
第10讲 查找(二)
散列(Hash)表
-
负载因子: 已有的元素 / 数组的长度
-
哈希函数
[1] 除余法 h(x) = x % M
[2] 乘余取整法 h(x) = floor(n * (A * x的小数部分)) 0 < A < 1
[3] 平方取中法 先平方,然后取中间几位
[4] 基数转换法 换成其他进制,然后取其中几位
[5] ELFhash字符串 -
解决冲突的方式
[1] 开散列方法(拉链法)
[2] 闭散列方法(开放寻址法) -
聚集和二级聚集
a. 线性探查法 d(i) = (d(0) + i * c) % M。易产生聚集问题。
b. 二次探查法。易产生二级聚集问题。
d(2i - 1) = (d(0) + i^2) % M
d(2i) = (d(0) - d ^2) % M
c. 随机探查法。易产生二级聚集问题。
d. 双散列探查法
字符串模式匹配(KMP)
-
暴力:自创从起始位置进行比较,当失败时,从下一个位置继续比较。
-
kmp:对暴力的优化,主要理解next数组的含义。
next【 i 】定义:子串前 i 个字母构成的字符串,最长的与前缀相等的后缀长度(非平凡:前后缀的最大长度i - 1,也就是不能为 i 。平凡的,如abcd,前缀中有个abcd,后缀中也有个abcd,这是平凡的;而abc和bcd就是不平凡的)。
特别的,next [ 0 ] = - 1 。(有时候选项从0开始,注意辨别)
匹配:当出现子串和主串不匹配的时候,我们把子串直接移到匹配失败的前next【匹配失败的字符前一个元素下标】位置处(王道书上是:移动位数 = 已匹配的字符数 - 对应部分匹配值。这里的部分匹配值就是next数组的值),不是往后 移!(注意是看子串!)。至于next数组的值,考试的时候直接手写出就行,如k个字符,我们要枚举前1到k - 1个字符(因为是非平凡的!考试是0到k-1,y总代码是1开始),从而求出next数组所有的值。(原理,就是next数组的定义,具体不说明了,其实我也有点迷糊,不过上面的总结应该可以应付考试。。。)
注意 :考试的时候模拟要从下标0开始,下面例子是从1开始的。还有个真题是从0开始的,注意区别。


王道书上的kmp:
为什么要单独说呢。因为王道书上的next数组稍微有点不一样。本来想找几个题做一下,验证一下y总和王道的方法各有什么不一样,结果发现真题就2道,y总课上也讲了,说明可以使用真题。但是为了以防万一考的有点不一样,所以这里还是列出王道的定义。
-

-

-
求串‘ababaaababaa’的nextval数组?
A.010112010102 B.010114110102
C.010104210104 D.011102110104
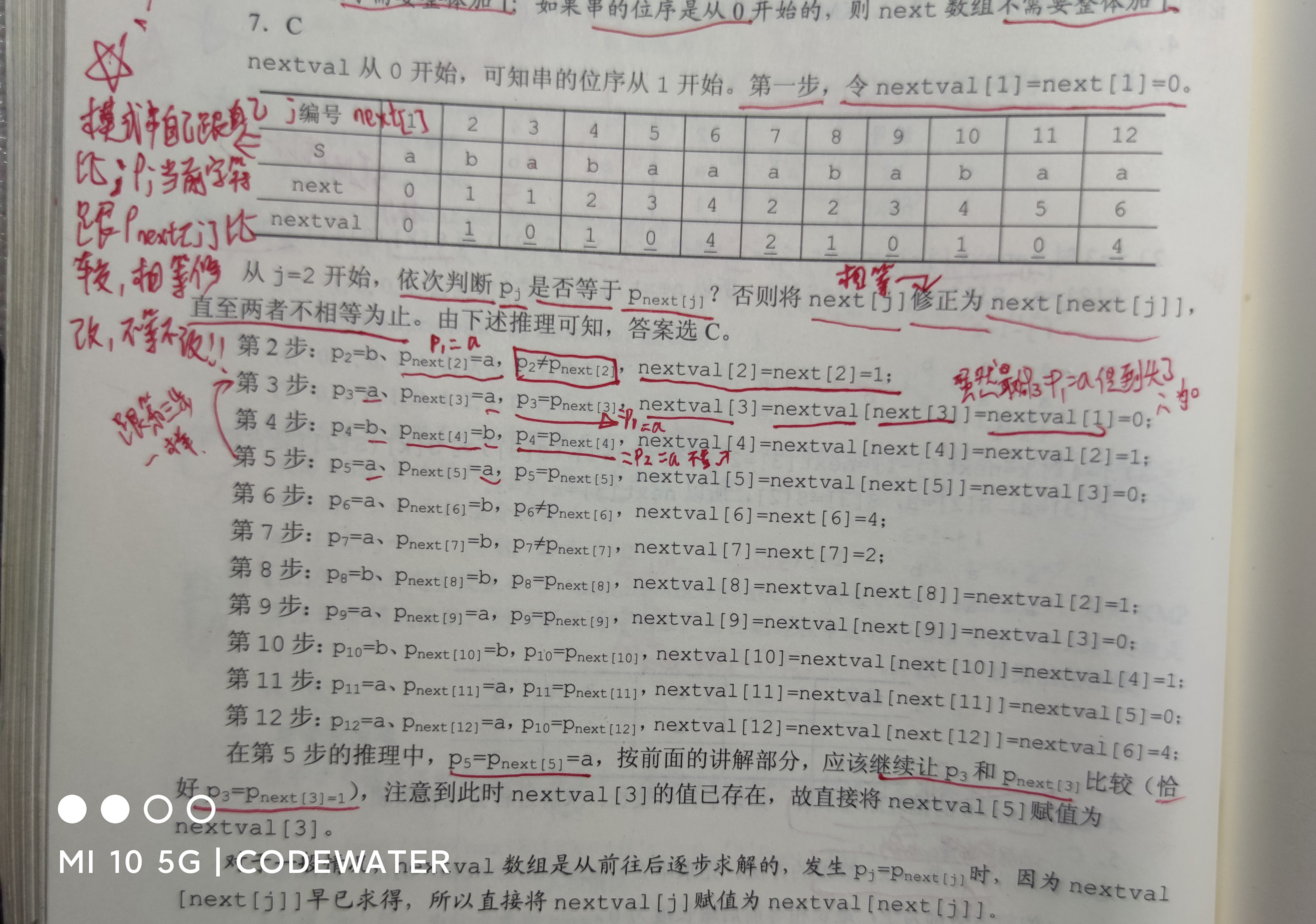
考题:
2011-9、2014-8、2015-8、2018-9、2018-41、2019-8、2019-9
-
查找效率是指时间复杂度,而存储效率是指负载因子(空间)。注意区别
-
堆积会影响平均查找长度变长。
-
失败的查找长度是对于整个整数域来讲,比较次数我们从每种余数往后比较,直到空位置为止,然后把所有的余数对应的比较次数相加除以总共的长度即可 ! 跟成功的查找长度不一样。

y总和王道对于next数组的说法虽然不一样,但都是一个意思。王道右移PM形成next数组,是为了匹配失败的时候直接找当前的next值;y总的就是要找前一个next值,然后才能知道后移多少。关于后移,两个说法也是不一样,但是结果都一样,所以读者习惯那个就选哪个记忆。
(到这,应该总结改正完了。若还有错误,欢迎大佬们指出。)