
B站教程
Linux高并发服务器开发
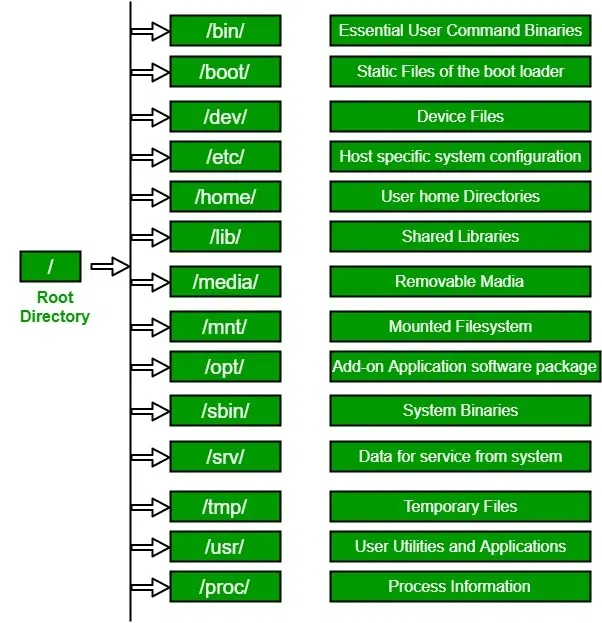
Linux常见目录介绍
参考链接:
Filesystem Hierarchy Standard - linuxfoundation
Linux File Hierarchy Structure - geeksforgeeks
不同的linux发行版都要遵守相同的FHS标准
This standard enables:
-
Software to predict the location of installed files and directories, and
-
Users to predict the location of installed files and directories.
file 命令
file + 文件 可以查看文件信息
管道
Piping in Unix or Linux - geeksforgeeks
pipe(2) — Linux manual page - man7
int
main(int argc, char *argv[])
{
int pipefd[2];
char buf;
pid_t cpid;
if (argc != 2) {
fprintf(stderr, "Usage: %s <string>\n", argv[0]);
exit(EXIT_FAILURE);
}
if (pipe(pipefd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0) { /* Child reads from pipe */
close(pipefd[1]); /* Close unused write end */
while (read(pipefd[0], &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
write(STDOUT_FILENO, "\n", 1);
close(pipefd[0]);
_exit(EXIT_SUCCESS);
} else { /* Parent writes argv[1] to pipe */
close(pipefd[0]); /* Close unused read end */
write(pipefd[1], argv[1], strlen(argv[1]));
close(pipefd[1]); /* Reader will see EOF */
wait(NULL); /* Wait for child */
exit(EXIT_SUCCESS);
}
}
gcc
-E:预处理。
预处理包括什么操作?
C++ 预处理器 - runoob
四个步骤:
预处理-编译-汇编-链接,分别在做什么?
静态链接-动态链接的区别?后缀是什么?
静态库的制作?
动态库的制作?
动态库加载失败如何解决?5种方法
进程的创建
进程可以使用fork()系统调用创建新的进程。调用fork()的进程称为父进程,
新创建的进程就是子进程。内核通过复制父进程来创建子进程。子进程获得父进
程的数据、堆栈、和堆的拷贝,并且随后可以进行修改,而不影响父进程。(程
序的文本,存放于只读内存区域,由父子进程共享)。
调用fork)后,子进程要么执行父进程代码中的另一组函数;或者更常见的
是使用execve()系统调用装载和执行一个全新的程序。execve(()系统调用销毁现有
的文本、数据、堆栈、和堆段,并根据新程序代码的新段进行替换。
有几个C库函数基于execve()系统调用实现,每个都提供稍微不同的接口,
但是功能是一样的。所有这些函数都以相同的exec 字符串开头,区别在哪里目
前并不重要,我们使用exec(来引用所有这些函数。不过要明确一点,Lnux中并
没有名为exec)的函数。
通常我们使用动词exec来描述execve()和相关库函数执行的操作。
mmap
是一个系统调用
mmap原理?
https://zhuanlan.zhihu.com/p/366964820
Linux页缓存、LinuxVFS中文件打开、读、写底层逻辑
为什么binder可以节省一次内存拷贝?
