
ok我们开始整一下GRU。
啥是gru——直觉的问题。
GRU(gated recurrent unit)可以看做是将LSTM中的forget gate和input gate合并成了一个update gate。
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
还是一脸懵,我们还是再去通俗探索一下。
GRU全称是Gate Recurrent Unit,叫门循环单元?(直译哈哈哈)
GRU和LSTM的表现基本是持平的,那问题来了,为啥用GRU更多了?
一句核心优势:选择GRU是因为它的实验效果与LSTM相似,但是更易于计算,也就是资源消耗少。
那么我们直觉是,gru资源消耗小的情况下还能达到很好的效果,必然和模型架构有关系。
就需要我们去探索一下gru的模型架构了。
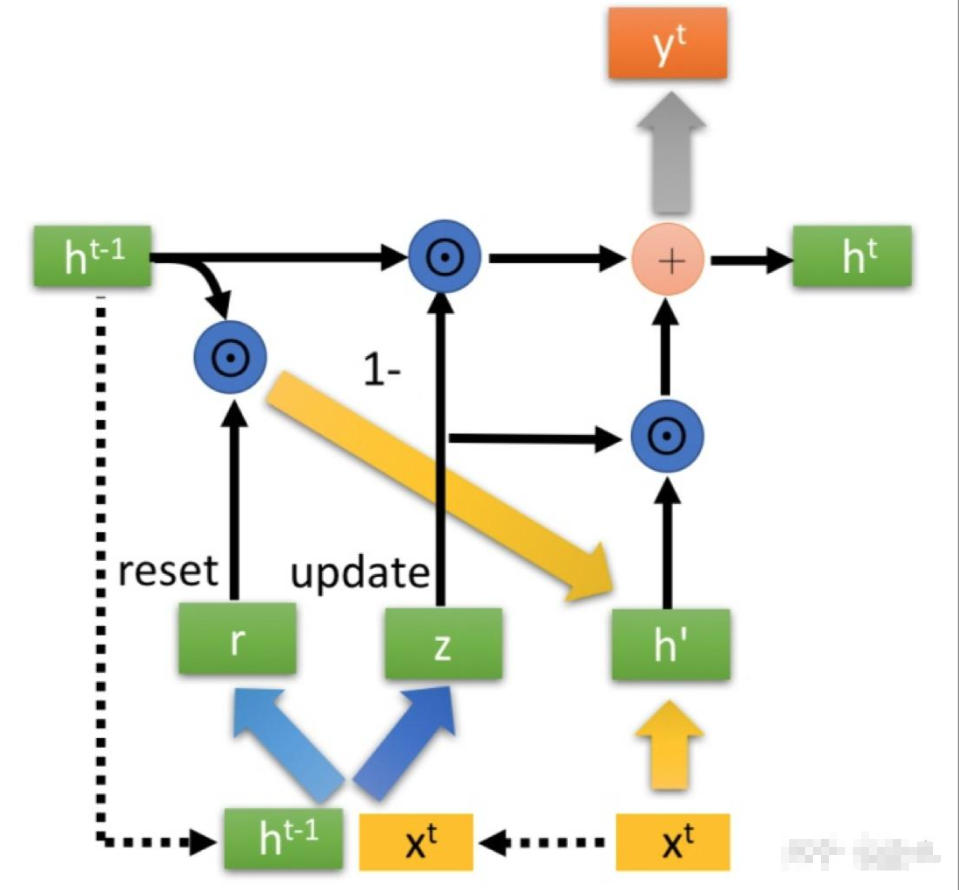
- 先用一个重置门控reset gate,将上一个单元的隐藏状态$h_{t-1}$进行重置,得到$h_{t-1}’$。
- 重置后的$h_{t-1}’$与当前的输入$x_t$进行拼接,再过一个tanh函数将数据放缩控制到[-1,1]。得到了h’。这个过程有点儿类似lstm的选择记忆阶段。
- 最重要的更新记忆阶段来了。用更新门z来控制下面:
$$h^t=(1-z)\odot h^{t-1}+z\odot h^{\prime}$$
这个过程同时完成了lstm中的遗忘阶段和记忆阶段。我们对这个公式进行详细解释论述。
-门控信号z的范围因为是过了一个sigmoid函数,所以值的范围一定是0-1。门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
-1-z的部分是用来表示对原本隐藏状态的选择性“遗忘”,很类似lstm中的forget门的作用。目的就是为了忘记上一阶段隐藏层中不重要的信息。
-z的部分,表示对当前节点隐藏层信息的选择性记忆。
-1-z的部分和z的部分进行叠加的意义,就是忘记传递过来$h_{t-1}$的部分信息,并加进来当前节点输入的重要信息。
-这里我们注意到,1-z和z其实是相互牵制和影响的,我要忘记传递过来的1-z的部分,那么就需要记住新输入的z的部分,达到一种动态平衡的效果,而lstm的门控机制都是相互独立,互不影响的。
那么明确了gru的架构,我们始终觉得gru和lstm有种很相似的感觉,有千丝万缕的联系。其实就是这样的,架构很像,那么我们看看有没有对应的关系。
- gru中的rest gate的作用,其实最重要的作用是为了得到$h’$,类似lstm中先计算得到z,但更像lstm中用来计算得到$h_t$的那个隐藏层状态。
- gru中的$h_{t-1}$类似lstm中的上一个cell中的内容。
- gru的1-z的门控类似lstm中的forget gate遗忘门,那么z其实类似lstm中的选择门$z_i$
GRU就到这里啦!
