
一、差分约束系统
- 假设有这样一组不等式:
$$ \begin{aligned} & x_1 - x_2 \leqslant 0\\\ & x_1 - x_5 \leqslant -1\\\ & x_2 - x_5 \leqslant 1\\\ & x_3 - x_1 \leqslant 5\\\ & x_4 - x_1 \leqslant 4\\\ & x_4 - x_3 \leqslant -1\\\ & x_5 - x_3 \leqslant -3\\\ & x_5 - x_4 \leqslant -3 \end{aligned} $$
- 每个不等式都是两个未知数的差小于等于某个常数(大于等于也可以)
- 这样的不等式组,我们称为
差分约束系统 - 该问题的一个解为 $x = (-5, -3, 0, -1, -4)$
- 另一个解为 $x’ = (0, 2, 5, 4, 1)$
- 可以发现 $x’$ 等于 $x$ 中每个元素
+5 - 显然 $x + d$ 都是该系统的解
- 因此,这个不等式组要么无解,要么就有无数组解
差分约束系统与最短路
回顾一下单源最短路中的三角形不等式:
$$ d[v] <= d[u] + edge[u][v] $$
这是显然的,否则 $d[v]$ 可以用 $d[u] + edge[u][v]$ 更新
把 $d[u]$ 移到左边:$d[v] - d[u] \leqslant edge[u][v]$
正好符合差分约束系统的格式!
一个差分约束系统就对应着一张有向图!
有向图的构造
- 每个不等式中的每个未知数 $x_i$ 对应图中的一个顶点 $V_i$
- 把所有不等式都化成图中的一条边,对于不等式 $x_i - x_j \leqslant c$,把它化成三角不等式 $x_i \leqslant x_j + c$,就可以化作边 $V_j \to V_i$,边权为 $c$
- 还需要增加源点,因为不等式组转化为边不能保证源点可以到达所有点。我们自己造一个源点 $V_0$,给所有的点都加上 $V_0 \to V_i$ 的边权为 $0$ 的边。
于是我们就得到了这样的有向图
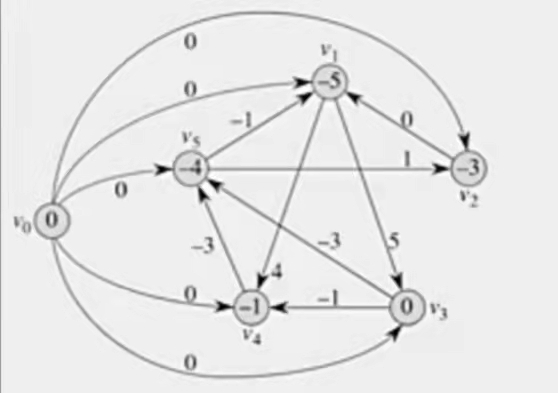
差分约束系统求解
在这张图上,每一个边都代表差分约束系统中的一个不等式
现在以 $V_0$ 为源点,求单源最短路径
由于存在负权边,必须用 Bellman-Ford 或 SPFA 算法
得到的最短路径数组 $dist[] = {-5, -3, 0, -1, -4}$ 就是一组合法解
差分约束系统无解的情形
前面所描述的差分约束系统也有可能出现无解的情况,也就是从源点到某一个顶点不存在最短路径
也就是有向图中存在负权值回路,使得最短路径无穷小。
无解的差分约束系统是什么样子的呢?
比如下面这个例子
$ \begin{aligned} & x_1 - x_5 \leqslant -5\\\ & x_4 - x_1 \leqslant 3\\\ & x_5 - x_4 \leqslant -1 \end{aligned} $
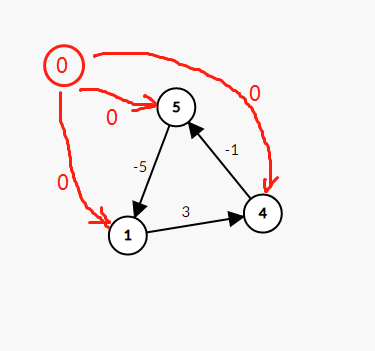
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::vector;
using std::queue;
struct Edge {
int to, cost;
Edge(int to = 0, int cost = 0): to(to), cost(cost) {}
};
int main() {
int n, m;
cin >> n >> m;
vector<vector<Edge>> g(n + 1);
rep(i, n) g[0].emplace_back(i + 1, 0);
rep(i, m) {
int c, c2, y;
cin >> c >> c2 >> y;
g[c2].emplace_back(c, y);
}
vector<int> vis(n + 1), cnt(n + 1);
const int INF = 1001001001;
vector<int> dist(n + 1, INF);
auto spfa = [&](int u) {
dist[u] = 0;
queue<int> q; q.push(u); vis[u] = 1;
while (q.size()) {
u = q.front(); q.pop();
vis[u] = 0;
for (auto e : g[u]) {
int v = e.to;
int w = e.cost;
if (dist[u] + w >= dist[v]) continue;
dist[v] = dist[u] + w;
cnt[v]++;
if (cnt[v] == n) return true;
if (vis[v] == 0) {
q.push(v);
vis[v] = 1;
}
}
}
return false;
};
if (spfa(0)) puts("NO");
else {
rep(i, n) cout << dist[i + 1] << " ";
}
return 0;
}
ZOJ 火烧连营 link
陆逊派了很多密探,获得了他的敌人——— 刘备军队的信息。通过密探,他知道刘备的军队已经分成几十个大营,这些大营连成一片(一字排开),从左到右用 $1, 2, \cdots, n$ 编号。
第 $i$ 个大营最多容纳 $C[i]$ 个士兵,而且通过观察刘备军队的动静,陆逊可以估计到从第 $i$ 个大营到第 $j$ 个大营至少有多少士兵。
现在希望你估计出刘备最少有多少士兵。
$n \leqslant 1000, m \leqslant 10000$。
分析:
样例
3 2
1000 2000 1000
1 2 1100
2 3 1300
设 $3$ 个军营的人数分别为 $A[1], A[2], A[3]$,容量为 $C[1], C[2], C[3]$,前 $i$ 个军营的总人数为 $S[i]$
试着列出所有不等式
对于 $2$ 条观察:
- $S[2] - S[0] \geqslant 1100$
- $S[3] - S[1] \geqslant 1300$
可以给两个式子两边同乘 $-1$,得到
- $S[0] - S[2] \leqslant -1100$
- $S[1] - S[3] \leqslant -1300$
当然它们也不能超过这些兵营容量之和:
- $S[2] - S[0] \leqslant 3000$
- $S[3] - S[1] \leqslant 3000$
每个兵营的实际人数也不能超过容量:
- $A[1] \leqslant 1000 \Rightarrow S[1] - S[0] \leqslant 1000$
- $A[2] \leqslant 2000 \Rightarrow S[2] - S[1] \leqslant 2000$
- $A[3] \leqslant 1000 \Rightarrow S[3] - S[2] \leqslant 1000$
每个兵营的实际人数要非负:
- $A[1] \geqslant 0 \Rightarrow S[1] - S[0] \geqslant 0$
- $A[2] \geqslant 0 \Rightarrow S[2] - S[1] \geqslant 0$
- $A[3] \geqslant 0 \Rightarrow S[3] - S[2] \geqslant 0$
本题要求的是 $A[1] + A[2] + A[3]$ 的最小值,即 $S[3] - S[0]$ 的最小值。
构造有向图:
- 把不等式全部转化为 $S[i] - S[j] \leqslant c$ 的形式
- 然后把 $j$ 往 $i$ 连一条有向边,权值为 $c$
$ \begin{aligned} & S[0] - S[2] \leqslant -1100\\\ & S[1] - S[3] \leqslant -1300\\\ & S[2] - S[0] \leqslant 3000\\\ & S[3] - S[1] \leqslant 3000\\\ & S[1] - S[0] \leqslant 1000\\\ & S[2] - S[1] \leqslant 2000\\\ & S[3] - S[2] \leqslant 1000\\\ & S[0] - S[1] \leqslant 0\\\ & S[1] - S[2] \leqslant 0\\\ & S[2] - S[3] \leqslant 0 \end{aligned} $