进程间通信的方式?
C库 IO函数的工作流程?
======== 小米面经
bios到kernel的启动过程,实模式和保护模式所做的操作,转换后mmu的作用
在计算机系统中,从 BIOS 到内核的启动过程涉及以下步骤:
BIOS 初始化:计算机开机时,首先执行 BIOS(Basic Input/Output System)中固化的程序。BIOS负责进行硬件的自检(POST,Power-On Self-Test)、初始化硬件设备和加载引导程序。
引导加载程序(Boot Loader):BIOS加载引导加载程序,如GRUB或LILO,位于启动设备的引导扇区(通常是硬盘的主引导记录)。引导加载程序负责加载操作系统内核到内存中。
内核启动:一旦引导加载程序将操作系统内核加载到内存中,控制权就交给了内核。内核开始执行并初始化操作系统的各个组件,如进程管理、内存管理、文件系统等。
接下来是实模式和保护模式的转换以及 MMU 的作用:
实模式:在实模式下,处理器可以访问整个 1MB 的物理内存空间,采用段地址和偏移地址的方式来寻址内存。实模式是早期 x86 处理器的工作模式,具有很多限制,如只能访问 1MB 内存、无法提供内存保护和多任务等功能。
保护模式:在保护模式下,处理器可以访问更大的内存空间,并提供了更多的功能和特性,如内存保护、虚拟内存、多任务等。在进入保护模式后,操作系统可以通过设置段描述符和页表来实现虚拟地址到物理地址的转换,并借助 MMU(Memory Management Unit)来管理内存的映射关系。
MMU 的作用:MMU 是内存管理单元,负责将逻辑地址(虚拟地址)转换为物理地址。在保护模式下,操作系统通过设置页表来告诉 MMU 如何将虚拟地址映射到物理地址。MMU还负责处理页面错误(Page Fault)、缓存(Cache)控制等功能,帮助操作系统有效地管理内存并提供内存保护机制。
如何进行虚拟内存管理
虚拟内存管理是操作系统中重要的功能,通过虚拟内存管理,操作系统可以为每个进程提供独立的地址空间,实现内存的隔离和保护。以下是虚拟内存管理的主要步骤:
地址空间划分:每个进程在运行时被分配一个独立的虚拟地址空间,通常是 0 到 4GB(32 位系统)或更大(64 位系统)。这个地址空间通常被划分为多个部分,如代码段、数据段、堆和栈等。
页面映射:虚拟内存管理通过将虚拟地址映射到物理地址来实现内存管理。操作系统将虚拟地址空间划分为固定大小的页面(通常是 4KB),并维护一个页表来记录虚拟页面和物理页面的映射关系。
页面置换:当物理内存不足时,操作系统需要进行页面置换来释放物理页面。常见的页面置换算法包括最近最少使用(LRU)、先进先出(FIFO)等。
页面访问权限:通过设置页表项的权限位,操作系统可以实现对内存的保护。例如,只读页面、读写页面等。
页面错误处理:当程序访问未映射的虚拟页面或者权限不足时,会触发页面错误中断。操作系统需要处理这些页面错误,可能会触发页面置换、加载数据等操作。
通过虚拟内存管理,操作系统可以为每个进程提供一个独立的地址空间,实现内存的隔离和保护,同时也能够更有效地利用物理内存资源。
内存管理粒度多大
内存管理的粒度通常是以页面(Page)为单位进行管理。在大多数操作系统中,页面的大小通常为 4KB。这意味着内存管理的基本单位是 4KB 的页面,操作系统在管理内存时将内存划分为多个页面,对每个页面进行管理和映射。
通过以页面为单位进行管理,操作系统可以更灵活地分配和管理内存,实现虚拟内存、内存保护和页面置换等功能。当程序访问内存时,操作系统会根据页面表将虚拟地址映射到物理地址的对应页面上,从而实现内存的有效管理和利用。
对进程进行内存分配和管理
对进程进行内存分配和管理是操作系统中重要的任务,以下是一般情况下对进程进行内存分配和管理的步骤:
-
