
数据结构
并查集
作为一种简洁且优美的算法,并查集一向是很多人的最爱。
当然,它也将作为我们这一节的入门算法,接下来的算法会越来越有挑战,可千万不要放弃哦。
初始化
初始时每一个节点的父亲都是自己
for (int i = 1; i <= n; i ++ ) {
fa[i] = i;
}
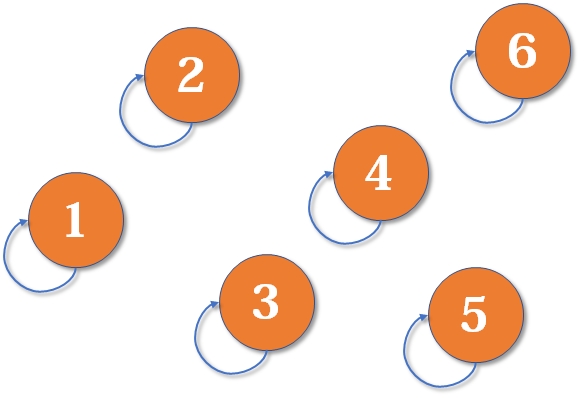
先来个图~
查询(路径压缩)
int get(int x)
{
if (x == fa[x]) return x;
return fa[x] = find(fa[x]);
}
效果是这样的

这个递归的终止就是 x == fa[x]
而后,依次返回 fa[x] = fa[fa[...]] = end;
合并
int x = find(a), y = find(b);
if (x == y) continue;
if (x != y)
{
fa[x] = y;
}
按秩合并
其实作用不大…
初始化(按秩合并)
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
ranks[i] = 1;
}
}
合并(按秩合并)
inline void merge(int i, int j)
{
int x = find(i), y = find(j); //先找到两个根节点
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1
}
原理:把简单的树往复杂的树上合并
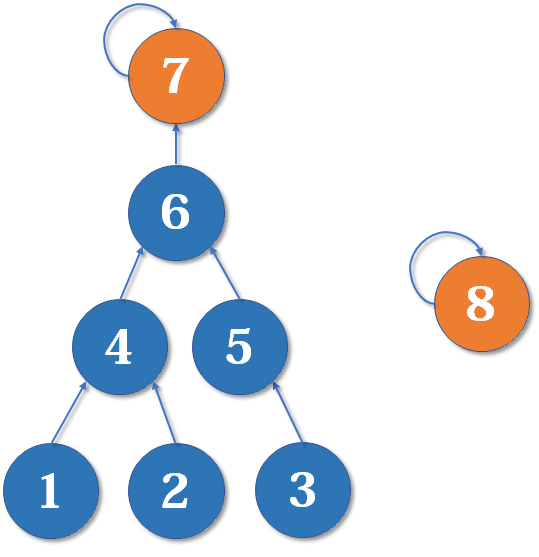
当我们合并这两个元素的时候,怎么合并更好呢?