构造好网络之后,要求的是 $S[3] - S[0]$ 的最小值,即 $S[3] - S[0] \leqslant M$
$M$ 要取最大值,$S[0] - S[3] \leqslant -M$
即求 $3$ 到 $0$ 的最短路径,长度为 $-M$
题目中还会出现无解的情况。
3 1
100 200 300
2 3 600
也就是需要判断一下图中是否有负环。
于是用 Bellman-Ford 或 SPFA 算法就可以轻松解决此题。
Code:
#pragma GCC target("avx2")
#pragma GCC optimize("O3")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::vector;
using std::queue;
using ll = long long;
struct Edge {
int to, cost;
Edge(int to = 0, int cost = 0): to(to), cost(cost) {}
};
int main() {
int n, m;
while (cin >> n >> m) {
vector<int> c(n);
rep(i, n) cin >> c[i];
vector<ll> s(n + 1);
rep(i, n) s[i + 1] = s[i] + c[i];
vector<vector<Edge>> g(n + 1);
rep(i, n) g[i].emplace_back(i + 1, c[i]);
rep(i, n) g[i + 1].emplace_back(i, 0);
rep(i, m) {
int l, r, x;
cin >> l >> r >> x;
--l;
g[r].emplace_back(l, -x);
}
const ll INF = 1e18;
vector<ll> dist(n + 1, INF);
vector<int> vis(n + 1), cnt(n + 1);
auto spfa = [&](int u) {
dist[u] = 0;
queue<int> q; q.push(u); vis[u] = 1;
while (q.size()) {
u = q.front(); q.pop();
vis[u] = 0;
for (auto e : g[u]) {
int v = e.to;
int w = e.cost;
if (dist[u] + w >= dist[v]) continue;
dist[v] = dist[u] + w;
cnt[v]++;
if (cnt[v] == n) return true;
if (vis[v] == 0) {
q.push(v);
vis[v] = 1;
}
}
}
return false;
};
if (spfa(n)) puts("Bad Estimations");
else cout << -dist[0] << '\n';
}
return 0;
}
二、有向图的强连通分量SCC
名词解释
- 强连通:有向图中,任意两个顶点之间互相可达
- 强连通图:任意两个顶点都可以互相可达的有向图
- 强连通分量(
Strong Connected Components):一个有向图的极大顶点子集,其中任意两个顶点之间互相可达
每个顶点恰好属于一个强连通分量(否则与 $scc$ 的定义矛盾)。换句话说,有向图的全部强连通分量是顶点的一个划分。
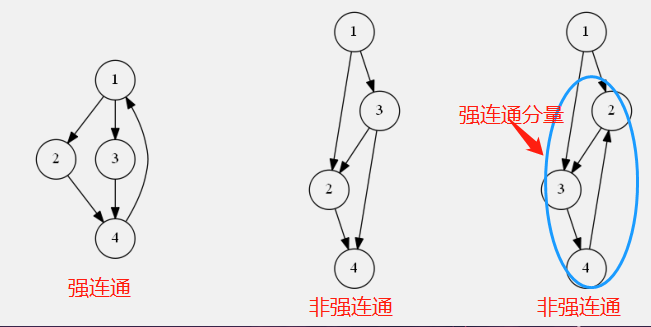
问题模型
- 对于一些存在依赖关系的模型,若其建图是一个
DAG,则可以直接通过拓扑排序解决,但若其中有环则需要特殊处理 - 对于有环的问题,会出现一些互相依赖的关系,这些关系组成了一个强连通分量,根据题目要求的性质,对于这个强连通分量可以将其缩为一个点
- 将所有强连通分量缩成点后即可在
DAG上求解 - 建模方式和
DAG很相似,建出图不是DAG就先跑一遍SCC缩点即可
.png)
有向图边的模型
- 使用
DFS从任意点遍历有向图,可以得到DFS树 - 每一条边和
DFS树的关系,可以分为以下四种:
a. 树枝边:DFS树上的边,即指向未访问过节点的边
b. 前向边:指向DFS树中子树中节点的边
c. 后向边:指向DFS树中父亲的边
d. 横叉边:其他边,即指向DFS树中非子树的边 - 下面考虑如何判断这四种边
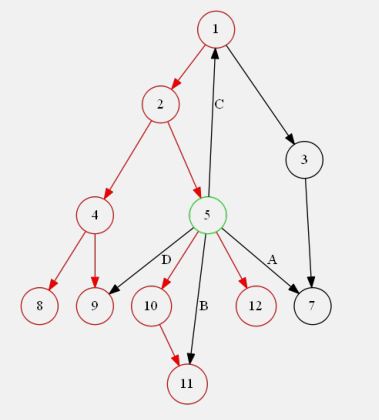
- 红色标记为
DFS树 - 记录
DFS序 - $A$ 边终点未访问过,为树枝边
- $B$ 边终点已被访问过,且
dfn[v] > dfn[u],说明在子树中,则为前向边 - $C$ 边终点已被访问过且不在子树中,终点在栈中则为后向边
- $D$ 边终点已被访问过且不在子树中且已经出栈,为横叉边
Tarjan
- 在一个有向无环图上
DFS,找出每一个强连通分量 - 考虑每一个强连通分量高度最低(离根近)的那个点
- 这些点将
DFS树分割成了许多个子树,每个子树中的点组成了一个强连通分量 -
分割的方法是在
dfs同时另外维护一个栈存放节点,离开分割点时把分割点往下的部分全部取出来就是一个强连通分量 -
现在需要找到这些分割点
- 维护一个数组
low,$low[u]$ 代表点 $u$ 所能到达的,深度最小的点的祖先的 $dfs$ 编号 - 初始 $low[u] = dfn[u]$
- 对于边 $(u, v)$
a. 若为树枝边,则用low[v]更新
b. 若为后向边,则用dfn[v]更新
c. 若为前向边,因为指向的点的信息已经通过树枝边传递过来,所以无需更新
d. 若为横叉边,则指向另一个强连通分量,无需更新 - 当
low[u] = dfn[u]时,u就是一个分割点
具体而言:
DFS过程中,碰到哪个节点,就将哪个节点入栈。栈中节点只有在其所属的强连通分量已经全部求出时,才会出栈。- 如果发现某节点 $u$ 有边
连到栈里的节点v,则更新 $u$ 的low值为 $\min(low[u], dfn[v])$,若low[u]被更新为dfn[v],则表明目前发现 $u$ 可达的最早的节点是 $v$。 - 对于 $u$ 的子节点 $v$,从 $v$ 出发进行的
DFS结束回到 $u$ 时,使得 $low[u] = \min(low[u], low[v])$。因为 $u$ 可达 $v$,所以 $v$ 可达的最早的节点,也是 $u$ 可达的。 - 如果一个节点 $u$,从其出发进行的
DFS已经全部完成,而且此时其low值等于dfn值,则说明 $u$ 可达的所有节点,都不能到达任何比 $u$ 早的节点 ———— 那么该节点 $u$ 就是一个强连通分量在DFS搜索树中的根。 - 此时,显然栈中 $u$ 上方的节点,都是不能到达比 $u$ 更早的节点的。将栈中节点弹出,一直弹到 $u$(包括 $u$),弹出的节点就构成了一个强连通分量
SCC 的 tarjan 算法伪代码
void tarjan(u) {
dfn[u] = low[u] = ++index
stack.push(u)
for each (u, v) in E {
if (v is not visited) {
tarjan(v)
low[u] = min(low[u], low[v])
}
else if (v in stack) {
low[u] = min(low[u], dfn[v])
}
}
if (dfn[u] == low[u]) { // u 是一个强连通分量的根
repeat
v = stack.pop
print v
until (u == v)
} // 退栈,把整个强连通分量都弹出来
} // 复杂度是 O(E + V) 的
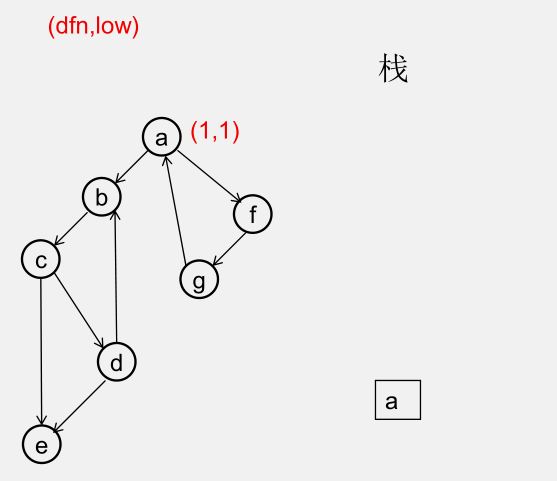
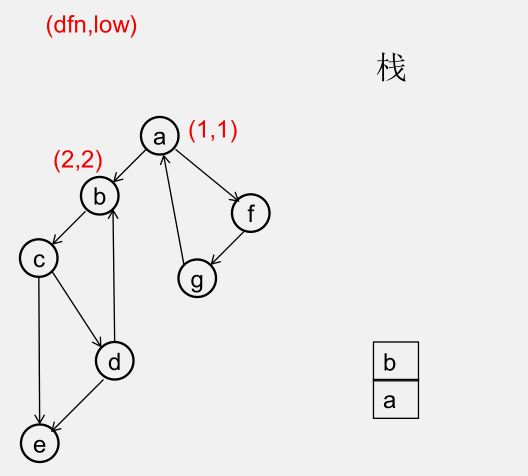