进程地址空间分配:当操作系统创建一个新进程时,会为该进程分配独立的虚拟地址空间。这个地址空间通常包括代码段、数据段、堆和栈等部分。
-
堆和栈管理:
- 堆(Heap):用于动态分配内存,通常通过 malloc()、free() 等函数进行管理。操作系统需要跟踪堆中的空闲内存块,并根据请求进行分配和释放。
-
栈(Stack):用于存储函数调用和局部变量等信息。栈通常是固定大小的,操作系统会在进程创建时为其分配一定大小的栈空间。
-
页面分配:操作系统会将进程的虚拟地址空间划分为固定大小的页面(通常是 4KB),并通过页表来映射虚拟地址到物理地址。当进程访问未映射的页面时,操作系统会进行页面分配,并更新页表。
-
内存保护:操作系统通过设置页面的权限位来实现内存保护。例如,只读页面、读写页面等权限设置可以确保进程不会越界访问内存。
-
内存释放:当进程终止或释放内存时,操作系统需要回收进程所占用的内存。这包括释放堆中动态分配的内存、回收栈空间以及撤销虚拟地址到物理地址的映射等操作。
通过对进程进行内存分配和管理,操作系统可以确保各个进程之间的内存隔离和保护,同时也能够更有效地利用系统资源。
进程和线程有什么区别
进程(Process)和线程(Thread)是操作系统中的两个重要概念,它们之间有以下区别:
- 定义:
- 进程:进程是程序的一次执行过程,是操作系统中资源分配的基本单位。每个进程都有独立的地址空间,包括代码段、数据段、堆和栈等。
-
线程:线程是进程中的一个执行单元,一个进程可以包含多个线程。线程共享进程的地址空间和资源,包括代码段、数据段等,但拥有独立的栈空间。
-
资源开销:
- 进程:每个进程都有独立的地址空间和系统资源,创建和销毁进程需要较大的资源开销。
-
线程:线程共享进程的资源,创建和销毁线程的开销通常比创建和销毁进程小。
-
通信与同步:
- 进程:不同进程之间的通信需要额外的机制,如管道、消息队列、共享内存等。进程间通信较为复杂。
-
线程:线程之间共享同一地址空间,可以直接访问共享变量,因此线程间通信较为简单。
-
并发性:
- 进程:进程之间是独立的,各自拥有独立的地址空间,需要通过进程间通信来实现协作。
- 线程:线程共享进程的资源,可以更方便地实现并发操作和协作。
总的来说,进程是操作系统资源分配的基本单位,而线程是操作系统调度的基本单位。线程可以提高程序的并发性和响应速度,但也需要注意线程间的同步与通信。
webserver引入了多cpu,是如何进行调度
当一个 Web 服务器引入了多个 CPU 时,通常会采用多线程或多进程的方式来进行调度,以充分利用多个 CPU 的计算资源。以下是 Web 服务器在多 CPU 环境下可能采取的调度方式:
- 多进程模型:
- Web 服务器可以为每个 CPU 创建一个独立的进程,每个进程负责处理客户端请求。
- 每个进程都有自己的地址空间和资源,相互独立,可以并行地处理多个请求。
-
进程间通信可能会使用共享内存、消息队列等机制来实现数据传递和同步。
-
多线程模型:
- Web 服务器可以为每个 CPU 创建多个线程,每个线程负责处理一个客户端请求。
- 线程共享进程的地址空间和资源,可以更高效地实现并发处理。
-
线程之间可以直接访问共享数据,通过锁机制等来实现数据同步和互斥。
-
任务调度:
- 在多 CPU 环境下,Web 服务器需要进行合适的任务调度,以确保每个 CPU 的负载均衡。
-
可能会采用基于线程优先级、轮询、工作窃取等算法来进行任务调度,确保每个 CPU 能够充分利用。
-
负载均衡:
- 对于多 CPU 的 Web 服务器,还可以引入负载均衡机制,将请求分发到不同的 CPU 上处理,以提高整体性能和吞吐量。
- 负载均衡可以基于轮询、最少连接数、最短响应时间等策略来进行。