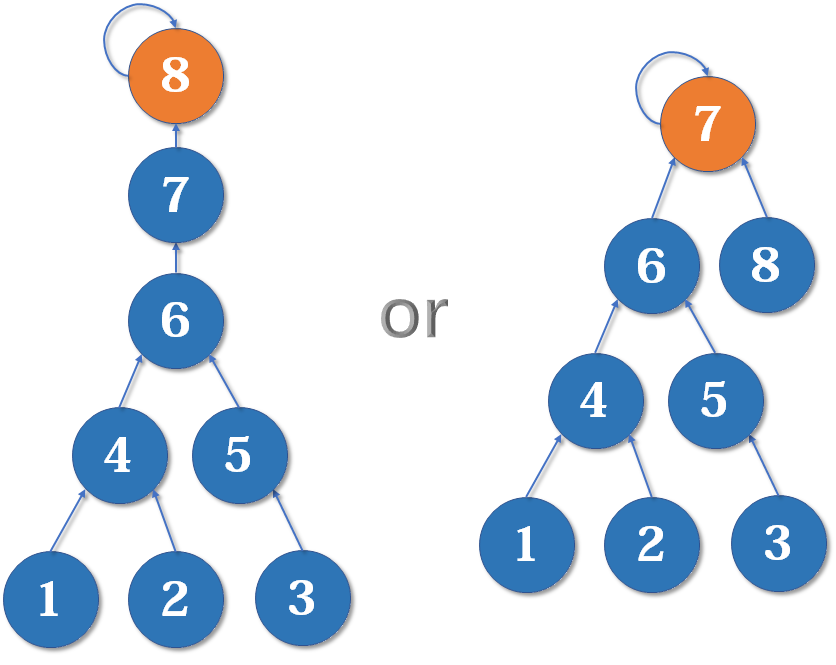
当然是把小的集合的父节点设为大的集合祖先好一点。
按秩合并就是这个意思 qwq
种类并查集
一般的并查集,维护的是具有连通性、传递性的关系。
例如亲戚的亲戚是亲戚。但是,有时候,我们要维护另一种关系:敌人的敌人是朋友。
种类并查集就是为了解决这个问题而诞生的。
带权并查集
int find(int x) //查找祖先 + 路径压缩
{
if (p[x] == x) return x;
//如果自己不是祖先
int t = find(p[x]); //就依次查找自己的父亲的父亲...是不是
//因为赋完值之后就都变成了祖先节点,所以我们要先存下来。
d[x] += d[p[x]]; //加上父节点的路径长度
return p[x] = t; //更新
//返回祖先节点,依次更新每一个父节点,直到更新到最开始查找的节点为止
}
技巧,通过边权之间的关系进行关系传递
小编的 参考程序
并查集的其它应用和例题
思路 : 逆向思维,把摧毁转换成 修建
小编的 参考程序
栈
对顶栈
#include<bits/stdc++.h>
using namespace std;
int q;
int tl, tr, stkl[1000001], stkr[1000001];
int s[1000001], f[1000001];
void push_left(int x) {
stkl[ ++ tl] = x; // 将 x 插入栈 A 中
s[tl] = s[tl - 1] + x; // 统计前缀和
f[tl] = max(f[tl - 1], s[tl]); // 维护前缀和的最大值
}
int main() {
scanf("%d", &q);
while(q --) {
char str[2];
int x;
scanf("%s", str);
f[0] = -1e9; // 初始化
if(str[0] == 'I') { // 插入操作
scanf("%d", &x);
push_left(x);
}
if(str[0] == 'D') {
if(tl > 0) tl --; // 注意边界问题
// A 的栈顶弹出
}
if(str[0] == 'L') {
if(tl > 0) stkr[ ++ tr] = stkl[tl --]; // 注意边界问题
// A 的栈顶弹出,插到 B 的栈顶
}
if(str[0] == 'R') {
if(tr > 0) push_left(stkr[tr --]); // 注意边界问题
// 将 B 的栈顶弹出,插到 A 的栈顶
}
if(str[0] == 'Q') {
scanf("%d", &x);
printf("%d\n", f[x]); // 求 x 之前的最大的前缀和是多少
// 查找
}
}
return 0;
}
建立两个栈,二者都以当前光标 mid 的位置所在的那一端为栈顶
栈A 储存 1 ~ mid 的位置 栈 B 储存 mid + 1 ~n 的位置
单调栈
单调栈 分为 单调递增栈 和 单调递减栈
-
单调递增栈:单调递增栈就是从栈底到栈顶数据是从大到小
-
单调递减栈:单调递减栈就是从栈底到栈顶数据是从小到大
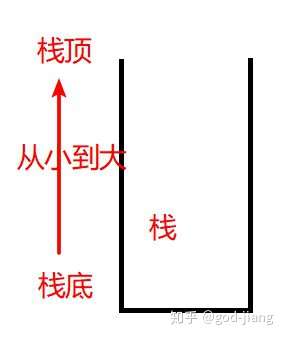
这个动图完美展现了单调栈的实现过程

问 1: 找当前数字向右查找的第一个大于它的数字之间有多少个数字
-
设置一个单调递增的栈(栈内0~n为单调递减)
-
当遇到大于栈顶的元素,开始更新之前不大于当前数字所大于的值的数量
问 2: 131. 直方图中最大的矩形
将 问 1 左右各做一次 就可以了
队列
单调队列
和单调栈类似,队列内所有元素都具有单调性
分析
如果直接维护,那无疑是非常麻烦的,倒不如用一个队列储存 数组下标 。
这样就可以方便的判断是否需要弹出元素,输出时输出下标所对应的元素就可以了!