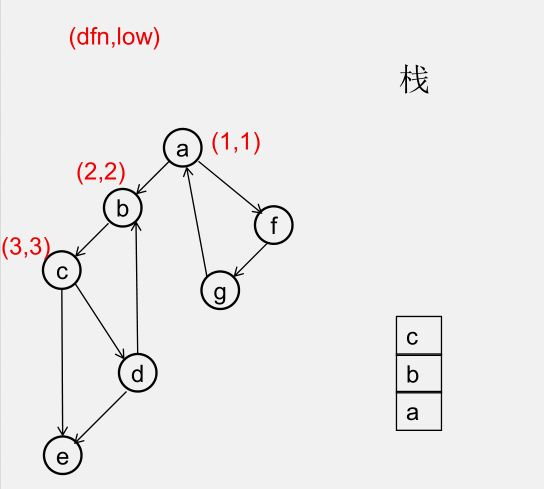
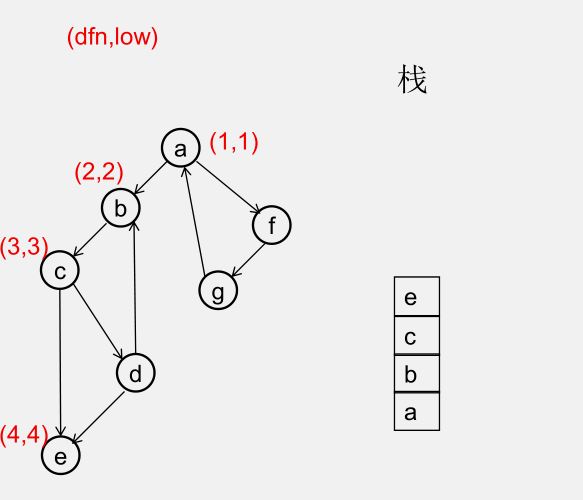
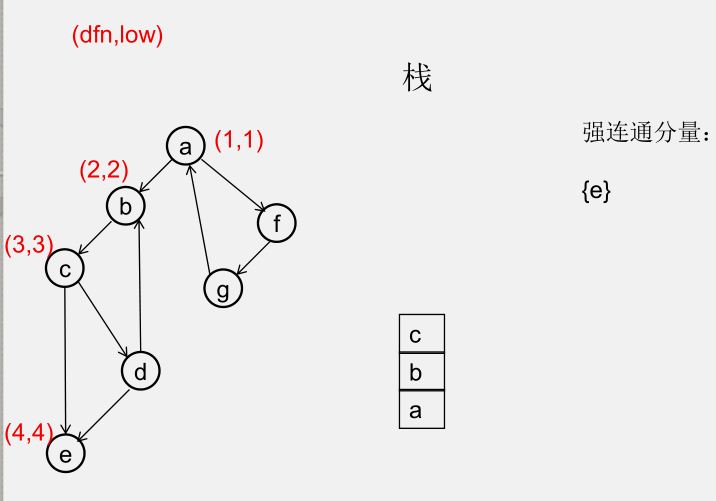
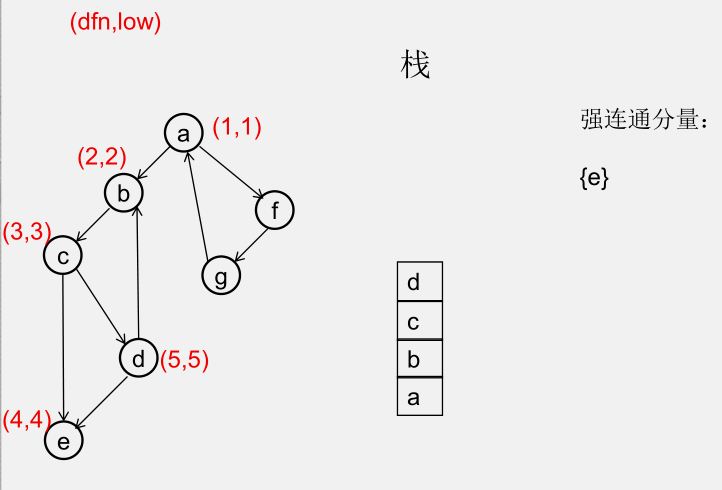
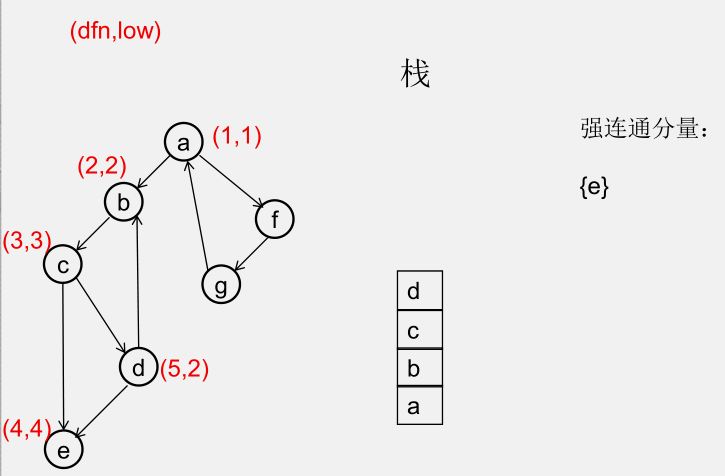
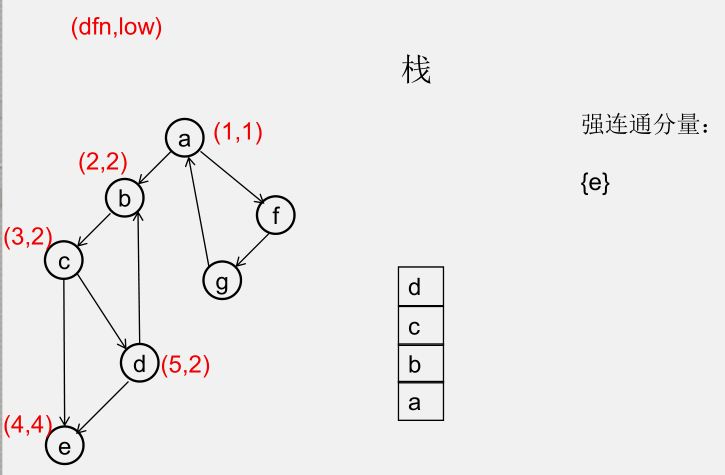
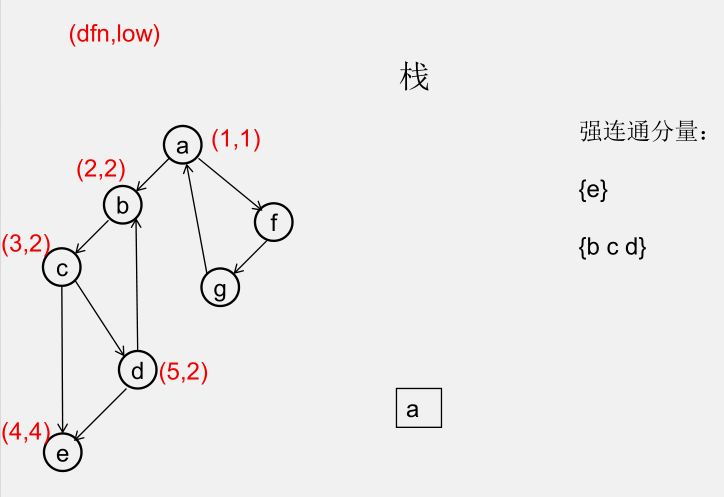
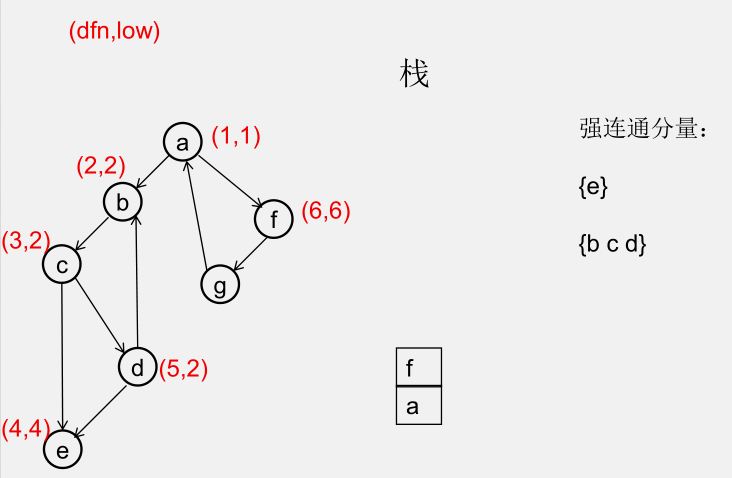
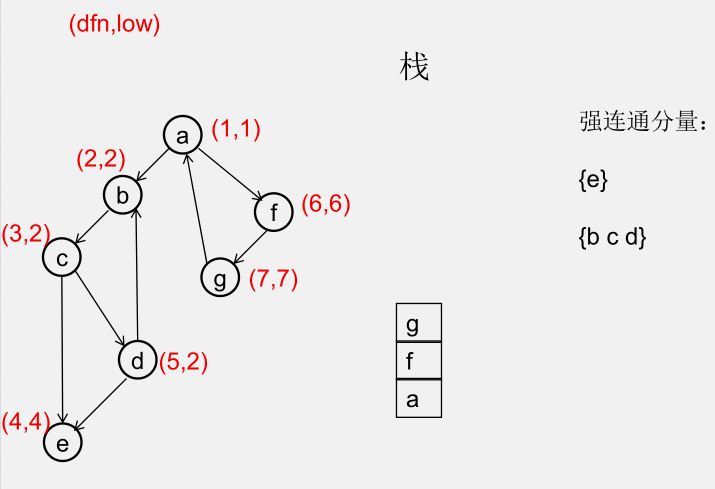
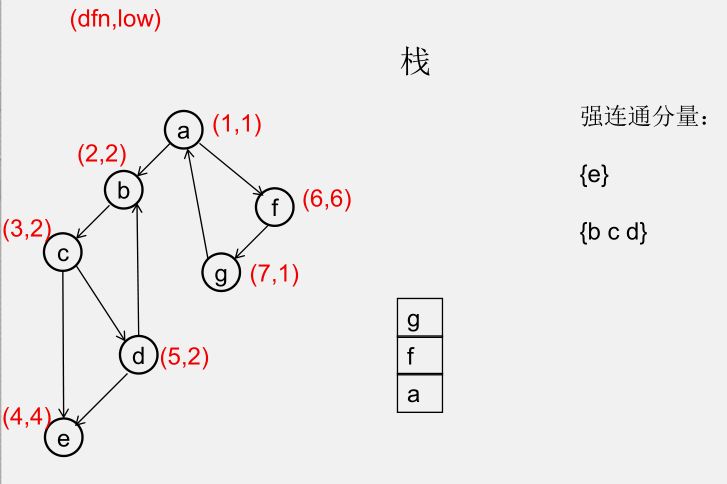
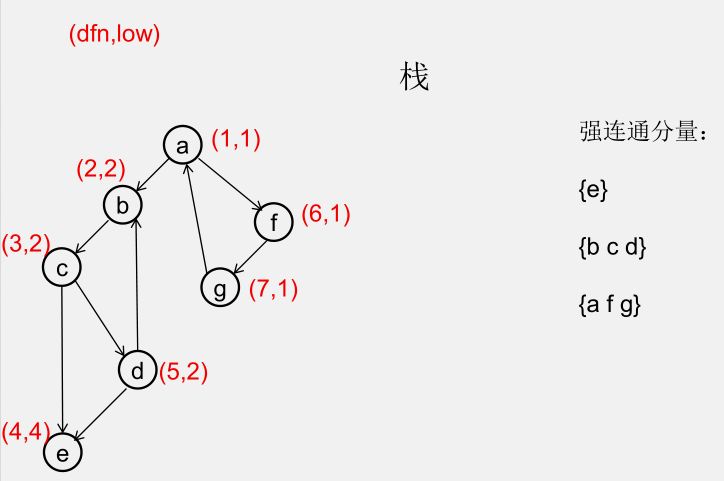
${\color{Red}{为什么从 u 出发的DFS全部结束回到u时,若 dfn[u] = low[u],此时将 u 及其上方的节点弹出,\\\ 就找到了一个强连通分量?}} $
此时所有节点分成以下几类:
1)还没被访问过的节点
2)栈中比 $u$ 早的节点(在 $u$ 下方)
3)栈中比 $u$ 晚的节点(在 $u$ 上方)
4)栈中的 $u$
5)曾经入栈(访问过),又出了栈的节点
要证明 1)2)5)三类节点,都是要么从 $u$ 不可达,要么不可达 $u$,且 3)4)类节点互相可达
1)还没被访问过的节点(显然由 $u$ 不可达)
2)栈中比 $u$ 早的节点(在 $u$ 下方)(由 $u$ 不可达,因为 low[u] = dfn[u])
3)栈中比 $u$ 晚的节点(在 $u$ 上方)(由 $u$ 可达)
4)栈中的 $u$
5)曾经入栈(访问过),又出了栈的节点(不可达 $u$)
现在只需证明:
- 第 5)类节点不可达 $u$
- 第 3)类节点可达 $u$
一、证第 5)类节点不可达 $u$
此类节点分成两部分:
1)早于 $u$ 的
2)晚于 $u$ 的
早于 $u$ 的不可达 $u$。若可达的话,它此时应该还在栈里面,而他在 $u$ 的下面———导致矛盾
第 $2$ 类中,任取节点 $x$,假设 $x$ 可达的最早节点是 $y$,则 $y$ 一定晚于 $u$,即 $x$ 不可达 $u$
具体的:
第 $2$ 类中,任取节点 $x$。$x$ 之所以已经被弹出栈,一定是因为最终 low[x] = dfn[x],或在栈里,位于某个 $y$ 节点上方(由 $y$ 可达,且满足条件 low[y] = dfn[y]。因为 $y$ 曾经在 $u$ 的上方,所以 $y$ 一定晚于 $u$。因为 low[x] 不可能小于等于 dfn[u],否 low[y] 就也会小于等于 dfn[u],这和 low[y] = dfn[y] 矛盾),所以 $x$ 到达不了 $u$ 及其比 $u$ 早的节点。
证第 5) 类节点不可达 $u$,证毕
二、第 3)类节点可达 $u$
若有此类节点 $x$ 不可达 $u$,则考虑最终的 low[x]:
$low[x] < dfn[u]$ 不可能,否则有 $low[u] < dfn[u]$
$low[x] = dfn[u]$ $x$ 可达 $u$
其他:
寻找 $x$ 所能到达的最早的,栈里面的节点 $y$,则 $y$ 必然比 $u$ 晚。而且有 low[y] = dfn[y](若此条不成立,则 $x$ 还能到达比 $y$ 更早的节点,矛盾)。而若 low[y] = dfn[y],则 $y$ 应该已经被弹出栈了,$y$ 上方的 $x$ 当然也已经不在栈中,这和 $x$ 是第 3)类节点矛盾。
例题1. 模板题: Strongly Connected Components
题意:查询两个点是否在同一个强连通分量里
分析:只需判断这两个点所在的强连通分量编号是否相同即可
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::vector;
using std::stack;
const int MX = 10005;
int dfn[MX], low[MX], idx;
bool inst[MX];
stack<int> st;
int cnt, scc[MX];
vector<vector<int>> to;
void chmin(int &x, int y) { if (x > y) x = y; }
void tarjan(int u) {
dfn[u] = low[u] = ++idx;
st.push(u); inst[u] = 1;
for (int v : to[u]) {
if (dfn[v] == 0) {
tarjan(v);
chmin(low[u], low[v]);
}
else if (inst[v]) chmin(low[u], dfn[v]);
}
if (low[u] == dfn[u]) {
++cnt;
int v;
do {
v = st.top(); st.pop(); inst[v] = 0;
scc[v] = cnt;
} while (v != u);
}
}
int main() {
int n, m;
cin >> n >> m;
to.resize(n);
rep(i, m) {
int s, t;
cin >> s >> t;
to[s].push_back(t);
}
rep(i, n) if (dfn[i] == 0) tarjan(i);
int q;
cin >> q;
rep(qi, q) {
int u, v;
cin >> u >> v;
cout << (scc[u] == scc[v] ? 1 : 0) << '\n';
}
return 0;
}
例题2. P2341 [USACO03FALL][HAOI2006]受欢迎的牛 G
在牧群中,有 $n$ 头奶牛,给定 $m$ 个有序对 $(A, B)$,表示 $A$ 仰慕 $B$。由于仰慕关系具有传递性,如果 $A$ 仰慕 $B$,$B$ 仰慕 $C$,那么 $A$ 也仰慕 $C$。现在请你计算受每头奶牛仰慕的奶牛数量。
$n \leqslant 10000, m \leqslant 50000$
分析:
题意简单来说就是有多少个顶点是由任何顶点出发都可达的。
有用的定理:
DAG中唯一出度为 $0$ 的点,一定可以由任何点出发均可达(由于无环,所以从任何点出发往前走,必然终止于一个出度为 $0$ 的点)
解题思路:
- 求出所有强连通分量
- 把每个强连通分量缩成一点,则形成一个有向无环图
DAG DAG上面如果有唯一的出度为 $0$ 的点,则该点能被所有的点可达。那么该点所代表的连通分量上的所有的原图中的点,都能被原图中的所有点可达,则该连通分量的点数,就是答案。DAG上面如果有不止一个出度为 $0$ 的点,则这些点互相不可达,原问题无解,答案为 $0$
注:
缩点的时候不一定要构造新图,只要把不同强连通分量的点染不同的颜色,然后考察各种颜色的点(即其对应的缩点后的 DAG 上的点是否有出边)
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::vector;
using std::stack;
const int MX = 10005;
int dfn[MX], low[MX], idx;
bool inst[MX];
stack<int> st;
int cnt, scc[MX];
int out[MX];
vector<vector<int>> to;
void chmin(int &x, int y) { if (x > y) x = y; }
void tarjan(int u) {
dfn[u] = low[u] = ++idx;
st.push(u); inst[u] = 1;
for (int v : to[u]) {
if (dfn[v] == 0) {
tarjan(v);
chmin(low[u], low[v]);
}
else if (inst[v]) chmin(low[u], dfn[v]);
}
if (low[u] == dfn[u]) {