通过合理的多 CPU 调度和负载均衡机制,Web 服务器可以更好地利用多个 CPU 的计算资源,提高并发处理能力和性能。
使用的是时间片调度,你知道时间片是如何校准时间的吗
在时间片调度中,操作系统会将 CPU 时间划分为多个时间片(Time Slice),每个时间片表示一个小段时间,用来分配给每个进程或线程执行。当一个进程或线程的时间片用尽时,操作系统会进行上下文切换,将 CPU 分配给下一个就绪的进程或线程。
时间片的校准通常是由操作系统内部的时钟中断(Timer Interrupt)来实现的。操作系统会设置一个硬件定时器,在每个时间片结束时触发时钟中断,通知操作系统进行调度。
具体来说,操作系统在启动时会初始化硬件定时器,并设置定时器的计数值,该计数值表示一个时间片的时长。当定时器倒计时至零时,会触发时钟中断,操作系统会捕获这个中断,并进行相应的处理,如进行进程调度。
通过时钟中断和硬件定时器,操作系统可以实现时间片调度,确保每个进程或线程都能获得公平的 CPU 时间,并避免某个进程或线程长时间占用 CPU 而导致其他进程无法执行的情况。
解释一下cfs
CFS 是 Linux 内核中的一种调度算法,全称为 Completely Fair Scheduler,即完全公平调度器。CFS 旨在提供公平的 CPU 时间分配,确保每个任务都能获得公平的 CPU 时间片,避免某些任务长时间占用 CPU 而导致其他任务无法得到执行的情况。
以下是 CFS 的一些特点和工作原理:
-
公平性:CFS 设计的目标是实现完全公平的调度,即每个任务在相同时间内都能获得相等的 CPU 时间。这样可以确保所有任务都有公平的执行机会。
-
虚拟时钟:CFS 使用了一种称为“虚拟时钟”的概念来衡量任务的执行时间。每个任务都有一个虚拟运行时间(virtual runtime),该虚拟运行时间表示任务已经消耗的 CPU 时间。CFS 根据虚拟运行时间来进行调度决策。
-
调度策略:CFS 会选择具有最小虚拟运行时间的任务来运行,以确保每个任务都能获得公平的 CPU 时间。当一个任务执行时,其虚拟运行时间会不断增加,直到达到其他任务的水平为止。
-
负载均衡:CFS 还包括负载均衡机制,可以在多个 CPU 上均衡地分配任务,以提高系统整体的性能和公平性。
总的来说,CFS 是一种注重公平性的调度算法,通过虚拟时钟和公平性原则来确保每个任务都能获得公平的 CPU 时间,避免出现某些任务长时间占用 CPU 而影响其他任务执行的情况。
linux中是如何对进程进行管理调度的
在 Linux 中,进程管理和调度是通过内核的调度器(Scheduler)来实现的。Linux 内核采用多级反馈队列调度算法(Multilevel Feedback Queue),通过时间片轮转和优先级调度来管理和调度进程。以下是 Linux 中对进程进行管理和调度的主要步骤:
-
进程创建:当用户程序或系统服务需要创建新进程时,通过系统调用(如fork()、exec())向内核发出请求,内核会为新进程分配资源,包括地址空间、文件描述符等。
-
进程状态:Linux 中的进程状态包括运行(Running)、就绪(Ready)、阻塞(Blocked)等。内核会根据进程的状态来进行调度和管理。
-
调度器:Linux 内核中的调度器负责决定哪个进程可以获得 CPU 时间。通过多级反馈队列调度算法,内核将进程按照优先级和时间片分配到不同的队列中,并根据优先级和时间片来进行调度。
-
时间片轮转:Linux 中采用时间片轮转的方式来分配 CPU 时间给就绪队列中的进程。每个进程在运行时会被分配一个时间片,当时间片用尽时,内核会将其放回队列末尾,切换到下一个就绪进程执行。
-
优先级调度:Linux 调度器会根据进程的优先级来决定执行顺序。较高优先级的进程会先被执行,以确保重要任务能够及时得到处理。
