这些操作.
下面说明操作间的数据相关:
-
s_addr操作的地址必须在s_data之前. -
对指令
movq (%rdi), %rax译码得到的load操作必须检查所有未完成的存储操作地址 — 存储缓冲区中,
所以load操作与s_addr操作间存在数据相关;s_data与load操作之间有虚弧线, 表示有条件相关:
如果load操作的目标地址与s_addr相同(条件), 则load操作必须等待s_data存放至存储缓冲区后,
如果地址不相同则二者独立.
下图说明了write_read内循环操作之间的数据相关:
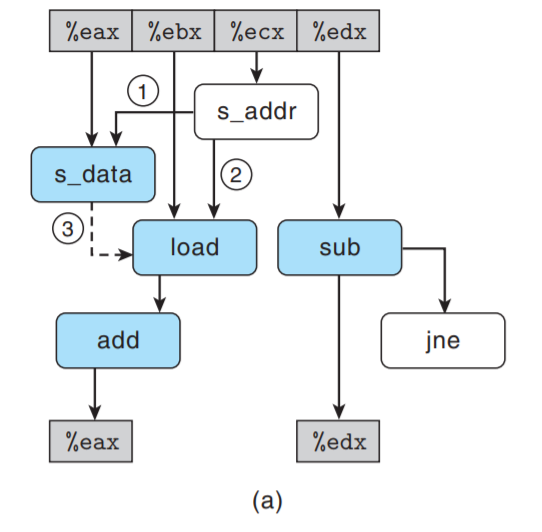
- 标号
1:s_data即存储数据需要在s_addr即存储地址之后执行. - 标号
2:load操作需要等待s_addr操作以比较其目标地址是否与s_addr相同. - 标号
3:load与s_data的条件数据相关, 当加载和存储地址相同时会出现.
下图移走了不直接影响迭代与迭代之间数据流的操作:
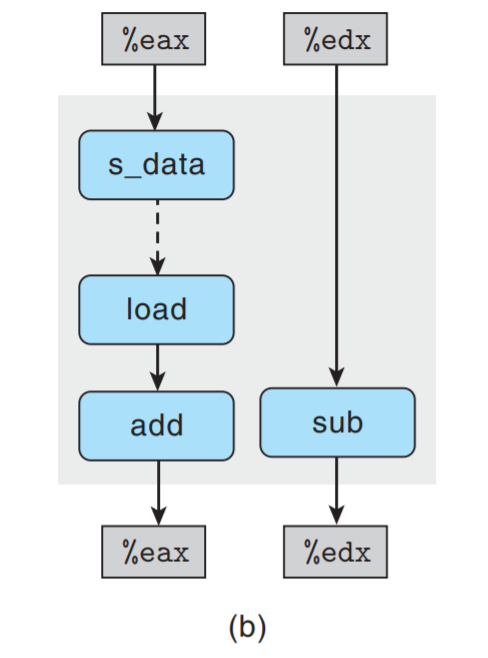
数据流图给出2个相关链, 此时左侧作为限制性能的主要因素.
现在我们可以理解函数write_read两个示例的性能特征了:
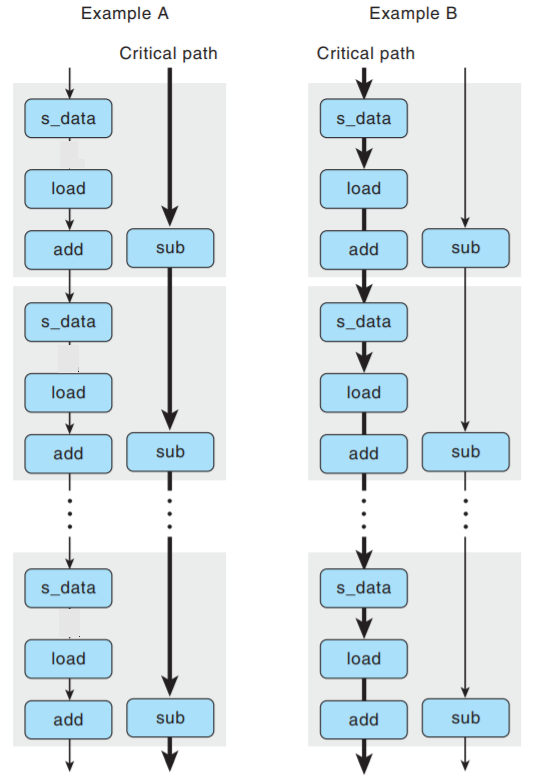
-
对于示例A, 有不同的源和目的地址, 加载和存储操作可以独立进行, 因此唯一的关键路径由
减少变量cnt构成. -
对于示例B, 源和目的地址相同,
s_data和load指令之间的数据相关使得关键路径包括
存储、加载和增加数据. 我们发现顺序执行这3个操作共需要7个时间周期.
上述例子说明, 内存操作的实现包括许多细微之处. 对于寄存器操作, 在指令被译码成操作时, 处理器
就可以确定哪些指令会影响其他指令; 而对于内存操作, 只有加载和存储的地址被计算出后, 处理器
才能确定哪些指令会影响其他操作(如load和s_data的条件相关).
高效地处理内存操作对许多程序的性能来说至关重要.
5.13 应用: 性能提高技术 Life in Real World: Performance Improvement Techniques
虽然只考虑了有限的一组应用程序, 但我们已经能得出关于如何编写高效代码的重要的经验教训:
-
高级设计: 即选择适当的算法和数据结构. (做好时间复杂度分析)
-
基本编码原则: 避免限制优化因素, 使得编译器产生高效代码.
- 消除连续的函数调用.
- 消除不必要的内存引用.
-
低级优化: 结构化代码以利用硬件功能.
- 展开循环, 降低开销, 并使得进一步优化成为可能.
- 提高指令并行性, 如多个累积变量和重新结合技术.
- 用功能性的风格重写条件操作, 使得编译采用条件数据传送.