++cnt;
int v;
do {
v = st.top(); st.pop(); inst[v] = 0;
scc[v] = cnt;
} while (v != u);
}
}
int main() {
int n, m;
cin >> n >> m;
to.resize(n);
rep(i, m) {
int a, b;
cin >> a >> b;
--a; --b;
to[a].push_back(b);
}
rep(i, n) if (dfn[i] == 0) tarjan(i);
rep(u, n) {
for (int v : to[u]) {
if (scc[v] != scc[u]) {
out[scc[u]]++;
}
}
}
int tot = 0;
for (int i = 1; i <= cnt; ++i) {
if (out[i] == 0) ++tot;
}
if (tot > 1) cout << 0 << '\n';
else {
int ans = 0;
for (int i = 1; i <= cnt; ++i) {
if (out[i]) continue;
rep(j, n) if (scc[j] == i) ++ans;
}
cout << ans << '\n';
}
return 0;
}
例题3. King’s Quest
国王有 $n$ 个儿子,同时王国中有 $n$ 个女孩。每个王子都喜欢若干女孩。现在大臣给出了一个配对表,使得每个王子都和一个女孩结婚。国王想知道他的每个儿子可以和那些女孩结婚,使得他每个儿子仍然能选择到他喜欢的女孩结婚。
$n \leqslant 2000$
分析:
如果王子 $a$ 喜欢女孩 $b$,则建一条边从 $a$ 指向 $b$
对于大臣给出的配对表,王子 $a$ 和 $b$ 结婚,建一条从 $b$ 到 $a$ 的边
然后求强连通分量即可。
每个强连通分量中的王子数和女孩数一定是相同的。
因为初始的匹配表中,王子和女孩有两条方向相同的边可以互相到达。
对于每个王子和他喜欢的女孩,如果他们都在同一个强连通分量里,则他们一定能结婚。
对于强连通分量中的王子 $a$,如果他选择和另一个女孩 $x$ 结婚,女孩 $c$ 的原配王子 $b$肯定可以找到王子 $a$ 的原配女孩。
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::vector;
using std::stack;
const int MX = 4005;
int dfn[MX], low[MX], idx;
bool inst[MX];
stack<int> st;
int cnt, scc[MX];
vector<vector<int>> to;
void chmin(int &x, int y) { if (x > y) x = y; }
void tarjan(int u) {
dfn[u] = low[u] = ++idx;
st.push(u); inst[u] = 1;
for (int v : to[u]) {
if (dfn[v] == 0) {
tarjan(v);
chmin(low[u], low[v]);
}
else if (inst[v]) chmin(low[u], dfn[v]);
}
if (low[u] == dfn[u]) {
++cnt;
int v;
do {
v = st.top(); st.pop(); inst[v] = 0;
scc[v] = cnt;
} while (v != u);
}
}
int main() {
int n;
while (cin >> n) {
memset(dfn, 0, sizeof dfn);
memset(low, 0, sizeof low);
memset(scc, 0, sizeof scc);
int n2 = 2 * n;
to.clear();
to.resize(n2);
rep(i, n) {
int k;
cin >> k;
rep(j, k) {
int x; cin >> x; --x;
to[i + n].push_back(x);
}
}
rep(i, n) {
int a; cin >> a; --a;
to[a].push_back(i + n);
}
rep(i, n2) if (dfn[i] == 0) tarjan(i);
for (int i = n; i < n2; ++i) {
vector<int> v;
for (int j : to[i])
if (scc[j] == scc[i]) v.push_back(j + 1);
cout << v.size() << " ";
sort(v.begin(), v.end());
for (int x : v) cout << x << " ";
puts("");
}
}
return 0;
}
例题4. 学校网络
给定一个有向图,求:
- 至少要选几个顶点,才能做到从这些顶点出发,可以到达全部顶点
- 至少要加多少条边,才能使得从任何一个顶点出发,都能到达全部顶点
$N \leqslant 100$
分析:
有用的定理:
有向无环图中所有入度不为 $0$ 的点,一定可以由某个入度为 $0$ 的点出发可达。(由于无环,所以从入度不为 $0$ 的点出发往回走,必然终止于一个入度为 $0$ 的点)
解题思路:
- 求出所有强连通分量
- 把每个强连通分量缩成一点,则形成一个有向无环图
DAG DAG上面有多少个入度为 $0$ 的顶点,问题 $1$ 的答案就是多少
在 DAG上要加几条边,才能使得 DAG 变成强连通的,问题 $2$ 的答案就是多少
加边的方法:
要为每个入度为 $0$ 的点添加入边,为每个出度为 $0$ 的点添加出边
假定有 $x$ 个出度为 $0$ 的点,$y$ 个入度为 $0$ 的点, $\max(x, y)$ 就是第二个问题的解。
注:要特判只有一个强连通分量的情况
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::max;
using std::vector;
using std::stack;
const int MX = 105;
int dfn[MX], low[MX], idx;
bool inst[MX];
stack<int> st;
int cnt, scc[MX];
int in[MX];
int out[MX];
vector<vector<int>> to;
void chmin(int &x, int y) { if (x > y) x = y; }
void tarjan(int u) {
dfn[u] = low[u] = ++idx;
st.push(u); inst[u] = 1;
for (int v : to[u]) {
if (dfn[v] == 0) {
tarjan(v);
chmin(low[u], low[v]);
}
else if (inst[v]) chmin(low[u], dfn[v]);
}
if (low[u] == dfn[u]) {
++cnt;
int v;
do {
v = st.top(); st.pop(); inst[v] = 0;
scc[v] = cnt;
} while (v != u);
}
}
int main() {
int n;
cin >> n;
to.resize(n);
rep(i, n) {
int x;
while (cin >> x, x) {
--x;
to[i].push_back(x);
}
}
rep(i, n) if (dfn[i] == 0) tarjan(i);
rep(i, n) {
for (int j : to[i]) {
if (scc[j] != scc[i]) {
in[scc[j]]++;
out[scc[i]]++;
}
}
}
int tot = 0, tot2 = 0;
for (int i = 1; i <= cnt; ++i) {
if (in[i] == 0) ++tot;
if (out[i] == 0) ++tot2;
}
cout << tot << '\n';
int ans = max(tot, tot2);