-
负载均衡:Linux 内核还包括负载均衡机制,可以在多个 CPU 上均衡地分配任务,以提高系统整体的性能和公平性。
通过以上步骤,Linux 内核能够有效地管理和调度进程,确保系统资源得到合理分配,并实现多任务并发执行。
操作系统中文件系统的管理是如何实现的
操作系统中文件系统的管理是通过文件系统模块来实现的,文件系统模块负责管理存储设备上的文件和目录结构,提供对文件的创建、读取、写入、删除等操作。以下是文件系统管理的一般实现方式:
-
文件和目录结构:文件系统通过数据结构(如索引节点 inode)来表示文件和目录的属性,如文件大小、权限、创建时间等信息。目录结构通常采用树形结构,用于组织和管理文件。
-
数据存储:文件系统将文件数据存储在存储设备(如硬盘)上,通常采用块(Block)为单位进行存储。文件系统负责将文件数据存储在适当的块中,并维护文件和块之间的映射关系。
-
文件操作:文件系统提供了一系列系统调用(如open、read、write、close)来对文件进行操作。这些系统调用通过文件系统模块来实现对文件的读写等操作。
-
磁盘空间管理:文件系统需要管理磁盘空间的分配和释放,确保文件数据能够被正确存储和访问。这包括空闲块的管理、块的分配和释放等操作。
-
缓存机制:为了提高性能,文件系统通常会引入缓存机制,将频繁访问的数据缓存在内存中,减少对磁盘的访问次数。
-
一致性和恢复:文件系统需要确保在意外断电或系统崩溃等情况下能够保持数据一致性。因此,文件系统通常会实现日志(Journaling)机制来记录对磁盘的操作,以便在恢复时进行数据一致性检查和修复。
通过以上方式,操作系统中的文件系统模块实现了对文件和目录的管理,提供了对存储设备上数据的有效组织和访问。
解释一下fork,哪里应该使用cow,如何实现cow
在操作系统中,fork() 是一个系统调用,用于创建一个新的进程,新进程是原进程的副本。fork() 系统调用会创建一个新的进程(子进程),并将父进程的地址空间复制到子进程中。以下是关于 fork() 和 COW(Copy-On-Write)的解释:
- fork() 系统调用:
- 当调用
fork()时,操作系统会复制父进程的地址空间(包括代码段、数据段、堆、栈等)到子进程中。 -
子进程是父进程的副本,但是子进程和父进程是独立的,它们有各自独立的地址空间。
-
COW(Copy-On-Write):
- COW 是一种内存管理技术,用于延迟内存复制操作。在
fork()中,通常不立即复制父进程的整个地址空间到子进程中,而是采用 COW 机制。 -
当父子进程中的某个进程尝试修改共享的内存页时,操作系统会将这个页复制一份,然后再进行修改。这样可以节省内存和时间开销。
-
应用场景:
-
COW 适用于父子进程共享大部分内存但只有少量修改的情况。如果父子进程之间几乎不进行内存修改,使用 COW 可以减少内存复制的开销。
-
实现 COW:
- 实现 COW 的关键在于利用页面表的写保护机制。当父子进程共享同一物理页面时,页面表项会被设置为只读。当某个进程尝试修改这个页面时,会触发页面错误中断。
- 在页面错误处理中,操作系统会为该进程分配一个新的物理页面,并将原来的页面内容复制到新页面中。然后更新页面表项,使该进程可以继续修改这个页面。
通过使用 COW 技术,操作系统可以在 fork() 过程中延迟内存复制操作,提高性能和节省内存开销。
如何做的dma
DMA(Direct Memory Access,直接内存访问)是计算机技术中常用的一种数据传输方式,它可以在不需要处理器干预的情况下,直接在设备和内存之间传输数据。要实现DMA,通常需要硬件支持,包括DMA控制器和相关的寄存器。
实现DMA的一般步骤如下:
1. 配置DMA控制器:首先需要配置DMA控制器的寄存器,包括源地址、目的地址、数据传输长度等参数。
2. 启动DMA传输:配置好寄存器后,启动DMA传输,让DMA控制器开始数据传输操作。
3. 数据传输:DMA控制器会根据配置的参数自动进行数据传输,直到传输完成。
4. 中断处理:在数据传输完成后,DMA控制器通常会产生一个中断信号,处理器可以通过中断处理程序来处理这个中断,进行后续操作。
总的来说,实现DMA需要硬件支持和相关的编程技巧,具体的实现方式会根据不同的硬件平台和操作系统有所差异。
thread和pthread的区别。
thread 和 pthread 都与线程相关,但是它们之间有一些区别:
-
thread是一个通用的术语,可以指代操作系统中的线程(thread)或者程序中的线程(thread of execution),它是一个执行流的最小单元,用于并发执行程序代码。 -
pthread是 POSIX 线程库的缩写,是一套线程操作的 API 规范,定义了创建、同步、销毁线程等操作的接口。在使用 POSIX 线程库时,我们会使用pthread相关的函数来操作线程。 -
在具体实现上,
pthread是一种线程库的实现,提供了一套标准的接口,可以在遵循 POSIX 标准的操作系统上使用。而thread可能指代更广泛的概念,包括不同操作系统或编程语言中的线程实现。
总的来说,thread 是一个更通用的术语,而 pthread 是特指 POSIX 线程库的接口规范和实现。
linux如何查看进程的情况。
在Linux系统中,可以使用以下命令来查看进程的情况:
ps命令:可以显示当前用户的进程状态。ps:显示当前终端下的进程信息。ps aux或ps -aux:显示系统中所有进程的详细信息。-
ps -ef:显示所有进程的完整信息。 -
top命令:实时显示进程的动态信息,包括 CPU 占用率、内存占用等。 -
直接在终端输入
top命令即可查看进程的动态信息。 -
htop命令:类似于top命令,但提供了更加直观的界面和操作方式。 -
首先需要安装
htop,然后在终端输入htop命令即可查看进程的情况。 -
pgrep和pkill命令:可以通过进程名来查找和结束进程。 pgrep <process_name>:查找指定名称的进程ID。pkill <process_name>:结束指定名称的进程。
通过以上命令,你可以查看并管理Linux系统中运行的进程情况。
top命令可以如何使用。
在Linux系统中,top 命令是一个非常有用的工具,用于实时显示系统中运行的进程的动态信息。以下是使用 top 命令的一些常见操作:
-
打开
top:在终端中直接输入top命令并按回车键,即可打开top工具,开始实时显示进程信息。 -
退出
top:按下键盘上的q键即可退出top工具。 -
刷新频率:默认情况下,
top每隔 3 秒刷新一次进程信息。可以在top运行时按下d键来更改刷新频率,然后输入想要的秒数并按回车键。 -
排序:在
top运行时可以按下不同的键来对显示的进程进行排序。例如: - 按下
P键按照 CPU 使用率排序。 - 按下
M键按照内存使用排序。 -
按下
T键按照运行时间排序。 -
过滤:在
top运行时可以按下o键(小写字母 o)来进行过滤,然后输入想要过滤的条件,如进程名等,按回车键即可实现过滤显示。 -
显示帮助:在
top运行时可以按下h键来查看帮助信息,了解更多快捷键操作。
通过上述操作,你可以充分利用 top 命令来实时监控和管理系统中运行的进程情况。
讲一下static
在 C++ 中,static 是一个关键字,具有多种用途,主要包括以下几个方面:
- 静态变量(Static Variables):
