
传统的RNN是单向的,对于某一个word是有左侧的上文,而没有右侧的下文,这也是语言模型的特点,从左往右看。为了克服这一局限性,可以用双向(bidirectional)的RNN,以下面一个情感分类的问题为例看一下。
对于the movie was terribly exciting这句话进行情感的积极与消极二分类的话,如果我们只看到terribly的上文,我们会认为这是一个负面的词,但如果结合下文exciting,就会发现terribly是形容exciting的激烈程度,在这里是一个很正面的词,所以我们既要结合上文又要结合下文来处理这一问题。我们可以用两个分别从前向后以及从后向前读的RNN,并将它们的隐藏向量联结起来,再进行sentiment的classification,其结构如下:
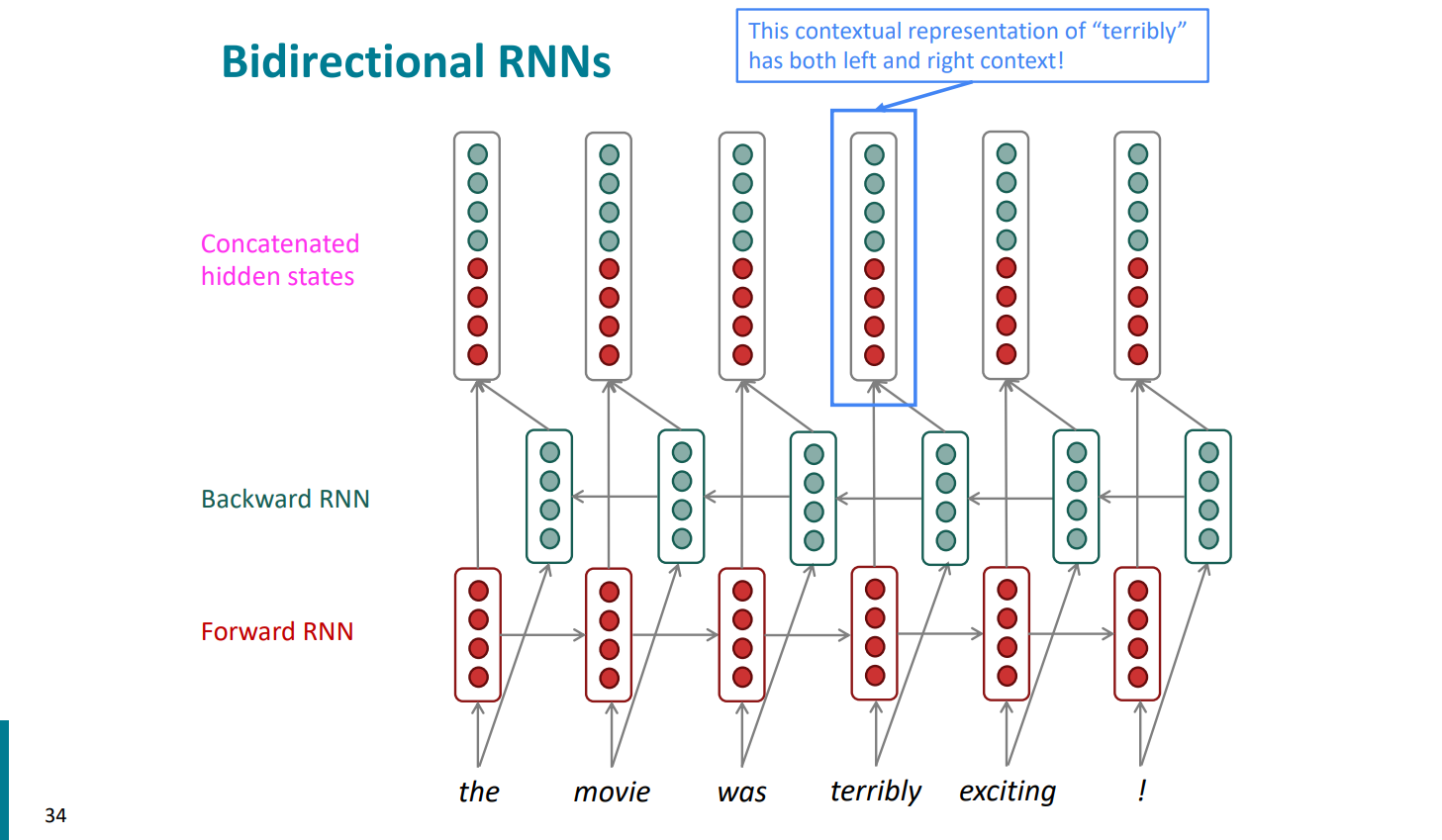
同时,正向和反向的rnn的参数是独立的,也就是合并了两套参数。

到这儿,可能我们会有疑问,那这样这个bi-rnn这么好,为啥还是单向rnn巨多?为啥不全用bi-rnn?