if (cnt == 1) ans = 0;
cout << ans << '\n';
return 0;
}
例题5. 【模板】缩点
本题的一般做法如下:
- 缩点
- 建新图
- dp求最长链
dp 的方式可以有两种:
1) dp[u] 表示以 $u$ 为起点,所能得到的最大利益,$dp[u] = \max(dp[v] + s[u])$,其中 $u \to v$ 为一条有向边
边界为出度为 $0$ 的点,该点的 $dp$ 值等于 该点 $a$ 的值
2) dp[u] 表示以 $u$ 为终点所能得到的最大利益,$dp[u] = \max(dp[v] + s[u])$,其中 $u \to v$ 为一条有向边,边界为入度为 $0$ 的点,该点的 $dp$ 值等于 该点 $a$ 的值
注意到对 DAG 做拓扑排序后结果不唯一,所以自然可以是 SCC 编号的倒序,于是这时候我们用第一种 dp 方式比较方便。因为我们可以不用再建新图,直接在 Tarjan 里更新 dp值 即可。
Code:
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::max;
using std::vector;
using std::stack;
const int MX = 10005;
int dfn[MX], low[MX], idx;
bool inst[MX];
stack<int> st;
int cnt, scc[MX];
int a[MX], s[MX], dp[MX], ans;
vector<vector<int>> to;
void chmin(int &x, int y) { if (x > y) x = y; }
void chmax(int &x, int y) { if (x < y) x = y; }
void tarjan(int u) {
dfn[u] = low[u] = ++idx;
st.push(u); inst[u] = 1;
for (int v : to[u]) {
if (dfn[v] == 0) {
tarjan(v);
chmin(low[u], low[v]);
}
else if (inst[v]) chmin(low[u], dfn[v]);
}
int mx = 0;
if (low[u] == dfn[u]) {
++cnt;
int v;
do {
v = st.top(); st.pop(); inst[v] = 0;
scc[v] = cnt;
s[cnt] += a[v];
for (int x : to[v]) {
if (scc[x] != cnt) chmax(mx, dp[scc[x]]);
}
} while (v != u);
dp[cnt] = mx + s[cnt];
chmax(ans, dp[cnt]);
}
}
int main() {
int n, m;
cin >> n >> m;
rep(i, n) cin >> a[i];
to.resize(n);
rep(i, m) {
int u, v;
cin >> u >> v;
--u; --v;
to[u].push_back(v);
}
rep(i, n) if (dfn[i] == 0) tarjan(i);
cout << ans << '\n';
return 0;
}
Kosaraju 求强连通分量
求解有向图的强连通分量主要有两种算法:
Tarjan算法:DFS 一次原图Kosaraju算法:DFS 一次原图, DFS 一次逆图
这里我们介绍一种只需从某个顶点出发进行两次遍历:一次在原图上遍历,一次在逆图上遍历,就可以求出图中所有强连通分量的 Kosaraju 算法。
时间复杂度:$O(n + m)$
逆图
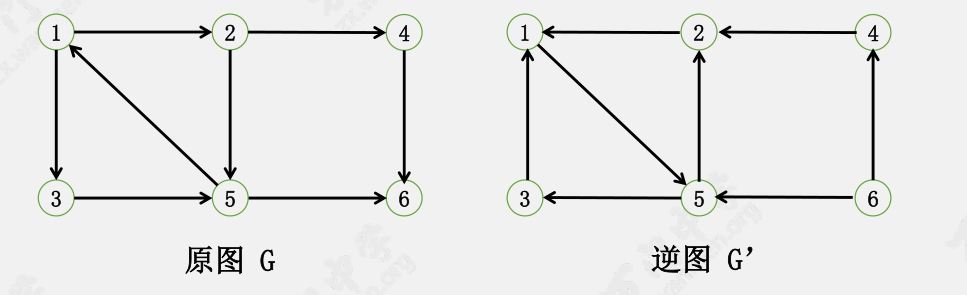
对于一个有向图 $G$,把 $G$ 中的所有边都反向,就得到了 $G$ 的逆图 $G’$。
Kosaraju 算法的思想
如果有向图 $G$ 的一个子图 $K$ 是一个强连通子图,那么把各边反向之后,不影响 $K$ 的强连通性。
但如果 $K$ 是单向连通的,各边反向后可能某些顶点间就不连通了。
Kosaraju 算法的过程
- 对原图 $G$ 进行 DFS,记录每个节点
DFS 结束的时间 dfn - 将 $G$ 中的每条边反向,得到逆图 $G’$
- 选择当前 $dfn$ 最大的顶点出发,对 $G’$ 进行 DFS,删除能够遍历到的点,这些点构成一个强连通分量。
- 如果还有顶点没有删除,就继续执行第 $3$ 步,否则算法结束
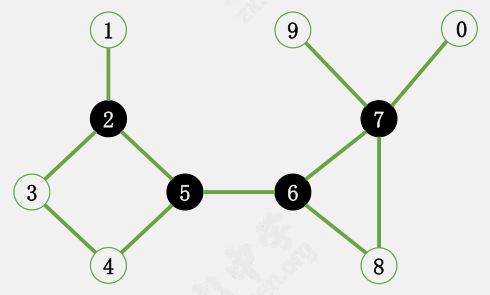
以这张图为例,我们来看看 Kosaraju 算法是如何运行的。
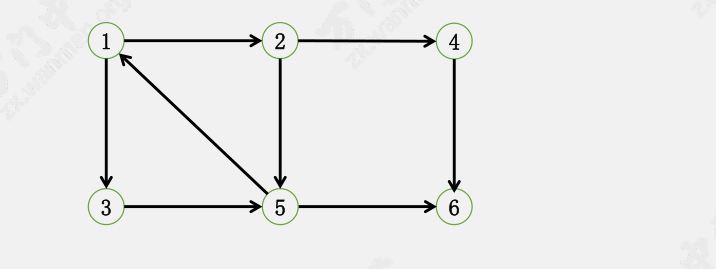
首先在 $G$ 上 DFS,记录每个点的 dfn
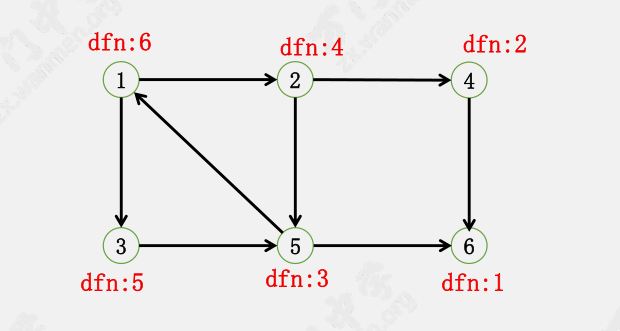
对逆图 $G’$ 进行 DFS,每次从 dfn 最大的开始 dfs。
这里从 $1$ 开始 DFS,得到 $\{1, 2, 3, 5\}$。
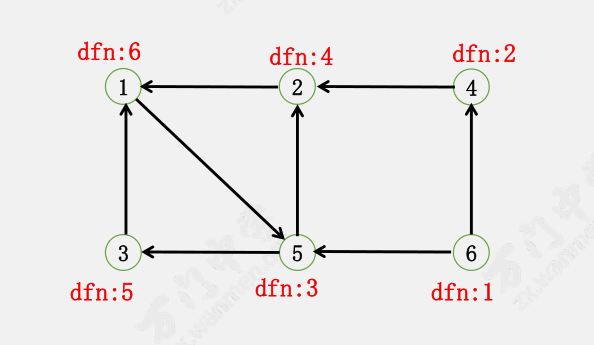
从 $4$ 开始 DFS,得到 $\{4\}$
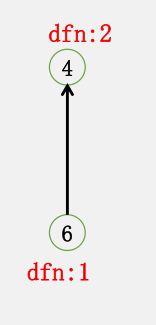
从 $6$ 开始 DFS,得到 $\{6\}$

因此只需要通过两遍 dfs 就可以求出所有的强连通分量:
$\{1, 2, 3, 5\}, \ \{4\}, \ \{6\}$
时间复杂度为 $O(n + m)$
Code:
bool vis[MX];
int color[MX], sccCnt;
vector<int> s;
vector<vector<int>> to, g;
void dfs(int u) {
vis[u] = true;
for (int v : to[u]) {
if (vis[v] == false) dfs(v);
}
s.push_back(u);
}
void rdfs(int u) {
color[u] = sccCnt++;
for (int v : g[u]) {
if (color[v] == -1) rdfs(v);
}
}
void Kosaraju() {
memset(color, -1, sizeof color);
for (int i = 0; i < n; ++i) {
if (vis[i] == false) dfs(i);
}
for (int i = n - 1; i >= 0; --i) {
if (color[s[i]] != -1) continue;
rdfs(s[i]);
sccCnt++;
}
}
例题6: ACL-SCC
Code:
#include <bits/stdc++.h>
#if __has_include(<atcoder/all>)
#include <atcoder/all>
using namespace atcoder;
#endif
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
int main() {
int n, m;
cin >> n >> m;
scc_graph g(n);
rep(i, m) {
int a, b;
cin >> a >> b;
g.add_edge(a, b);
}
auto ans = g.scc();
int k = ans.size();
cout << k << '\n';
rep(i, k) {
int l = ans[i].size();
cout << l << " ";
rep(j, l) cout << ans[i][j] << " \n"[j == l-1];
}
return 0;
}
三、无向图的点连通性
点连通性,顾名思义,就是与顶点有关的连通性。
研究无向图的点连通性,通常是通过删除无向图中的顶点(及与其所关联的每条边)后,观察和分析剩下的无向图连通与否。
割点集与顶点连通度
设 $V’$ 是连通图 $G$ 的一个顶点子集,若在 $G$ 中删除 $V’$ 与 $V’$ 关联的边后图不连通,则称 $V’$ 是 $G$ 的 割点集。