- 在函数内部声明的静态变量:静态变量在程序运行期间只会被初始化一次,即使函数被多次调用也不会重新初始化。
-
在类中声明的静态成员变量:静态成员变量是属于类的,而不是属于类的实例。所有类的实例共享同一个静态成员变量。
-
静态函数(Static Functions):
-
在类中声明的静态成员函数:静态成员函数不属于任何类的实例,可以直接通过类名调用,而不需要创建类的实例。
-
静态成员变量的初始化:
-
静态成员变量需要在类外部进行初始化,通常在类的实现文件中进行。
-
静态局部变量:
-
在函数内部声明的静态局部变量在程序运行期间只会被初始化一次,即使函数被多次调用也不会重新初始化。
-
静态断言(Static Assert):
- 使用
static_assert关键字可以在编译期间进行断言检查,如果条件不满足会在编译时产生错误。
总的来说,static 在 C++ 中具有不同的用途,可以用于定义静态变量、静态函数、静态成员变量等,帮助我们实现程序逻辑和控制。
讲一下c++内存分布
在C++程序中,内存分布通常可以分为以下几个部分:
- 栈(Stack):
- 栈用于存储函数的参数值、局部变量以及函数调用的返回地址。
-
栈是一种先进后出的数据结构,每次函数调用时会在栈上分配一段内存,函数返回时释放这段内存。
-
堆(Heap):
- 堆是用于动态内存分配的区域,程序员可以在堆上手动分配和释放内存。
-
堆上的内存需要程序员手动管理,包括分配(如
new操作符)和释放(如delete操作符)。 -
全局/静态区(Global/Static Area):
- 全局变量和静态变量存储在全局/静态区,程序启动时分配内存,程序结束时释放内存。
-
全局变量在整个程序运行期间都存在,静态变量在声明周期内存在。
-
常量区(Constant Area):
- 存储常量字符串等常量数据,通常不允许修改。
-
常量区的数据在程序运行期间不会改变。
-
代码区(Code Area):
- 存储程序的机器指令,即代码段。
- 代码区通常是只读的,存储程序的执行代码。
总的来说,C++程序的内存分布包括栈、堆、全局/静态区、常量区和代码区,每个区域具有不同的特性和用途。合理地管理这些内存区域可以提高程序的性能和稳定性。
socket与其他通信方式有什么不同
在Linux进程间通信方面,socket是一种常用的通信方式,但与其他通信方式(如管道、消息队列、共享内存等)有一些不同之处:
跨网络通信:Socket通信可以用于不同主机之间的通信,支持跨网络通信;而其他通信方式通常局限于同一台计算机上的进程间通信。
面向网络:Socket通信是面向网络的,可以通过网络套接字进行通信;而其他通信方式主要用于本地进程间通信。
灵活性:Socket通信提供了丰富的API和功能,可以支持多种协议(如TCP、UDP等)和通信方式;而其他通信方式可能比较特定和受限。
总的来说,Socket在Linux进程间通信中具有更广泛的应用范围和更灵活的特性,适用于本地和网络通信。
共享内存安全吗,有什么措施保证
共享内存在Linux进程间通信中是一种高效的通信方式,但由于多个进程可以同时访问共享内存区域,存在一些安全性和同步性的考虑。共享内存本身并不提供内建的安全机制,因此需要进程自行实现措施来保证共享内存的安全性。以下是一些措施来确保共享内存的安全性:
-
互斥锁(Mutex):通过使用互斥锁来控制对共享内存的访问,确保在同一时间只有一个进程可以对共享内存进行读写操作,避免数据竞争和冲突。
-
信号量(Semaphore):使用信号量来实现对共享资源的访问控制,可以限制同时访问共享内存的进程数量,确保数据的一致性和完整性。
-
条件变量(Condition Variable):结合互斥锁和条件变量来实现进程间的同步和通信,确保在适当的时候进行等待和唤醒操作,避免竞争条件的发生。
