
wordcount.py
text = """
Got this panda plush toy for my daughter's birthday,
who loves it and takes it everywhere. It's soft and
super cute, and its face has a friendly look. It's
a bit small for what I paid though. I think there
might be other options that are bigger for the
same price. It arrived a day earlier than expected,
so I got to play with it myself before I gave it
to her.
"""
import re
from collections import defaultdict
def wordcount(text):
text = text.lower()
text = re.sub("[^a-z']", " ", text)
words = re.split(' +', text)
cnt = defaultdict(int)
for word in words:
if word:
cnt[word] += 1
print(cnt)
if __name__ == '__main__':
wordcount(text)
# 输出结果
{'got': 2, 'this': 1, 'panda': 1, 'plush': 1, 'toy': 1, 'for': 3, 'my': 1, "daughter's": 1, 'birthday': 1, 'who': 1, 'loves': 1, 'it': 5, 'and': 3, 'takes': 1, 'everywhere': 1, "it's": 2, 'soft': 1, 'super': 1, 'cute': 1, 'its': 1, 'face': 1, 'has': 1, 'a': 3, 'friendly': 1, 'look': 1, 'bit': 1, 'small': 1, 'what': 1, 'i': 4, 'paid': 1, 'though': 1, 'think': 1, 'there': 1, 'might': 1, 'be': 1, 