如果割点集 $V’$ 的任何真子集都不是割点集,则称 $V’$ 为 极小割点集。
顶点个数最小的极小割点集称为 最小割点集。
最小割点集中顶点的个数,称为图 $G$ 的 顶点连通度。
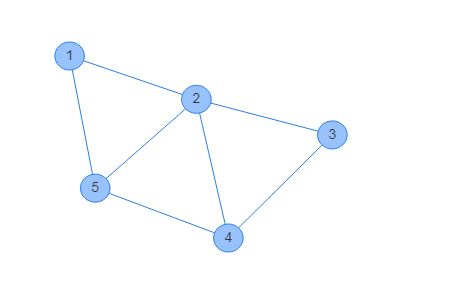
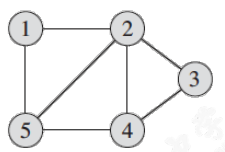
割点集:$\{1, 2, 4\}, \ \{2, 3, 5\}, \{2, 4\}, \ \{2, 5\}$
极小割点集:$\{2, 4\}, \ \{2, 5\}$
最小割点集:$\{2, 4\}, \ \{2, 5\}$
顶点连通度:$2$
割点
若割点集中只有一个顶点,则这个顶点可以称为 割点 或 关节点。
另一种定义:在一个无向图 $G$ 中,当删去 $G$ 中的某个顶点 $v$ 及其所关联的边之后,若图分成了两个或两个以上的连通分量,则称顶点 $v$ 为 割点 或 关节点。
点双连通图
如果一个无向图 $G$ 没有关节点(顶点连通度大于 $1$),则称 $G$ 为 点双连通图。
点双连通图,顾名思义,就是说这张图中任何一对顶点之间至少存在 $2$ 条无公共内部顶点(除了起点和终点)的路径。因此在删除任意一个顶点和其所关联的边时,也不会破坏图的连通性。
比如下图中,$1$ 到 $3$ 就有两条不相交的路径:$1 \to 2 \to 3, \ 1 \to 5 \to 4 \to 3$。
点双连通分量
一个连通图 $G$ 如果不是点双连通图,那么可以包含几个 点双连通分量。
一个连通图的点双连通分量是该图的极大点双连通子图,在点双连通分量中 不存在 关节点。
可以看出,割点可以属于 多个 点双连通分量,其余顶点属于且仅属于一个点双连通分量。
割点的求解
朴素做法
联系割点的定义,依次枚举每个顶点,删除它和与它相关联的边,然后遍历整个图,得到图的连通分量个数,如果大于等于 $2$,则该顶点就是割点。
时间复杂度:$O(n^3)$
Tarjan 算法求割点
这里我们介绍一种只需从某个顶点出发进行一次遍历,就可以求出图中所有割点的 Tarjan 算法。
时间复杂度:$O(n+m)$
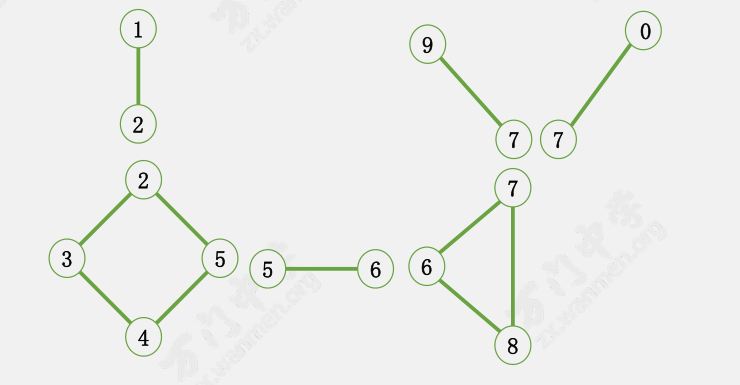
以这张图为例,我们来看看 Tarjan 算法是如何运行的。
首先,任选一个点进行 ${\rm DFS}$。
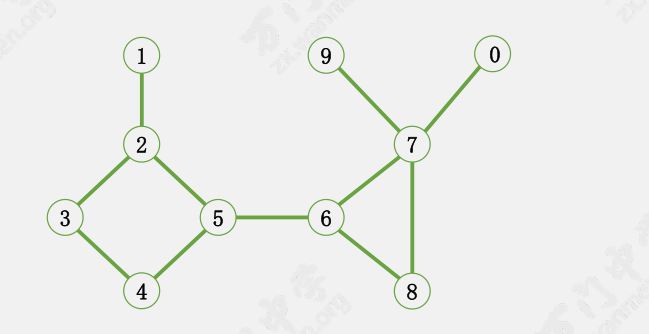
比如从 $5$ 号点开始 ${\rm DFS}$,按顺序经过:$5 \ 4 \ 3 \ 2 \ 1 \ 6 \ 8 \ 7 \ 0 \ 9$
根为 $5$ 的深度优先搜索生成树。
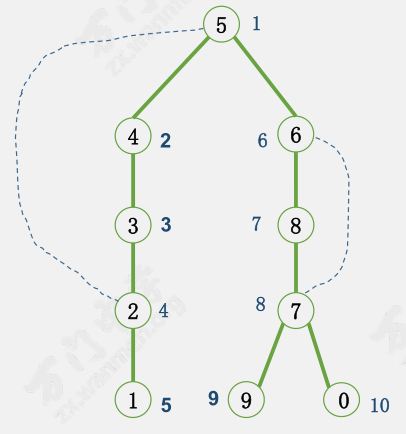
dfn[] 表示 ${\rm dfs}$ 时访问的顺序。
显然,在深度优先搜索生成树中,如果 $u$ 是 $v$ 的祖先,则一定存在 dfn[u] < dfn[v],表示 $u$ 比 $v$ 先被访问到。
重新回到原来的图 $G$。
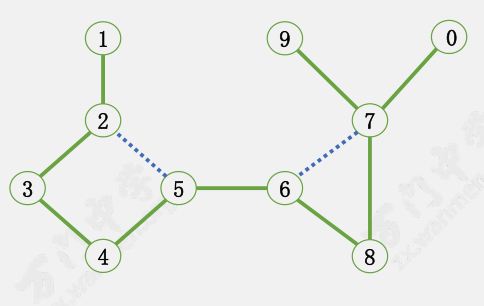
$G$ 中的边可以分为两种:
生成树的边。例如:$(4, 3)$,$(7, 9)$返向边。例如图中虚线表示的边 $(3, 5)$,$(6, 7)$
由 ${\rm DFS}$ 的性质可得,不存在除了上述两种边以外的边。
顶点 $u$ 是割点的充要条件 $(1)$
如果 $u$ 是深度优先搜索生成树的根,则 $u$ 至少有两个子女。
顶点 $u$ 是割点的充要条件 $(2)$
如果 $u$ 不是生成树的根,则它至少有一个孩子 $v$,从 $v$ 出发不可能通过 $v、v$ 的子孙,以及一条回边到达 $u$ 的祖先。
对 $G$ 中的每个顶点 $u$ 定义一个 $low$ 值,low[u] 表示从 $u$ 或 $u$ 的子孙出发通过返向边可以到达的最低深度优先数 $({\rm dfn})$
$ {\rm low}[u] = \min\{ {\rm dfn}[u], \min\{{\rm low}[v] \mid v \text{是} u \text{的一个孩子}\}, \min\{{\rm dfn}[v] \mid (u, v) \text{是一条返向边}\} \} $
综上所述,顶点 $u$ 是割点的充要条件是:$u$ 要么是具有两个以上子女的深度优先搜索树的根,要么存在一个 $u$ 的子节点 $v$ 使得 ${\rm low}[v] \geqslant {\rm dfn}[u]$
因此只需进行一次 ${\rm DFS}$,求出 ${\rm dfn}[ \ ]$ 和 ${\rm low}[ \ ]$,就可以一次性求出图中的全部割点。
代码实现
int dfn[N], low[N];
int b[N]; // 该点被断开会变成几个连通分量
bool vis[N];
int tot; // 给 dfn 编号
b[N] 数组用于统计去掉点 $u$,原来的连通图分成了几个连通分量。
如果 $u$ 是根节点,那么有几个子节点,就有几个连通分量。
如果 $u$ 不是根节点,那么如果有几个子节点 $v$ 满足 ${\rm low}[v] \geqslant {\rm dfn}[v]$,就有几个连通分量。
Tarjan 算法主体部分:
void tarjan(int v) {
vis[v] = true;
dfn[v] = low[v] = ++tot;
for (int u : to[v]) {
if (!vis[u]) {
tarjan(u);
low[v] = min(low[v], low[u]);
if (low[u] >= dfn[v]) b[v]++;
}
else {
low[v] = min(low[v], dfn[u]);
}
}
}
调用 Tarjan 算法:
for (int i = 1; i <= n; ++i) {
if (!vis[i]) {
tarjan(i);
b[i]--;
}
}
for (int i = 1; i <= n; ++i) {
cout << i << " " << b[i] + 1 << '\n';
}
在这张图上调用 Tarjan 算法:
输出:
1 1
2 2
3 1
4 1
5 2
6 2
7 3
8 1
9 1
0 1
例题1. 模板题: Articulation Points
C++ 代码
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using std::cin;
using std::cout;
using std::set;
using std::vector;
const int MX = 100005;
int dfn[MX], low[MX];
int b[MX]; // 该点被断开会变成几个连通分量
bool vis[MX];
int tot; // 给 dfn 编号
vector<int> to[MX];
inline void chmin(int& x, int y) { if (x > y) x = y; }
void tarjan(int v) {
vis[v] = true;
dfn[v] = low[v] = ++tot;
for (int u : to[v]) {
if (!vis[u]) {
tarjan(u);
chmin(low[v], low[u]);
if (low[u] >= dfn[v]) b[v]++;
}
else {
chmin(low[v], dfn[u]);
}
}
}
int main() {
int n, m;
cin >> n >> m;
rep(i, m) {
int u, v;
cin >> u >> v;
to[u].push_back(v);
to[v].push_back(u);
}
rep(i, n) {
if (!vis[i]) {
tarjan(i);
b[i]--;
}
}
set<int> ap;
rep(i, n) if (b[i] >= 1) ap.insert(i);
for (int v : ap) cout << v << '\n';
return 0;
}
点双连通分量的求解
首先可以用 Tarjan 算法求出图中的全部割点。
但是一个割点可能属于多个连通分量。