其实原因很明显,那就是bi-rnn有应用的局限性。
我们要想用双向rnn,必须满足:
我们能获取全部的输入序列。
这个条件很苛刻,首先就不能适用语言模型,因为LM就是只有左侧信息的时候使用。
当然我们如果有了全部的input sequence,那么就可以不用犹豫使用bidirectionality的思想。
If you do have entire input sequence (e.g., any kind of encoding), bidirectionality is
powerful (you should use it by default).
这个思想最强的,当属BERT(Bidirectional Encoder Representations from Transformers)
其他的rnns,比如Multi-layer RNNs。
我们的rnn都是在 timesteps的维度上很deep,那么还可以在数量上deep哈哈。结构如下:
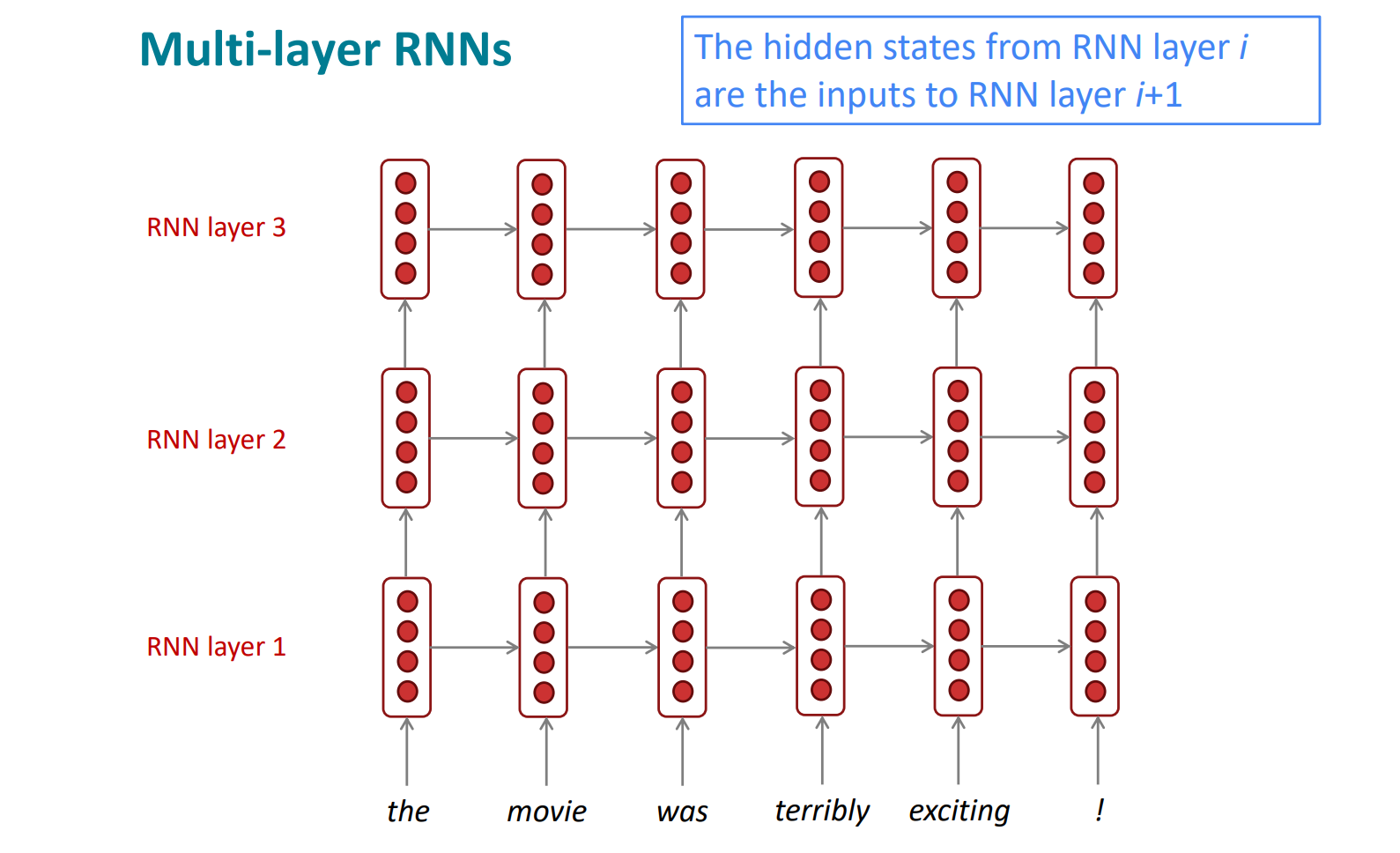
多层的rnn,通常表现都比单层的rnn效果好。
以机器翻译任务为例,展示一个rnn的sequence-to-sequence的模型
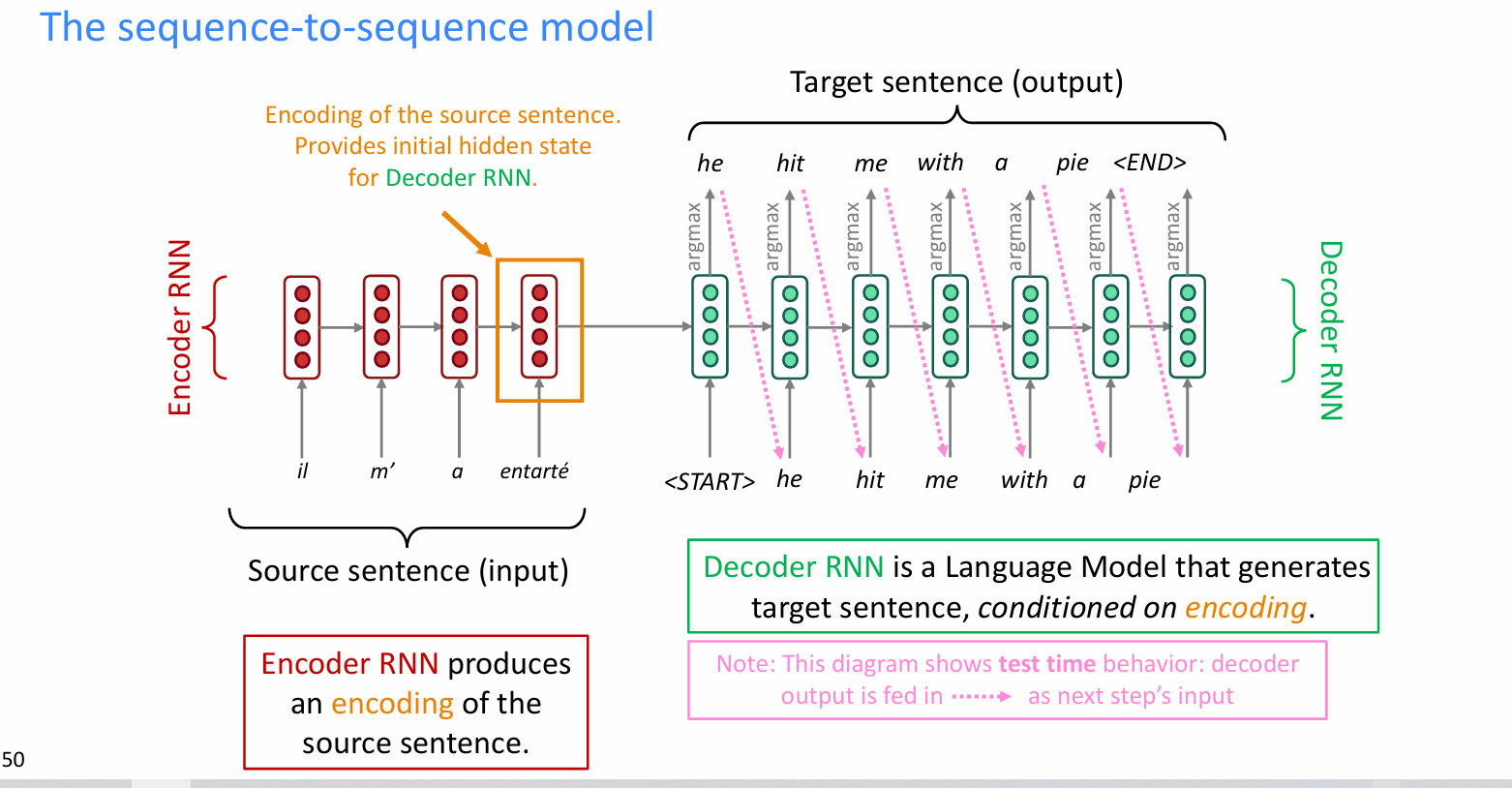
- 一般的encoder是为decoder提供最初的隐藏层信息,并且为源输入提供一个编码。
- 解码器是基于编码信息,生成目标sequence。且decoder的每一个输出都作为下一步decoder的输入。
这里简答说一下关于sequence-to-sequence的知识:

sequence-to-sequence的模型可以应用到很多的任务,远不止机器翻译。比如摘要,对话,语法语义解析,代码生成。

sequence-to-sequence模型其实也是条件语言模型的一种。原因如下:
- “条件”:encoder的representation是基于输入x的。
- “语言模型”:decoder是去预测下一个word的,从而形成最终的输出y。
通过一个RNN作为encoder将输入的源语言转化为某表征空间中的向量,再通过另一个RNN作为decoder将其转化为目标语言中的句子。我们可以将decoder看做预测目标句子$y$的下一个单词的语言模型,同时其概率依赖于源句子的encoding。
计算的方法也是很经典的概率乘积表示:
$$P(y|x)=P(y_1|x) P(y_2|y_1,x) P(y_3|y_1,y_2,x)\ldots P(y_T|y_1,\ldots,y_{T-1},x)$$
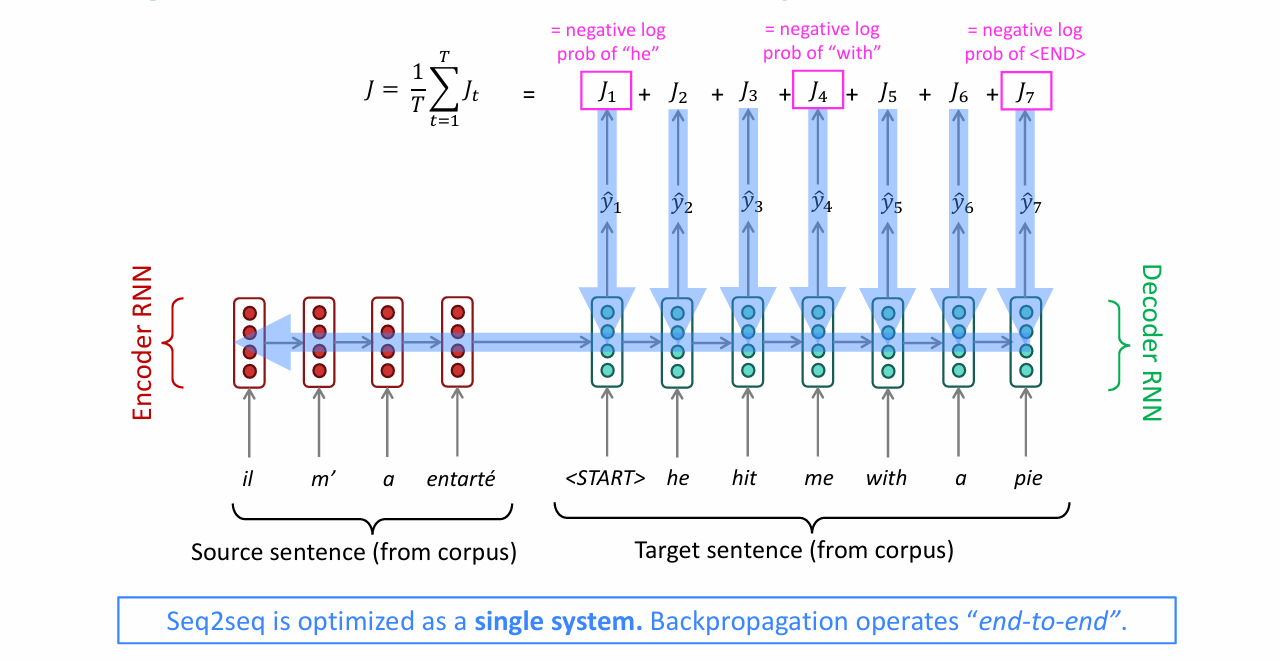
训练过程中,损失函数与语言模型中类似,即各步中目标单词的log probability的相反数的平均值:
$$J(\theta)=\frac1T\sum_{t=1}^TJ^{(t)}(\theta)=\frac1T\sum_{t=1}^T-\log\hat{\boldsymbol{y}}_{\boldsymbol{x}_{t+1}}^{(t)}$$
在做inference的时候,我们可以选择greedy decoding即每一步均选取概率最大的单词并将其作为下一步的decoder input。
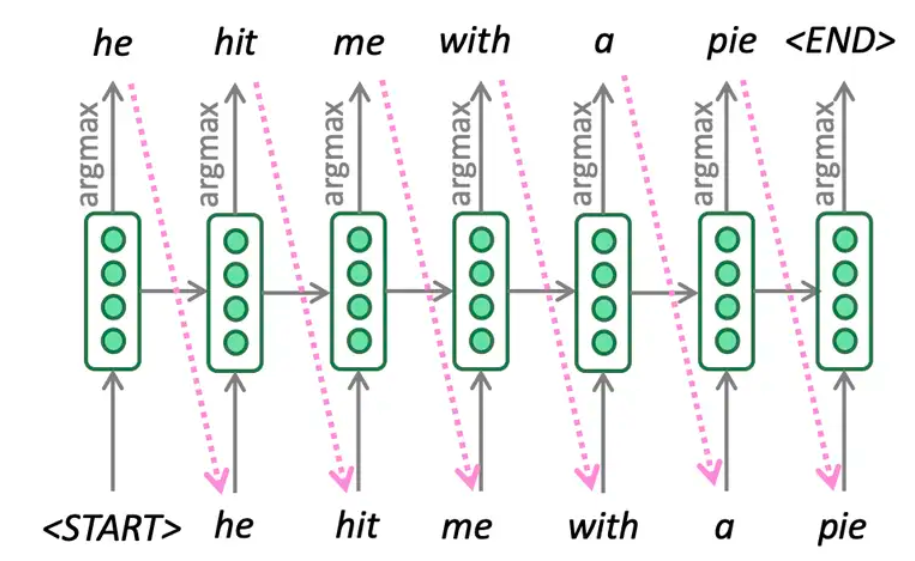
但是greedy decoding的问题是可能当前的最大概率的单词对于翻译整个句子来讲不一定是最优的选择,但由于每次我们都做greedy的选择我们没机会选择另一条整体最优的路径。
为解决这一问题,一个常用的方法是beam search decoding,也就是束搜索。
beam search其基本思想是在decoder的每一步,我们不仅仅是取概率最大的单词,而是保存k个当前最有可能的翻译假设,其中k称作beam size,通常在5到10之间。