'other': 1, 'options': 1, 'that': 1, 'are': 1, 'bigger': 1, 'the': 1, 'same': 1, 'price': 1, 'arrived': 1, 'day': 1, 'earlier': 1, 'than': 1, 'expected': 1, 'so': 1, 'to': 2, 'play': 1, 'with': 1, 'myself': 1, 'before': 1, 'gave': 1, 'her': 1}
Debug 过程
wordcount算法步骤:
- 去掉标点符号
- 转为小写
- 分成单词
- 统计单词
完成初步代码并运行:
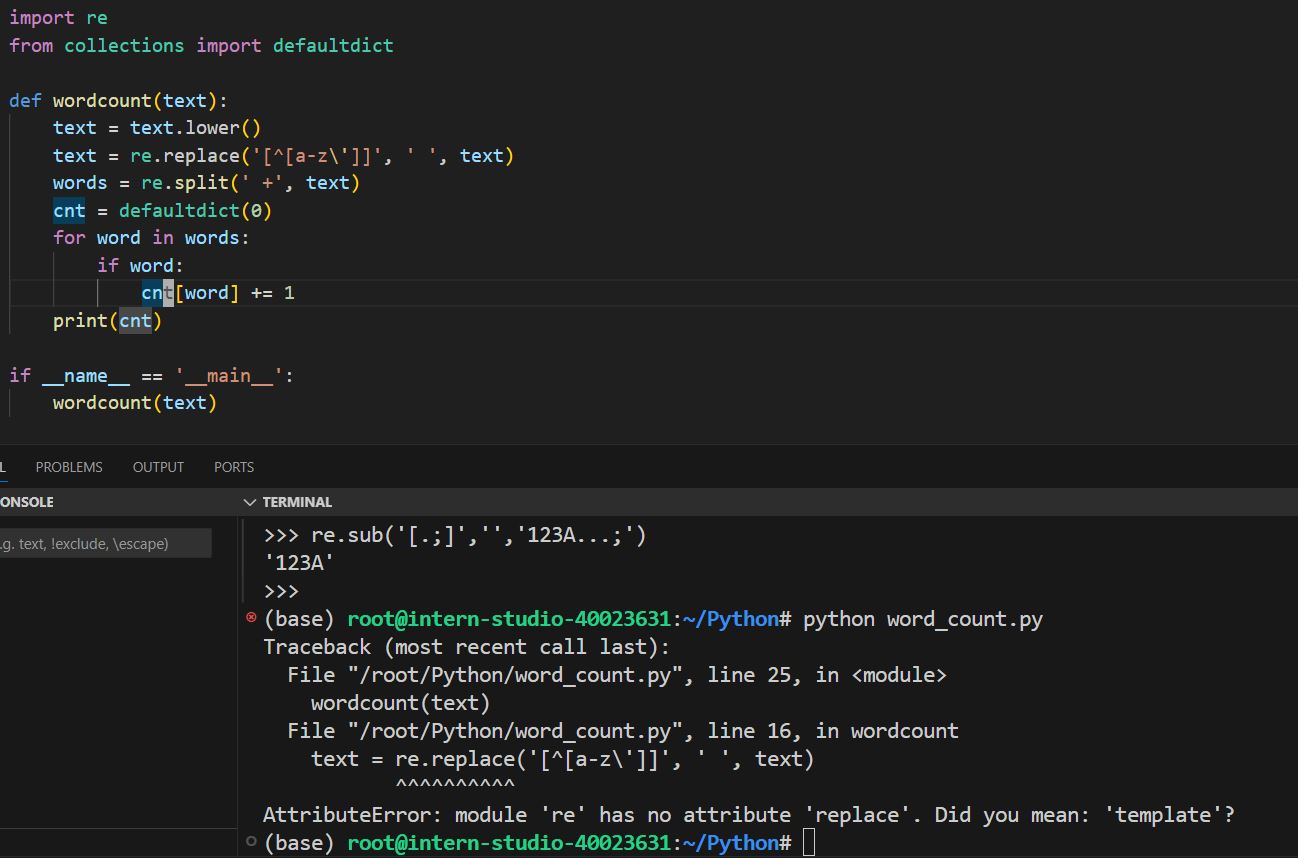
提示有API错误,根据提示进行多次修改
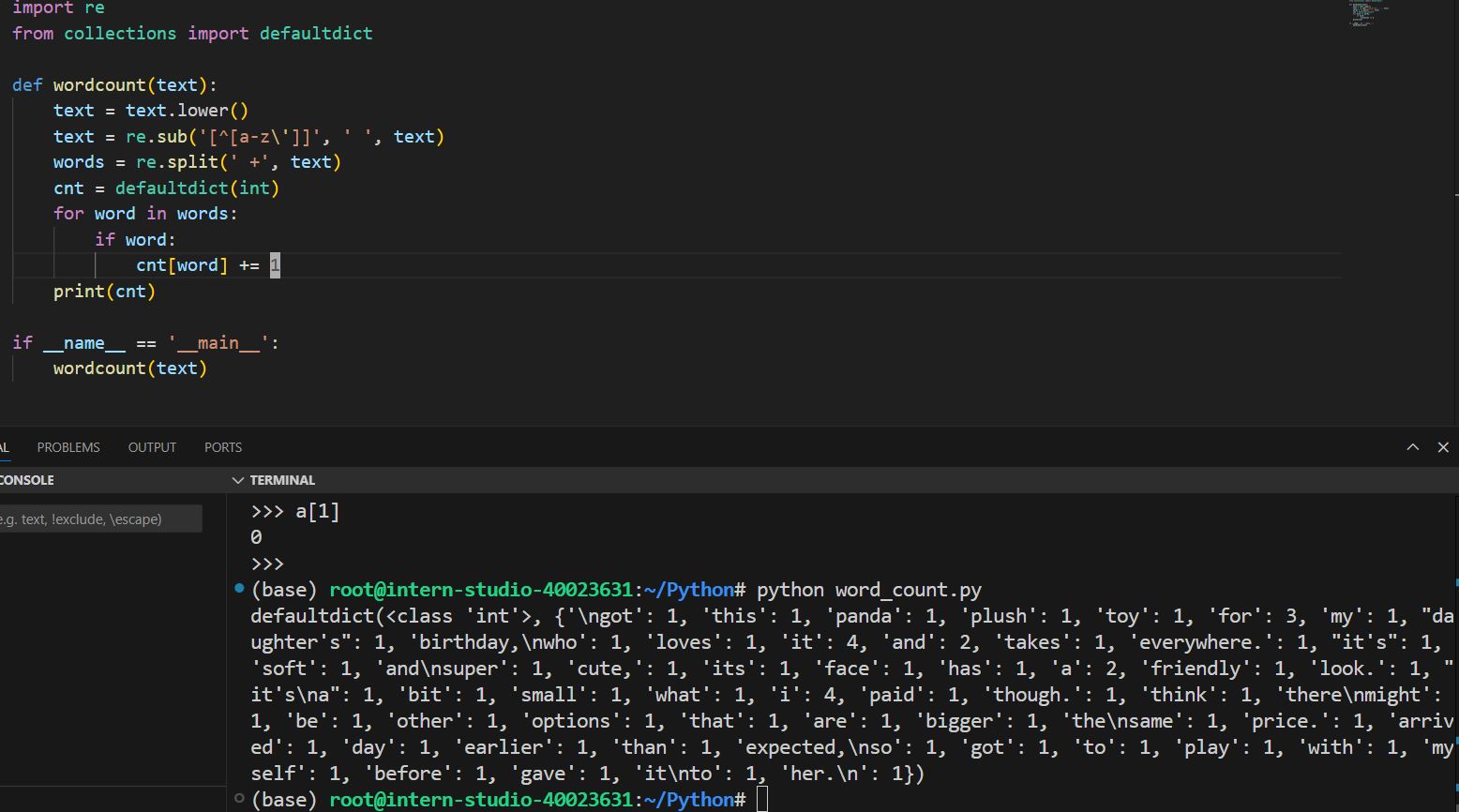
正常运行后发现替换代码没有生效,正则表达式写法有问题,修改正则表达式
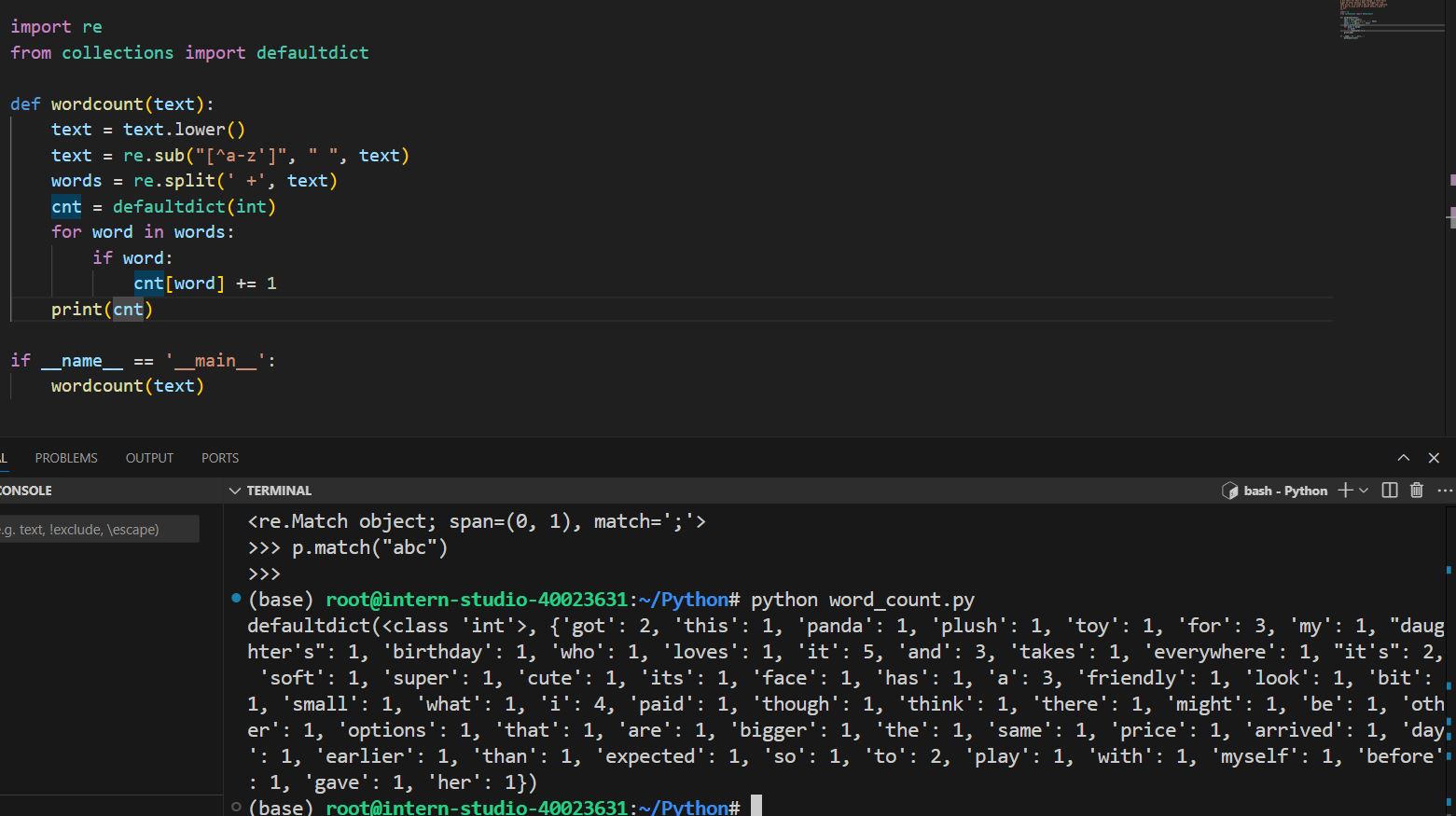
修改后虽然输出了字典,但是还有defaultdict,再修改一下输出内容,最后便得到以上答案