在 ${\rm DFS}$ 过程中,每找到一条生成树的边,就把这条边加入栈中。
如果遇到 ${\rm low}[v] \geqslant {\rm dfn}[u]$,说明 $u$ 是一个割点,同时把边从栈顶一条条取出,直到遇到边 $(u, v)$,取出这些边与其关联的顶点,组成一个点连通分量。
代码实现
建立一个栈存边
pair<int, int> st[N];
int top;
void tarjan(int u) {
vis[u] = true;
dfn[u] = low[u] = ++tot;
for (int v : to[u]) {
if (!vis[v]) {
st[++tot] = make_pair(u, v);
tarjan(v);
low[u] = min(low[u], low[v]);
if (low[v] >= dfn[u]) {
b[u]++;
while (1) {
auto [u2, v2] = st[top];
top--;
cout << u2 << " " << v2 << '\n';
if ((u2 == u and v2 == v) or (u2 == v and v2 == u)) break;
}
puts("");
}
}
else {
low[u] = min(low[u], dfn[v]);
}
}
}
四、无向图的边连通性
边连通性
边连通性,顾名思义,就是与边有关的连通性。
研究无向图的边连通性,通常是通过删除无向图中的若干条边后,观察和分析剩下的无向图连通与否。
割边集与边连通度
设 $E’$ 是连通图 $G$ 的边集的子集,若在 $G$ 中删除 $E’$ 后图不连通,则称 $E’$ 是 $G$ 的割边集。
如果割边集 $E’$ 的任何真子集都不是割边集,则称 $E’$ 为极小割边集。
边数最小的极小割边集称为最小割边集。
最小割边集中边的个数,称作图 $G$ 的边连通度。
割边集: $\{(1, 5), ~(2, 5), ~(4, 5)\}$,$\{(2, 3), (3, 4)\}$
极小割边集: $\{(1, 2), ~(2, 5), ~(5, 4)\}$
最小割边集: $\{(2, 3), ~(3, 4)\}$
边连通度: $2$
割边
若割边集中只有一条边,则这条边可以称为割边或桥。
另一种定义:在一个无向图 $G$ 中,当删去 $G$ 中的某条边 $e$ 之后,若图分成了两个或两个以上的连通分量,则称 $e$ 为割边或桥。
边双连通图
如果一个无向图 $G$ 没有桥(边连通度大于 $1$),则称 $G$ 为边双连通图。
边双连通图,顾名思义,就是说这张图中任何一对顶点之间至少存在 $2$ 条无公共边的路径。因此,在删除任意一条边时,也不会破坏图的连通性。
比如下图中,$1$ 到 $3$ 就有两条不相交的路径:$1 \to 2 \to 3$,$1 \to 5 \to 4 \to 3$
边双连通分量
一个连通图 $G$ 如果不是边双连通图,那么它可以包含几个边双连通分量。
一个连通图的边双连通分量是该图的极大边双连通子图,在该边双连通分量中不存在桥。

可以看出,在连通图中,把割边删除,则连通图变成了多个连通分量,每个连通分量就是一个边双连通分量。

割边和边双连通分量的求解
朴素做法
联系割边的定义,依次枚举每条边,删除它,然后遍历整个图,得到图的连通分量个数,如果大于 $2$,则这条边就是割边。
时间复杂度:$O(n^3)$
Tarjan 算法求割边
与之前求割点的 $Tarjan$ 算法类似,我们只要稍作改动,就可以同样通过一次遍历,求出图中所有的割边。
时间复杂度:$O(n+m)$
以这张图为例,我们来看看 $Tarjan$ 算法是如何运行的。
首先,任选一个点进行 $\operatorname{DFS}$
比如从 $5$ 号点开始 $\operatorname{DFS}$,按顺序经过 $5 ~4 ~3 ~2 ~1 ~6 ~8 ~7 ~0 ~9$

根为 $5$ 的深度优先搜索生成树。

dfn[] 表示 $\operatorname{dfs}$ 时访问的顺序
显然,在深度优先搜索生成树中,如果 $u$ 是 $v$ 的祖先,则一定存在 dfn[u] < dfn[v],表示 $u$ 比 $v$ 先被访问到。
对 $G$ 的每个顶点 $u$ 定义一个 low 值,low[u] 表示从 $u$ 或 $u$ 的子孙出发通过返向边可以到达的最低深度优先数 $(\operatorname{dfn})$ 。
low[u] = min{ dfn[u],
min{ low[v] | v 是 u 的一个孩子},
min{ dfn[v] | (u, v) 是一条返向边}
}
Tarjan 算法求割点回顾
顶点 $u$ 是割点的充要条件:
- 如果 $u$ 是深度优先搜索生成树的根,则 $u$ 至少有两个孩子
- 如果 $u$ 不是生成树的根,则它至少有一个孩子 $v$,从 $v$ 出发不可能通过 $v$、$v$ 的子孙,以及一条回边到达 $u$ 的祖先。
$u$ 要么是具有两个以上孩子的深度优先生成树的根,要么存在一个 $u$ 的子节点 $v$ 使得 $\operatorname{low}[v] \geqslant \operatorname{dfn}[u]$
$(u, v)$ 是割边的充要条件:
- $(u, v)$ 是生成树边
- 对于 $u$ 的孩子 $v$,从 $v$ 出发不可能通过 $v$、$v$ 的子孙,以及一条回边到达 $u$ 或 $u$ 的祖先。
$(u, v)$ 为生成树中的边,且 $\operatorname{dfn}[u] < \operatorname{low}[v]$
Tarjan 算法求割点和割边的比较
割点:
$u$ 要么是具有两个以上孩子的深度优先生成树的根,要么存在一个 $u$ 的子节点 $v$ 使得 $\operatorname{low}[v] \geqslant \operatorname{dfn}[u]$
割边:
$(u, v)$ 为生成树中的边,且 $\operatorname{dfn}[u] < \operatorname{low}[v]$
边双连通分量的求解
与点双连通分量的求解相比,边双连通分量的求法十分简单。
只要在求出所有桥之后,把桥删除,原图就变成了多个连通块,每个连通块就是一个边双连通分量。
桥不属于任何一个边双连通分量,其余的边和顶点都只属于一个边双连通分量。
五、二分图匹配
- 二分图:可以将点分为两个集合,每个集合内的点没有边相连
- 图的匹配:选出一些边,其中任意两条边无公共顶点
- 完美匹配:包含所有点的匹配
二分图又称作二部图,是图论中的一种特殊模型。
设 $G = (V, E)$ 是一个无向图,如果顶点 $V$ 可分割为两个互不相交的子集 $(A, B)$,并且图中的每条边 $(i, j)$ 所关联的两个顶点 $i$ 和顶点 $j$ 分别属于这两个不同的顶点集 (i in A, j in B),则称图 $G$ 为一个二分图。
通俗叫法:把图的点集分成两部分,每条边都连接这两个部分,每个部分都无连边。
二分图判定法
根据定义,每条边的两端点都应该在不同的子集中。不妨假设图 $G$ 是连通图(否则,对每个连通分量考虑,原理一致),随意选取一个点,令它属于子集 $A$。然后以它为起点进行 $\rm{dfs}$,搜索到的新点全部划入另一个子集。如果在此过程中发现一个邻接点已经划入了和当前点一样的子集,则此图/此连通分量不是二分图。如果判断成功,还能够求出二分的结果。
此外,二分图还有一个等价定义:不含有“含奇数条边的环”的图,在此不再详细证明。此处说的环,在离散数学中准确的称呼应该是“圈”(离散数学中的“环”均指自环)。
vector<int> color(n, -1);
void dfs(int v, int c=0) {
if (color[v] != -1) return;
color[v] = c;
int nc = c^1;
for (int u : to[v]) {
dfs(u, nc);
}
}
二分图匹配
二分图的匹配就是二分图 $G$ 的一个边集,其中任意两条边都没有公共顶点。
通俗理解:子集 $A$ 为男生,子集 $B$ 是女生,一一配对组成男女朋友关系。每个人最多只有一个男/女朋友,也有可能没有。每条边表示一个恋爱关系。
二分图中,所含边数最多的匹配即为此图的最大匹配。最大匹配不是唯一的(但是最大匹配数是唯一的)。