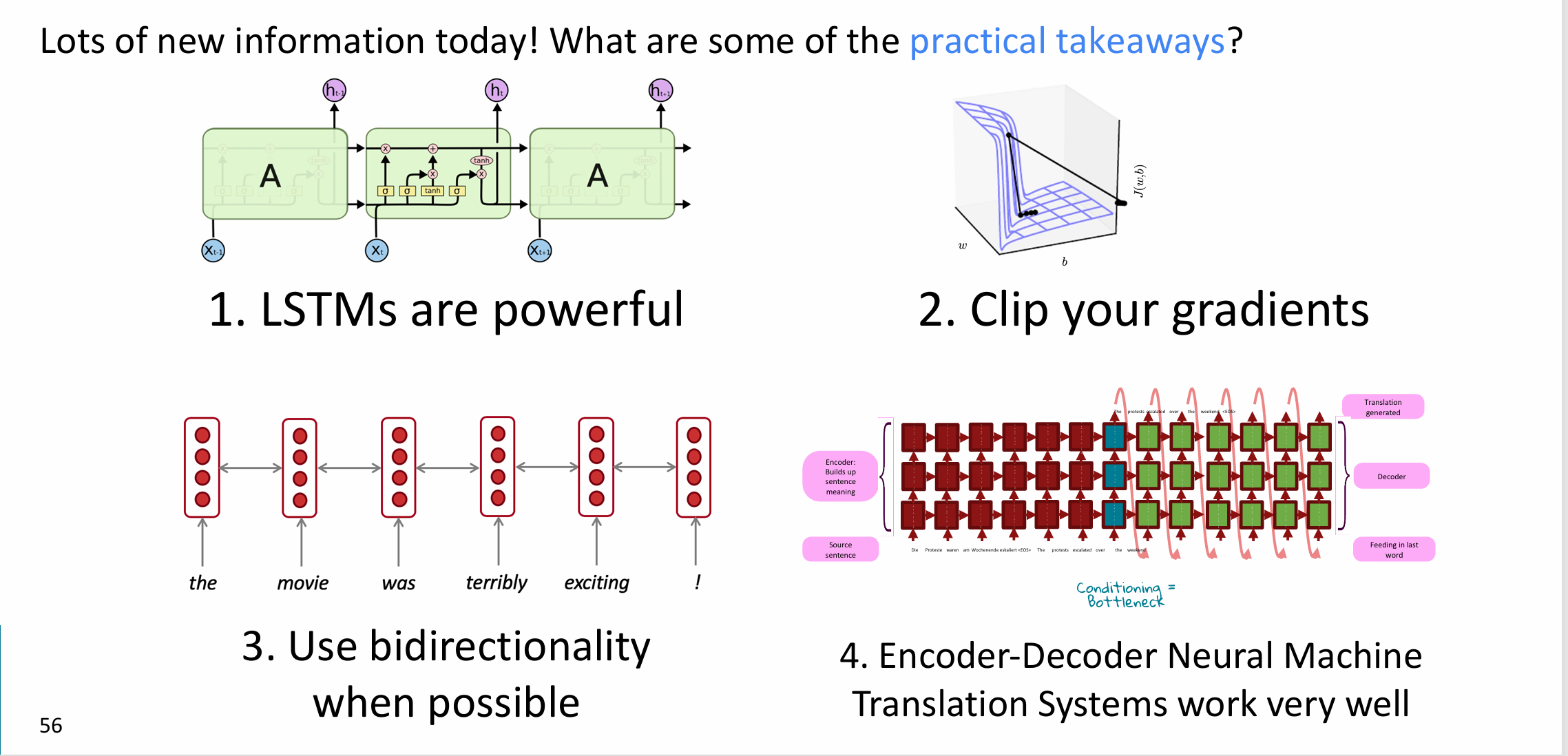
对本次的学习做个总结大概如下:
- 基础的lstm架构确实是对rnn的有力提升。
- 我们对梯度爆炸做的梯度裁剪的优化方法。
- 当我们能直接获取输入input的完整sequence的时候,完全可以考虑用双向的rnn,这样的左右信息就都有了,确实比单向的left-right信息要更全面。
- encoder-decoder的sequence-to-sequence架构很经典,也很好用(期待下面学习bert)
下面我们再去看看对于lstm的优化——GRU。参数会更少,更好训练模型,效果也不错。
参考
https://zhuanlan.zhihu.com/p/63557635
https://zhuanlan.zhihu.com/p/63397627
https://web.stanford.edu/class/cs224n/