-
读写锁(Read-Write Lock):对于读写操作频繁的共享内存区域,可以使用读写锁来实现读者-写者问题的解决,提高并发性能。
-
错误处理:在访问共享内存时要考虑错误处理机制,及时处理可能出现的异常情况,避免数据损坏或系统崩溃。
通过以上措施的应用,可以有效提高共享内存的安全性和稳定性,确保多个进程之间能够安全地进行数据共享和通信。
linux中内存分布有哪些,cpp呢
在Linux系统中,内存分布主要包括以下几个部分:
-
内核空间(Kernel Space):用于运行操作系统内核的内存区域,只有内核可以访问。
-
用户空间(User Space):用于运行用户进程的内存区域,用户进程可以访问。
-
共享内存(Shared Memory):允许多个进程共享同一块物理内存区域,用于进程间通信。
-
堆(Heap):用于动态分配内存,由程序员控制内存的分配和释放。
-
栈(Stack):用于存储函数调用、局部变量等信息,具有后进先出的特性。
在C++中,内存分布也可以按照以下方式来划分:
-
栈(Stack):用于存储函数的局部变量、函数参数等,在函数调用时分配,在函数返回时释放。
-
堆(Heap):用于动态分配内存,需要程序员手动管理内存的分配和释放。
-
全局/静态存储区(Global/Static Storage Area):用于存储全局变量、静态变量等,程序运行期间始终存在。
-
常量区(Constant Area):用于存储常量变量,如字符串常量等。
-
代码区(Code Area):用于存储程序的代码段。
这些内存分布在Linux系统和C++编程中扮演着重要的角色,对程序的性能和稳定性有着重要的影响。
多态实现方式
在 C++ 中,多态性通常通过虚函数(virtual functions)和继承来实现。当基类(父类)中的成员函数被声明为虚函数时,它们可以在派生类(子类)中被重写,从而实现多态性。
模板也可以被看作是一种多态性的实现方式。在 C++ 中,模板提供了一种参数化类型的方式,使得代码可以在编译时生成不同类型的实例。这种编译时多态性被称为模板多态性(template polymorphism)。
通过模板,我们可以编写通用的代码,而不需要针对每种具体类型都编写一份代码。当使用模板时,编译器会根据实际使用的类型生成对应的代码,从而实现了多态性。
cpp面向对象的优势
C++ 中面向对象编程的优势包括但不限于以下几点:
-
封装(Encapsulation):面向对象编程允许将数据(属性)和行为(方法)封装在一个对象中,通过访问控制符(public、private、protected)来限制对对象内部数据的访问。这样可以提高代码的安全性和可维护性,同时隐藏对象的内部实现细节。
-
继承(Inheritance):继承允许创建一个新类(子类)从现有类(父类)继承属性和行为,从而实现代码的重用和扩展。通过继承,可以建立类之间的层次关系,提高代码的组织性和可扩展性。
-
多态(Polymorphism):多态性允许不同类的对象对同一消息做出不同的响应。通过虚函数和函数重写,可以实现运行时多态性,使得程序能够根据对象的实际类型来调用相应的方法,提高代码的灵活性和可扩展性。
-
抽象(Abstraction):面向对象编程提供了抽象机制,可以将对象的共同特征抽象成接口、抽象类等,隐藏对象的具体实现细节。通过抽象,可以简化复杂系统的设计,提高代码的可读性和可维护性。
-
代码复用(Code Reusability):面向对象编程通过封装、继承和多态等特性,促进了代码的重用。可以通过继承现有类、实现接口等方式来重用已有代码,减少重复编写代码的工作量,提高开发效率。
总的来说,面向对象编程能够提高代码的可读性、可维护性和可扩展性,使得软件开发更加模块化、灵活和高效。