相关概念:在匹配中的边称为匹配边,否则称为非匹配边。匹配边的顶点称为匹配点,否则称为非匹配点。
匈牙利算法
匈牙利算法是求二分图最大匹配的算法。
先给出一些关键概念
交错路径:给定图 $G$ 的一个匹配 $M$。如果一条路径的边交替出现在 $M$ 中,则称此路径为 $M$ 的交替路径。(在-不在-在-不在-…)
增广路径:对于 $M$ 的一条交错路径,如果它的两个端点都不与 $M$ 中的边关联,就称它为 $M$ 中的增广路径。即:两端端点都还未匹配。
增广路径的两端都是未匹配的点,由此可以推出,此路径的边数为奇数。如下图所示:
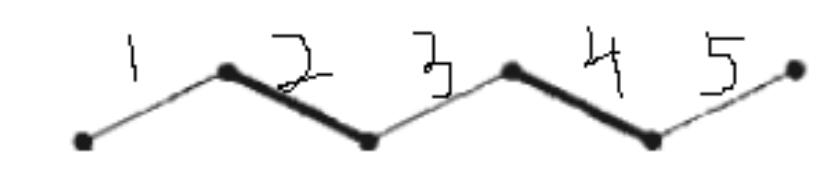
图中加粗的 2 4 号边为 $M$ 中的边,1 3 5 不是 $M$ 中的边。 取奇数号边也可以形成一个匹配,而且匹配数比原来大 $1$。在上图中,放弃 2 4 号边,选择 1 3 5 号边,则得到一个更大的匹配(匹配数为 $3$)。
那么在上图的基础上,两个端点如果能再各发现一条边,以拓展增广路径,如下图所示:
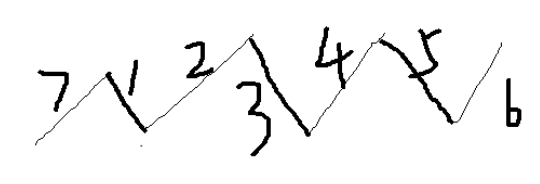
在拓展之前,我们以 1 3 5 号边为最大匹配;拓展完成后,我们发现了新的匹配(7 2 4 6 号边,$4$ 条边)。所以,只要能不断拓展增广路径,就能不断发现新的最大匹配。如果找不到更长的增广路径,就说明已经得到了最大匹配。这就是匈牙利算法的核心思路。它通过不断寻找增广路径的方法,求出最大匹配。
具体的实现方法:在已有的匹配基础上,尝试添加新的匹配。如果和原本的匹配不得不冲突,就尝试拆散原有的匹配,重新连边。如果能达成一条新的匹配边,而原本在匹配中的点依然都还能找到新的匹配边,那么匹配数 +1
可以用 $\operatorname{DFS}$ 或 $\operatorname{BFS}$ 来实现
伪代码:
bool 寻找从 k 出发的对应项出的可增广路 {
while (从邻接表中列举 k 能关联到顶点 j) {
if (j 不在增广路上) {
把 j 加入增广路
if (j 是未匹配点 或者 从 j 的对应项出发有可增广路) {
修改 j 的对应项为 k
从 k 的对应项有可增广路,返回 true
}
}
}
从 k 的对应项出发没有可增广路,返回 false
}
void 匈牙利hungary {
for i -> 1 to n {
if (从 i 的对应项出发有可增广路)
匹配数++
}
输出匹配数
}
例题:【模板】二分图最大匹配
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 1; i <= (n); ++i)
using namespace std;
const int MX = 505;
vector<int> to[MX];
bool used[MX]; // 点 i 是否在增广路上
int seat[MX]; // 点 i 是否是匹配点
bool find(int v) {
for (int u : to[v]) {
if (!used[u]) {
used[u] = true;
if (!seat[u] or find(seat[u])) { // 第二个条件表示 u 可以找到其他可配对的点,即 u 当前所配对的点可以让出
seat[u] = v;
return true;
}
}
}
return false;
}
int main() {
int n, m, e;
cin >> n >> m >> e;
rep(i, e) {
int u, v;
cin >> u >> v;
to[u].push_back(v);
}
int ans = 0;
rep(i, n) {
memset(used, false, sizeof used);
if (find(i)) ans++;
}
cout << ans << '\n';
return 0;
}
六、欧拉图
欧拉回路
无向图:
- 设 $G$ 是无向连通图,则称经过 $G$ 的每条边一次且仅一次的路径为
欧拉通路 - 如果欧拉通路是回路(起点和终点是同一个顶点),则称此回路为
欧拉回路 - 具有欧拉回路的无向图 $G$ 称为
欧拉图

有向图:
- 设 $D$ 是有向图, $D$ 的基图(不考虑方向)连通,则称经过 $D$ 的每条边一次且仅一次的有向路径称为
有向欧拉通路 - 如果有向欧拉通路是有向回路,则称此有向回路为
有向欧拉回路 - 具有有向欧拉回路的有向图 $D$ 称为
欧拉图

定理及推论
【定理1】 无向图 $G$ 存在欧拉通路的充要条件是:$G$ 为连通图,并且 $G$ 仅有两个奇度顶点或者无奇度顶点。
【推论1】 当 $G$ 仅有两个奇度顶点的连通图时,$G$ 的欧拉通路必以此两个节点为端点。
【推论2】 当 $G$ 是无奇度顶点的连通图时,$G$ 必有欧拉回路。
【推论3】 $G$ 为欧拉图(存在欧拉回路)的充要条件是 $G$ 无奇度顶点。
【定理2】 有向图 $G$ 存在欧拉通路的充要条件是:$D$ 为有向图,$D$ 的基图连通,并且所有顶点的出度和入度都相等;或者除两个顶点外,其余顶点的出度和入度都相等,而这两个顶点中, 一个顶点的出入度差为 $1$,另一个顶点的出入度差为 $-1$
【推论4】 当 $D$ 中的所有顶点出入度都相等时,$D$ 中存在有向欧拉回路
哥尼斯堡七桥问题
一条河流及其两条分支将哥尼斯堡市分成了 $4$ 个区,各区之间共有 $7$ 座桥梁连接着。问题:能不能一次走遍所有的 $7$ 座桥,并且每座桥只能经过一次?

存在 $4$ 个奇点,所以不能
一笔画问题
判断一个图 $G$ 是否可以一笔画出
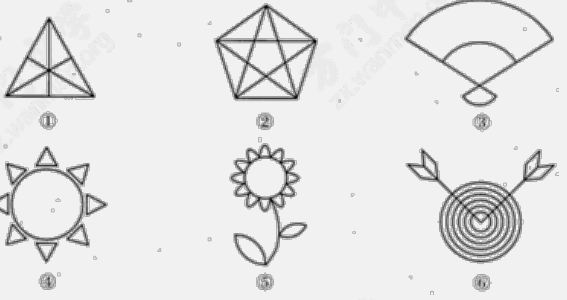
不可以:$(1), \ (4), \ (5), \ (6)$
欧拉回路问题
欧拉回路一般存在以下两类问题:
- 欧拉回路的判定问题:判断是否存在欧拉回路/有向欧拉回路
- 欧拉回路的求解:判断出存在之后,如何输出一条欧拉回路、有向欧拉回路
DFS 求解欧拉回路
欧拉回路的求解
欧拉回路的求解方法注意有两种:
- $\rm DFS$ 搜索
- $\rm Fleury$ 算法
DFS 搜索求解欧拉回路
用 $\rm DFS$ 搜索思想求解欧拉回路的思路为:
- 利用欧拉定理判断出一个图存在欧拉通路或欧拉回路。
- 选择
一个正确的起始顶点,用 $\rm DFS$ 算法遍历所有的边(每条边只遍历一次),遇到走不通就回退。 - 在搜索前进方向上将遍历过的边
按顺序记录下来。 - 这组边的排列就组成了一条欧拉通路或欧拉回路
例题:多米诺骨牌
给定 $n$ 张骨牌,每张骨牌有左右两个点数(从 $1$ 到 $6$)。问能不能通过交换骨牌的顺序和交换左右两个点数,使得任意两个相邻骨牌的相邻段为相等的数字。
样例:
原式: (1 2) (2 4) (2 4) (6 4) (2 1)
重排后:(4 2) (2 1) (1 2) (2 4) (4 6)
分析:
本题可以转化成欧拉回路或欧拉通路的求解问题。
首先要构造一个图?
每张骨牌当一个点?
如何解决交换骨牌内保部两个点数?
考虑用点数当点(共 $6$ 个点),每张牌对应一条无向边
无向正好说明是可以内部左右交换!
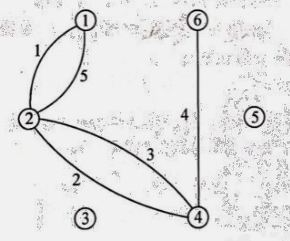
图建好之后,先判断是否存在欧拉通路或欧拉回路。
存在 $\Rightarrow$ 选择正确的点 $\Rightarrow 6 \Rightarrow$ 开始 $\rm DFS$
七、最短路径树
从源点 $S$ 出发,可以计算到达每个点的最短路。如果用 Dijkstra 算法,跑最短路的时候,顺便记录一下每个点的最短路,是被哪条边更新的。那么这些边加起来,组成了一个以 $S$ 为根的树,这个树就叫做最短路树。
树上从 $S$ 出发到任何点的路径,都是最短路。
例题: Berland and the Shortest Paths
练习题
- 01Sequence (差分约束系统)
强连通分量: - The Cow Prom (强连通分量)
- 从u到v还是从v到u? (强连通+拓扑排序)
- 最优贸易
- 消息扩散
点双连通分量: - 【模板】割点(割顶)
二分图匹配: - 二分图

# nice
# nice