主要代码
hh = 0, tt = -1; // hh 队头, tt 队尾
for (int i = 1; i <= n; i ++ )
{
if(tt >= hh && i - k + 1 > q[hh]) hh ++;
while (tt >= hh && a[q[tt]] >= a[i]) tt --;
q[ ++ tt] = i;
if (i >= k) printf("%d ",a[q[hh]]);
}
堆
对顶堆
用一个小根堆和一个大根堆维护堆顶即可
没什么可说的…
#include <bits/stdc++.h>
using namespace std;
int P;
int idx, n;
int x;
int main()
{
scanf("%d", &P);
while (P -- )
{
scanf("%d %d", &idx, &n);
printf("%d %d\n",idx, n + 1 >>1);
priority_queue<int> l;
priority_queue<int,vector<int>,greater<int>> r;
for(int i = 1; i <= n; i ++)
{
scanf("%d", &x);
if (r.empty() || r.top() < x) r.push(x);
else l.push(x);
while(r.size() > l.size() + 1)
{
l.push(r.top());
r.pop();
}
while(r.size() < l.size())
{
r.push(l.top());
l.pop();
}
if(i % 2) printf("%d ",r.top());
if(i % 20 == 0) puts("");
}
puts("");
}
return 0;
}
哈希表
由于 $hash$ 表 可以用 $Map$ 实现,所以这里讲解的是 字符 $hash$。
字符 $hash$在利用 $unsigned long long$ 自然溢出且进制为 $131$ 或 $13331$ 时冲突概率极低。
所以,只要两个字符串 $hash$ 值相等,我们就可以认为这两个字符串是相等的。
初始化
const int N = 1e6, base = 131;
typedef unsigned long long ULL;
ULL h[N]; // 字符串每个字节的 hash 值
ULL p[N]; // 131 进制的预处理数组
char str[N];// 读入的字符串
预处理
可以用 $for$ 循环完成, 记得处理 $p$ 数组,判断两个字符串是否相等时有用。
scanf("%s", str + 1);
int n = strlen(str + 1);
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * base + str[i] - 'a';
p[i] = p[i - 1] * base;
}
查询
当我们查询 $[l, r]$ 之间的 $hash$ 值时,
根据前缀和的思想,用 r端点的 $hash$ 值减去 $l-1$ 为端点的 $hash$ 值即可。
不过,注意:因为在 r端点的 $hash$值可以看作是低位在左, 高位在右的整数,
例如 $aaaaabbb$, 而 l - 1 端点的 $hash$ 值为 $aaaaa$, 我们需要的 $[l, r]$ 是 $bbb$。
只有将 l - 1 端点的 $hash$ 值乘上 $p[r - l + 1]$, 令其为 $aaaaa000 - aaaaabbb = bbb$。
ULL get(int l, int r) {
return h[r] - h[l - 1] * p[r - l + 1];
}
应用之 hash 判断回文串
左右各预处理一个 $hash$ 数组,枚举回文中点,二分查找半径。
如果半径为 $mid_len$, 中点为 $mid$,
则回文串左边用左 $hash$ 数组预处理,范围为 $[mid - mid_len, mid - 1]$。
回文串右边用右 $hash$ 数组预处理,范围为 $[mid + 1, mid + mid_len]$ 颠倒,
即 $[n - (mid + mid_len) + 1, n - (mid + 1) + 1]$。

%%%!我都不知道什么是按秩合并!